ScyllaDB powers real-time AI with low latency, high throughput, and billion-scale data.
Learn More



What is DynamoDB?
Amazon DynamoDB is a cloud-native NoSQL primarily key-value database. Let’s define each of those terms.
- DynamoDB is cloud-native in that it does not run on-premises or even in a hybrid cloud; it only runs on Amazon Web Services (AWS). This enables it to scale as needed without requiring a customer’s capital investment in hardware. It also has attributes common to other cloud-native applications, such as elastic infrastructure deployment (meaning that AWS will provision more servers in the background as you request additional capacity).
- DynamoDB is NoSQL in that it does not support ANSI Structured Query Language (SQL). Instead, it uses a proprietary API based on JavaScript Object Notation (JSON). This API is generally not called directly by user developers, but invoked through AWS Software Developer Kits (SDKs) for DynamoDB written in various programming languages (C++, Go, Java, JavaScript, Microsoft .NET, Node.js, PHP, Python and Ruby).
- DynamoDB is primarily a key-value store in the sense that its data model consists of key-value pairs in a schemaless, very large, non-relational table of rows (records). It does not support relational database management systems (RDBMS) methods to join tables through foreign keys. It can also support a document store data model using JavaScript Object Notation (JSON).
DynamoDB’s NoSQL design is oriented towards simplicity and scalability, which appeal to developers and devops teams respectively. It can be used for a wide variety of semistructured data-driven applications prevalent in modern and emerging use cases beyond traditional databases, from the Internet of Things (IoT) to social apps or massive multiplayer games. With its broad programming language support, it is easy for developers to get started and to create very sophisticated applications using DynamoDB.
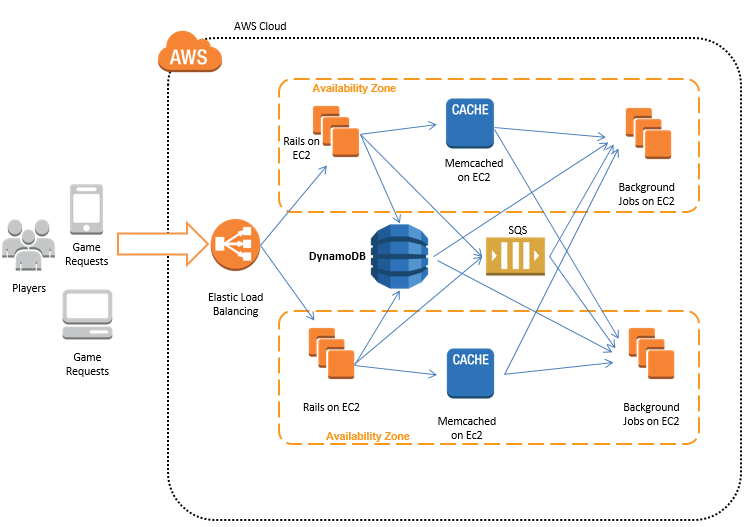
What is a DynamoDB Database?
Outside of Amazon employees, the world doesn’t know much about the exact nature of this database. There is a development version known as DynamoDB Local used to run on developer laptops written in Java, but the cloud-native database architecture is proprietary closed-source.
While we cannot describe exactly what DynamoDB is, we can describe how you interact with it. When you set up DynamoDB on AWS, you do not provision specific servers or allocate set amounts of disk. Instead, you provision throughput — you define the database based on provisioned capacity — how many transactions and how many kilobytes of traffic you wish to support per second. Users specify a service level of read capacity units (RCUs) and write capacity units (WCUs).
As stated above, users generally do not directly make DynamoDB API calls. Instead, they will integrate an AWS SDK into their application, which will handle the back-end communications with the server.
DynamoDB data modeling needs to be denormalized. For developers used to working with both SQL and NoSQL databases, the process of rethinking their data model is nontrivial, but also not insurmountable.
History of the Amazon DynamoDB Database
DynamoDB was inspired by the seminal Dynamo white paper (2007) written by a team of Amazon developers. This white paper cited and contrasted itself from Google’s Bigtable (2006) paper published the year before.
The original Dynamo database was used internally at Amazon as a completely in-house, proprietary solution. It is a completely different customer-oriented Database as a Service (DBaaS) that runs on Amazon Web Services (AWS) Elastic Compute Cloud (EC2) instances. DynamoDB was released in 2012, five years after the original white paper that inspired it.
While DynamoDB was inspired by the original paper, it was not beholden to it. Many things had changed in the world of Big Data over the intervening years since the paper was published. It was designed to build on top of a “core set of strong distributed systems principles resulting in an ultra-scalable and highly reliable database system.”
DynamoDB Release History
Since its initial release, Amazon has continued to expand on the DynamoDB API, extending its capabilities. DynamoDB documentation includes a document history as part of the DynamoDB Developer Guide to track key milestones in DynamoDB’s release history:
Looking at your existing list, the pattern is clear: one entry per significant capability, not per SDK update or regional expansion. From the 2025–2026 announcements, the major capabilities that fit that bar are:
– Configurable PITR recovery period
– Multi-Region strong consistency for global tables (GA)
– Multi-attribute composite keys in GSIs
– Zero-ETL integration with SageMaker Lakehouse
– Cross-account global table replication
– ExtendDB open source adapter
Here’s the full updated list:
—
Jan 2012 — Initial release of DynamoDB
Aug 2012 — Binary data type support
Apr 2013 — New API version, local secondary indexes
Dec 2013 — Global secondary indexes
Apr 2014 — Query filter, improved conditional expressions
Oct 2014 — Larger item sizes, flexible scaling, JSON document model
Apr 2015 — New comparison functions for conditional writes, improved query expressions
Jul 2015 — Scan with strongly-consistent reads, streams, cross-region replication
Feb 2017 — Time-to-Live (TTL) automatic expiration
Apr 2017 — DynamoDB Accelerator (DAX) cache
Jun 2017 — Automatic scaling
Aug 2017 — Virtual Private Cluster (VPC) endpoints
Nov 2017 — Global tables, backup and restore
Feb 2018 — Encryption at rest
Apr 2018 — Continuous backups and Point-in-Time Recovery (PITR)
Nov 2018 — Encryption at rest, transactions, on-demand billing
Feb 2019 — DynamoDB Local (downloadable version for developers)
Aug 2019 — NoSQL Workbench preview
Nov 2019 — PartiQL support – SQL-compatible query language for DynamoDB
May 2020 — NoSQL Workbench general availability
Jul 2020 — Contributor Insights for monitoring hot keys and usage patterns
Nov 2020 — Export to S3 feature for full table exports
Apr 2021 — Increased table limits and improved replica auto-scaling
Jul 2021 — Scheduled automatic backups
Dec 2021 — Standard-Infrequent Access (Standard-IA) table class
Mar 2022 — Increased maximum item size to 400KB
Sep 2022 — Zero-ETL integration with Amazon OpenSearch Service
Apr 2023 — Import from S3 feature
Sep 2023 — Verified Access integration for enhanced security
Nov 2023 — Multi-Region Key-Value API for simplified global tables
Feb 2024 — Enhanced CloudWatch integration for monitoring
Jan 2025 — Configurable PITR recovery period (1–35 days per table)
Jun 2025 — Multi-Region strong consistency (MRSC) for global tables, zero RPO
Nov 2025 — Multi-attribute composite keys in GSIs (up to four attributes per key component)
Dec 2025 — Zero-ETL integration with Amazon SageMaker Lakehouse
Feb 2026 — Cross-account replication for global tables
May 2026 — ExtendDB open source DynamoDB-compatible adapter with pluggable storage backends
DynamoDB Database Overview
DynamoDB Design Principles
As stated in Werner Vogel’s initial blog about DynamoDB, the database was designed to build on top of a “core set of strong distributed systems principles resulting in an ultra-scalable and highly reliable database system.” It needed to provide these attributes:
- Managed — provided ‘as-a-Service’ so users would not need to maintain the database
- Scalable — automatically provision hardware on the backend, invisible to the user
- Fast — support predictive levels of provisioned throughput at relatively low latencies
- Durable and highly available — multiple availability zones for failures/disaster recovery
- Flexible — make it easy for users to get started and continuously evolve their database
- Low cost — be affordable for users as they start and as they grow
The database needed to “provide fast performance at any scale,” allowing developers to “start small with just the capacity they need and then increase the request capacity of a given table as their app grows in popularity.” Predictable performance was ensured by provisioning the database with guarantees of throughput, measured in “capacity units” of reads and writes. “Fast” was defined as single-digit milliseconds, based on data stored in Solid State Drives (SSDs).
It was also designed based on lessons learned from the original Dynamo, SimpleDB and other Amazon offerings, “to reduce the operational complexity of running large database systems.” Developers wanted a database that “freed them from the burden of managing databases and allowed them to focus on their applications.” Based on Amazon’s experience with SimpleDB, they knew that developers wanted a database that “just works.” By its design users no longer were responsible for provisioning hardware, installing operating systems, applications, containers, or any of the typical devops tasks for on-premises deployments. On the back end, DynamoDB “automatically spreads the data and traffic for a table over a sufficient number of servers to meet the request capacity specified by the customer.” Furthermore, DynamoDB would replicate data across multiple AWS Availability Zones to provide high availability and durability.
As a commercial managed service, Amazon also wanted to provide a system that would make it transparent for customers to predict their operational costs.
DynamoDB Data Storage Format
To manage data, DynamoDB uses hashing and b-trees. While DynamoDB supports JSON, it only uses it as a transport format; JSON is not used as a storage format. Much of the exact implementation of DynamoDB’s data storage format remains proprietary. Generally a user would not need to know about it. Data in DynamoDB is generally exported through streaming technologies or bulk downloaded into CSV files through ETL-type tools like AWS Glue. As a managed service, the exact nature of data on disk, much like the rest of the system specification (hardware, operating system, etc.), remains hidden from end users of DynamoDB.
DynamoDB Query Operations
Unlike Structured Query Language (SQL), DynamoDB queries use a Javascript Object Notation (JSON) format to structure its queries. For example, as seen on this page), if you had the following SQL query:
SELECT * FROM Orders
INNER JOIN Order_Items ON Orders.Order_ID = Order_Items.Order_ID
INNER JOIN Products ON Products.Product_ID = Order_Items.Product_ID
INNER JOIN Inventories ON Products.Product_ID = Inventories.Product_ID
ORDER BY Quantity_on_Hand DESCIn DynamoDB you would redesign the data model so that everything was in a single table, denormalized, and without JOINs. This leads to the lack of deduplication you get with a normalized database, but it also makes a far simpler query. For example, the equivalent of the above in a DynamoDB query could be rendered as simply as:
SELECT * FROM Table_X WHERE Attribute_Y = "somevalue"It is important to remember that DynamoDB does not use SQL at all. Nor does it use the NoSQL equivalent made popular by Apache Cassandra, Cassandra Query Language (CQL). Instead, it uses JSON to encapsulate queries.
{
TableName: "Table_X"
KeyConditionExpression: "LastName = :a",
ExpressionAttributeValues: {
:a = "smith"
}
}However, just because DynamoDB keeps data in a single denormalized table doesn’t mean that it is simplistic. Just as in SQL, DynamoDB queries can get very complex. This example provided by Amazon shows just how complex a JSON request can get, including data types, conditions, expressions, filters, consistency levels and comparison operators.
NoSQL Data Models
Amazon DynamoDB uses a a key-value NoSQL data model in which data is stored as items identified by a primary key. The primary key is either a single partition key or a composite of partition key and sort key. The partition key is hashed to determine the item’s storage partition; when present, the sort key defines ordering and supports range queries within that partition. Reads and writes are key-addressed operations, providing direct access to individual items without scanning. Beyond the key, each item consists of arbitrary attribute name–value pairs, and the service does not enforce a fixed schema.
Databases like ScyllaDB provide DynamoDB-compatible APIs that support DynamoDB data models without refactoring. These are commonly used when teams need to reduce DynamoDB costs or run DynamoDB workloads beyond AWS (e.g., other clouds or on-prem).
Additional NoSQL Data Models
DynamoDB models data in JSON format, allowing it to serve in document use cases. Amazon recommends using its Amazon Document DB, which is designed-for-purpose as a document store, and is also compatible with the widely-adopted MongoDB API. For example, DynamoDB doesn’t store data internally as JSON. It only uses JSON as a transport method.
The database also supports wide column data models when it acts as an underlying data storage model in its serverless Managed Cassandra Service. However, in this mode users call the database using the Cassandra Query Language (CQL) just as they would with any native Apache Cassandra database. Users cannot make any DynamoDB API calls to the underlying database. You can read a further analysis of this service in this blog.
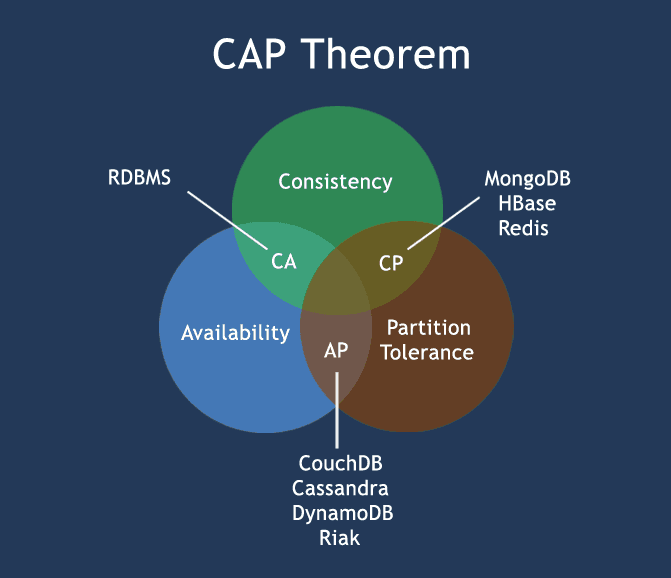
DynamoDB and the CAP Theorem
The CAP Theorem (as put forth in a presentation by Eric Brewer in 2000) stated that distributed shared-data systems had three properties but systems could only choose to adhere to two of those properties:
- Consistency
- Availability
- Partition-tolerance
Distributed systems designed for fault tolerance are not much use if they cannot operate in a partitioned state (a state where one or more nodes are unreachable). Thus, partition-tolerance is always a requirement, so the two basic modes that most systems use are either Availability-Partition-tolerant (“AP”) or Consistency-Partition-tolerant (“CP”).
An “AP”-oriented database remains available even if it was partitioned in some way. For instance, if one or more nodes went down, or two or more parts of the cluster were separated by a network outage (a so-called “split-brain” situation), the remaining database nodes would remain available and continue to respond to requests for data (reads) or even accept new data (writes). However, its data would become inconsistent across the cluster during the partitioned state. Transactions (reads and writes) in an “AP”-mode database are considered to be “eventually consistent” because they are allowed to write to some portion of nodes; inconsistencies across nodes are settled over time using various anti-entropy methods.
A “CP”-oriented database would instead err on the side of consistency in the case of a partition, even if it meant that the database became unavailable in order to maintain its consistency. For example, a database for a bank might disallow transactions to prevent it from becoming inconsistent and allowing withdrawals of more money than were actually available in an account. Transactions on such systems are referred to as “strongly consistent” because all nodes on a system need to reflect the change before the transaction is considered complete or successful.
It was initially designed to operate primarily as an “AP”-mode database. However later Amazon introduced DynamoDB Transactions to allow the database to act in a manner similar to a “CP”-mode database. These sorts of transactions are important to perform conditional updates — for example, ensuring a record meets a certain condition before setting it to a new value. (Such as having sufficient money in an account before making a withdrawal.) If the condition is not met, then the transaction does not proceed. This type of transaction requires a read-before-write (to check for existing values), and also a subsequent check to ensure the update went through properly. While providing this level of “all-or-nothing” operational guarantee transaction performance will naturally be slower, and may in fact fail at times. For example, users may notice DynamoDB system errors such as returning HTTP 500 server errors.
DynamoDB, ACID and BASE
An ACID database is a database that provides the following properties:
- Atomicity
- Consistency
- Isolation
- Durability
DynamoDB, when using DynamoDB Transactions, displays ACID properties.
However, without the use of transactions, DynamoDB is usually considered to display BASE properties:
- Basically Available
- Soft-state
- Eventually consistent
DynamoDB Scalability and High Availability
DynamoDB scalability includes methods such as autosharding and load-balancing. Autosharding means that when load on a single Amazon server gets to a certain point, the database can select a certain amount of records and place that data on a new node. Traffic between the new and existing servers is load-balanced so that, ideally, no one node is impacted with more traffic than others. However, the exact methods of how the database supports autosharding and load-balancing are proprietary, part of its internal operational mechanics, and are not visible to nor controllable by users.
Amazon DynamoDB Data Modeling
As mentioned before, DynamoDB is a key-value store database that uses a documented-oriented JSON data model. Data is indexed using a primary key composed of a partition key and a sort key. There is no set schema to data in the same table; each partition can be very different from others. Unlike traditional SQL systems where data models can be created long before needing to know how the data will be analyzed, with DynamoDB, like many other NoSQL databases, data should be modeled based on the types of queries you seek to run.
DynamoDB Architecture for Data Distribution
Amazon Web Services (AWS) guarantees that DynamoDB tables span Availability Zones. You can also distribute your data across multiple regions in the database global tables to provide greater resiliency in case of a disaster. However, with global tables you need to keep your data eventually consistent.
When to Use DynamoDB
Amazon DynamoDB is most useful when you need to rapidly prototype and deploy a key-value store database that can seamlessly scale to multiple gigabytes or terabytes of information — what are often referred to as “data-intensive” applications. Because of its emphasis on scalability and high availability DynamoDB is also appropriate for “always on” use cases with high volume transactional requests (reads and writes).
DynamoDB is inappropriate for extremely large data sets (petabytes) with high frequency transactions where the cost of operating DynamoDB may make it prohibitive. It is also important to remember DynamoDB is a NoSQL database that uses its own proprietary JSON-based query API, so it should be used when data models do not require normalized data with JOINs across tables which are more appropriate for SQL RDBMS systems.
Amazon DynamoDB Ecosystem
DynamoDB can be developed using Software Development Kits (SDKs) available from Amazon in a number of programming languages.
- C++
- Clojure
- Coldfusion
- Erlang
- F#
- Go
- Groovy/Rails
- Java
- JavaScript
- .NET
- Node.js
- PHP
- Python
- Ruby
- Scala
There are also a number of integrations for DynamoDB to connect with other AWS services and open source big data technologies, such as Apache Kafka, and Apache Hive or Apache Spark via Amazon EMR.
DynamoDB Item Size Limit
The DynamoDB item size limit is 400 KB per item — a hard constraint that covers the entire item including attribute names and values. This is not a configurable quota or a soft limit; it is enforced at the API layer across all write operations: PutItem, UpdateItem, BatchWriteItem, and TransactWriteItems. The limit applies equally to items with a single large attribute and items with many smaller attributes — the 400 KB ceiling is aggregate.
Workloads that approach this boundary — large JSON documents, wide-row time series, or media metadata records — require application-side workarounds. The standard patterns are: (1) store large payloads in S3 and keep a reference pointer in DynamoDB, or (2) split large items across multiple items using a composite sort key. Both approaches add application complexity that doesn’t exist in databases without a hard row-size constraint. ScyllaDB imposes no equivalent per-row size limit at the API layer; large rows are managed transparently, without requiring application-side partitioning logic.
Note: One often-overlooked way to avoid DynamoDB item size limits is to use ScyllaDB’s DynamoDB compatible API. ScyllaDB does not impose any item size limits (or partition access limits).
DynamoDB Alternatives and Variants
DynamoDB is a proprietary, closed source offering. ScyllaDB is commonly used as a DynamoDB alternative because it’s DynamoDB-compatible API lets teams run DynamoDB workloads beyond AWS (on-prem on in any cloud) and at 50% lower cost.
ScyllaDB can run on any cloud or on premises. Both self-managed and fully-managed versions are available. It is source available and its DynamoDB-compatible API is open source.
There are no other direct alternatives to DynamoDB. While different NoSQL databases can provide key-value or document data models, it would require re-architecting data models and redesigning queries to achieve a DynamoDB migration to another database.
| Amazon DynamoDB | ScyllaDB | |
|---|---|---|
| Deployment | Fully managed AWS service. No servers to provision, patch, or operate. | Self-managed (on AWS, GCP, Azure, on-prem, or Kubernetes) or fully managed via ScyllaDB X Cloud. Available on AWS Marketplace. |
| API compatibility | Proprietary DynamoDB API plus PartiQL. | Dual API: native CQL (Cassandra-compatible) and Alternator, a DynamoDB-compatible API covering the vast majority of DynamoDB operations. Existing DynamoDB applications can migrate with minimal or no code changes. |
| Architecture | Managed, opaque internals. AWS handles partitioning, replication, and compaction automatically. | Shard-per-core design written in C++. Each CPU core owns its data and runs non-blocking async I/O, eliminating lock contention and maximizing hardware utilization. Tablets (dynamic data distribution via Raft) replaced legacy vNodes as of 2025.1. |
| Performance | Single-digit millisecond latency at scale. DAX in-memory cache available for microsecond read latency at extra cost. | Single-digit millisecond P99 latency maintained under load, during scaling, and during backup and recovery. ScyllaDB benchmarks show up to 4x lower P99 latency than DynamoDB on mixed workloads. |
| Scaling | Automatic. On-demand mode scales instantly; provisioned mode uses auto-scaling rules. | ScyllaDB X Cloud uses tablet-based architecture that scales from 100K to 2M ops/sec in minutes with consistent P99 latency. Clusters run safely at up to 90% storage utilization, reducing the need to overprovision. |
| Consistency | Eventually consistent by default; strongly consistent reads per request. Multi-Region strong consistency (MRSC) with zero RPO went GA Jun 2025. | Tunable consistency levels (LOCAL_QUORUM for region-local, QUORUM for global). Equivalent to DynamoDB’s eventual and strong consistency modes, with finer-grained control per operation. |
| Item / row size | 400 KB maximum per item. | No item size limit. Large objects that would require splitting and multi-step reads in DynamoDB can be stored as single rows. |
| Secondary indexes | Local and global secondary indexes. GSIs have independent throughput; multi-attribute composite GSI keys added Nov 2025. | Secondary indexes and materialized views supported. Alternator exposes DynamoDB-compatible GSI semantics for migrated applications. |
| Multi-region | Global tables: fully managed active-active replication. Cross-account replication added Feb 2026. | Built-in multi-datacenter replication with no separate global tables tier or additional per-table charges. Consistency level determines whether writes are region-local or globally synchronous. |
| Pricing model | Per-request (on-demand) or provisioned capacity. Separate charges for global tables, DAX, streams, and backups. Cost complexity increases significantly for write-heavy or multi-region workloads. | Node-based pricing tied to infrastructure consumed. No separate charges for reads vs. writes, global replication, or secondary indexes. ScyllaDB X Cloud guarantees costs at 50% of DynamoDB or less. |
| License | Proprietary AWS service. | Source-available since Dec 2024 (ScyllaDB Enterprise 2025.1+). The last open source release was OSS 6.2.x (AGPL). A free self-managed tier is available up to 10TB total disk and 50 vCPUs. Supporting components including Seastar and the Kubernetes operator remain Apache-licensed. |
| Vendor lock-in | AWS-only. ExtendDB (May 2026) provides an open source DynamoDB-compatible adapter with pluggable storage backends for local and on-prem use. | Runs across clouds and on-prem. DynamoDB API compatibility via Alternator means teams can migrate from DynamoDB and retain deployment flexibility across environments. |
| Operational overhead | Near-zero on AWS. No cluster management required. | ScyllaDB X Cloud is fully managed with near-zero ops overhead. Self-managed deployments require distributed systems expertise, though automated compaction, repair scheduling, and tablet rebalancing reduce manual tuning compared to Cassandra. |
| AWS ecosystem integration | Deep native integration with Lambda, CloudWatch, Kinesis, S3, IAM, and other AWS services. Zero-ETL integrations with Redshift and SageMaker Lakehouse. | Integrates with AWS services (Lambda, S3 for backups, available via AWS Marketplace) but without the same depth of native AWS service mesh as DynamoDB. |
| Best fit | AWS-native apps, serverless workloads, unpredictable traffic patterns, teams that want zero database operations. | Write-heavy or latency-sensitive workloads, teams hitting DynamoDB cost ceilings or item size limits, multi-cloud or on-prem requirements, and DynamoDB migrations that need API compatibility. |
DynamoDB Local
DynamoDB local lets teams develop and test applications without hitting the DynamoDB web service, avoiding throughput, storage, and data transfer costs. It also supports offline development.
DynamoDB local is not a drop-in replacement for the cloud version. The differences range from minor to significant — see Amazon’s DynamoDB Developer’s Guide for the full list. It also lacks high availability, making it unsuitable for production use.
To run DynamoDB on-premises in production, you need a DynamoDB-compatible implementation. ExtendDB is a newer (2026) Apache 2.0-licensed adapter that implements the DynamoDB wire protocol over PostgreSQL, but AWS describes it as a v0.1 release scoped to development, testing, and experimentation.
For production on-premises deployments, ScyllaDB Alternator backs the DynamoDB API with a distributed storage engine built for high availability and throughput at scale. GE Healthcare took that approach when they needed to move their DynamoDB-based Edison AI workbench on-prem to support research customers running in hospital networks.
For a walkthrough of running a DynamoDB app on-prem, see Build DynamoDB-Compatible Apps with Python.
DynamoDB vs Cassandra
The comparison between DynamoDB vs Cassandra comes down to deployment model, data model flexibility, and operational control. DynamoDB is a fully managed, closed-source AWS service — you don’t provision nodes, manage compaction, or configure replication. Cassandra is open-source, self-managed (or managed via third-party services), and runs on any infrastructure — cloud, on-premises, or hybrid. That difference in operational control has real implications: DynamoDB trades simplicity for vendor lock-in and unpredictable cost at scale; Cassandra trades managed ease for multi-cloud portability and operational flexibility.
From a data model perspective, both are wide-column stores at heart, but DynamoDB enforces a 400 KB per-item size limit and constrains secondary index design. Cassandra offers richer CQL semantics, more flexible partition layouts, and broader indexing options. For Amazon DynamoDB vs Cassandra evaluations, the deciding factor is typically where your infrastructure lives and whether AWS lock-in is acceptable. For teams running multi-cloud or on-prem, AWS DynamoDB vs Cassandra comparisons consistently favor Cassandra — or ScyllaDB, which extends Cassandra’s architecture with close-to-the-hardware performance and no JVM overhead.
| Amazon DynamoDB | Apache Cassandra | |
|---|---|---|
| Deployment | Fully managed AWS service. No servers to provision, patch, or operate. | Self-managed on VMs, bare metal, or Kubernetes. Managed options via DataStax Astra, Amazon Keyspaces, and others. |
| Data model | Key-value and document. Partition key required; sort key optional. Items are schema-less within a table. | Wide-column. Rows addressed by partition key and clustering columns. CQL schema enforced per table. |
| Query language | Proprietary API (GetItem, Query, Scan) plus PartiQL for SQL-style access. Queries must use the primary key or a GSI. | Cassandra Query Language (CQL), SQL-like syntax. Queries still constrained to partition key and clustering columns. |
| Secondary indexes | Local secondary indexes (defined at table creation) and global secondary indexes (added any time). GSIs have independent throughput and as of Nov 2025 support up to four attributes per key component. | Secondary indexes supported but carry known performance tradeoffs at scale. Materialized views available. Both require careful design. |
| Consistency | Eventually consistent reads by default; strongly consistent reads available per request. Multi-Region strong consistency (MRSC) for global tables went GA Jun 2025, providing zero RPO. | Tunable consistency per query (ONE, QUORUM, ALL, etc.), giving fine-grained control over the consistency/availability tradeoff. |
| Transactions | ACID transactions via TransactWriteItems and TransactGetItems across up to 100 items in a single table or across tables. | Lightweight transactions (LWT) via Paxos for conditional writes. Multi-row ACID transactions in Cassandra 4.x+. |
| Scaling | Automatic. On-demand mode scales to any traffic level instantly. Provisioned mode with auto-scaling also available. | Manual horizontal scaling by adding nodes. Linear scale-out by design, but operators manage rebalancing and ring topology. |
| Multi-region | Global tables provide managed active-active replication across regions. Cross-account replication added Feb 2026. | Built-in multi-datacenter replication via NetworkTopologyStrategy. Fully operator-controlled with no managed layer. |
| Pricing model | Pay per request (on-demand) or reserved capacity (provisioned). Additional charges for storage, streams, backups, and DAX. | Infrastructure cost only — compute, storage, network. No per-request charges. Predictable at high, steady-state throughput. |
| Vendor lock-in | AWS-only. ExtendDB (May 2026) provides an open source DynamoDB-compatible adapter with pluggable storage backends for local and on-prem use. | Open source (Apache 2.0). Runs on any cloud or on-premises. Compatible managed services include Amazon Keyspaces and Astra DB. |
| Item / row size | 400 KB maximum per item. | No hard row size limit; practical limit in the low MB range. Recommended partition size is under 100 MB. |
| Operational overhead | Near-zero. AWS handles replication, failover, patching, and capacity. | Significant. Requires expertise in node management, compaction tuning, repair scheduling, and schema migrations. |
| Best fit | AWS-native apps, serverless workloads, variable or unpredictable traffic, teams without dedicated database operations. | Write-intensive workloads at extreme scale, multi-cloud or on-prem requirements, teams with Cassandra operational expertise. |
DynamoDB vs Cassandra Performance
On DynamoDB vs Cassandra performance, single-digit millisecond latency is the stated target for both — but the mechanism differs significantly. DynamoDB’s performance is throughput-provisioned: you define Read Capacity Units (RCUs) and Write Capacity Units (WCUs), and the API throttles beyond those limits. Cassandra’s performance is hardware-driven: you size the cluster to your workload, with no API-layer throttle ceiling. Under sustained high-ingest workloads, Cassandra scales by adding nodes; DynamoDB scales by adjusting provisioned capacity or switching to on-demand billing — both of which introduce cost or latency unpredictability.
For strongly-consistent reads, DynamoDB charges double the RCUs of eventually-consistent reads. Cassandra’s consistency level is tunable per query (ONE, QUORUM, ALL) without a separate billing dimension. ScyllaDB — a Cassandra-compatible database built on a shard-per-core model — delivers sub-millisecond P99 latencies on equivalent hardware, making it a compelling performance alternative. A DynamoDB-compatible API is also available via ScyllaDB Alternator.
There are currently no published benchmarks comparing DynamoDB vs Cassandra performance on latency and throughput. If any are published, this will page will be updated to include them.
DynamoDB vs Aerospike
The DynamoDB vs Aerospike comparison is most relevant for workloads demanding sub-millisecond latency at extreme concurrency — real-time bidding, fraud detection, gaming leaderboards, and session data. Aerospike is purpose-built for these scenarios: it uses a hybrid memory architecture (primary indexes in DRAM, data on NVMe SSDs) to deliver consistent sub-millisecond reads without the throughput-provisioning model DynamoDB applies. DynamoDB’s adaptive capacity helps absorb traffic bursts, but hard RCU/WCU ceilings remain, and provisioned throughput is billed whether used or not.
DynamoDB offers simpler operational overhead for teams deeply embedded in AWS — no cluster management, auto-scaling built in, no infrastructure to maintain. Aerospike returns better raw performance per node and more predictable tail latency under sustained load, but requires operational expertise and cluster management. For teams that need DynamoDB-compatible APIs with Aerospike-class latency on self-managed or multi-cloud infrastructure, ScyllaDB Alternator provides a drop-in DynamoDB-API replacement that operates without throughput caps or per-request billing.
| Amazon DynamoDB | Aerospike | |
|---|---|---|
| Deployment | Fully managed AWS service. No servers to provision, patch, or operate. | Self-managed (any cloud, on-prem, or bare metal), Aerospike Cloud Managed Service (Aerospike SREs operate within your cloud account), or Aerospike Cloud (fully managed DBaaS). Available on AWS Marketplace. |
| Architecture | Managed, opaque internals. AWS handles partitioning, replication, and storage automatically. | Hybrid Memory Architecture: primary indexes in DRAM, data on NVMe SSDs. Written in C, shared-nothing, masterless. All-in-memory mode also supported. |
| Data model | Key-value and document. Schema-less except for the primary key definition. | Multi-model: key-value, document (JSON), graph, and vector search. Data organized into namespaces, sets, and records with named bins. Flex-schema. |
| Consistency | Eventually consistent reads by default; strongly consistent reads available per request at twice the read capacity cost. Multi-Region strong consistency (MRSC) for global tables went GA Jun 2025. | Two configurable modes per namespace: AP (eventual consistency) and CP (strong consistency, linearizable reads). CP is Enterprise Edition only. Jepsen-tested since Database 4.0 (2018). |
| Transactions | ACID transactions via TransactWriteItems and TransactGetItems across up to 100 items. | Distributed ACID transactions with strict serializability added in Database 8.0 (January 2025), within a single namespace. Scans and queries cannot participate. Requires Enterprise Edition. |
| Multi-region | Global tables: fully managed active-active replication. Cross-account replication added Feb 2026. | Cross Datacenter Replication (XDR): active-passive and active-active topologies. Enterprise Edition only. Multi-namespace mapping added in Database 8.1 (Aug 2025). |
| Secondary indexes | Local and global secondary indexes. GSIs have independent throughput; multi-attribute composite GSI keys added Nov 2025. GSI reads are eventually consistent. | Secondary indexes stored in DRAM. Expression indexes (Database 8.1, Aug 2025) allow indexes on computed values. Secondary index queries may return stale results during data migration in CP mode. |
| Pricing model | Per-request (on-demand) or provisioned capacity. Separate charges for storage, streams, global tables, backups, and DAX. | Enterprise licensing based on unique production data volume, not per-request or per-core. Aerospike Cloud priced by cluster size and data volume. Exact pricing requires sales engagement. |
| License | Proprietary AWS service. | Community Edition is open source (AGPLv3), capped at 8 nodes and 5TB. Enterprise Edition is closed source, commercial. |
| AWS ecosystem integration | Deep native integration with Lambda, CloudWatch, Kinesis, S3, and IAM. Zero-ETL integrations with Redshift and SageMaker Lakehouse. | Available on AWS Marketplace, deployable on EC2. External connectors for Kafka, Spark, and Elasticsearch available in Enterprise Edition. No equivalent native AWS service mesh. |
| Best fit | AWS-native apps, serverless workloads, unpredictable traffic, teams that want zero database operations. | Applications requiring sub-millisecond latency at extreme throughput where dataset size makes pure in-memory solutions cost-prohibitive. |
DynamoDB Cost Resources
Explore our collection of useful DynamoDB cost resources to enhance your understanding of how DynamoDB pricing works and how to optimize your costs.
Articles & Videos
Featuring insights from leading DynamoDB expert Alex DeBrie, get guidance for teams facing rising production costs.
Understanding DynamoDB Cost Spikes
See how cost and performance compare across workload mixes.
Why AWS DynamoDB Costs Catch Teams Off Guard
See why DynamoDB costs can be hard to predict, highlighting how capacity modes, indexes, and access patterns impact billing.
How Yieldmo Cut Database Costs and Cloud Dependencies
See how Yieldmo reduced database costs and cloud dependence, outlining practical lessons for teams evaluating similar migrations.
A New Way to Estimate DynamoDB Costs
A guide to estimating DynamoDB costs for helping teams plan or audit workloads before production.
How You Should Think about DynamoDB Costs
Pricing guide from Alex DeBrie covering all major DynamoDB cost dimensions, for teams evaluating or optimizing workloads.
Videos
DynamoDB Cost Optimization Masterclass
A Masterclass on DynamoDB cost drivers and practical strategies to reduce infrastructure spend.
Understanding the True Cost of DynamoDB
A webinar on architectural and operational factors that influence DynamoDB costs in production, helping teams better understand pricing behavior.
Cost Tools
Our interactive cost calculator for DynamoDB that models workload scenarios and helps teams explore how configuration choices impact infrastructure spending.
The official cost estimation tool from AWS for modeling DynamoDB workloads and forecasting monthly infrastructure spend.
Third-party cost estimator for DynamoDB that provides quick pricing insights based on workload throughput and storage inputs.
DynamoDB on GCP (Google Cloud)
DynamoDB database workloads can run on GCP with the help of Alternator, ScyllaDB’s DynamoDB-compatible API. This API can be used to run DynamoDB workloads on any Public Cloud (AWS, GCP, Azure and others), Hybrid Cloud environments or on-prem.
DynamoDB’s API uses JSON-encoded requests and responses which are sent over an HTTP or HTTPS transport. It is described in detail in Amazon’s DynamoDB API Reference.
With the Alternator API, DynamoDB API queries are interpreted directly by ScyllaDB’s native mechanisms. This avoids performance loss caused by translation and ensures efficient execution. Alternator also uses standard data transport protocols.
Alternator allows ScyllaDB to process DynamoDB API requests alongside traditional CQL requests. It:
- Processes HTTP requeSeests with JSON payloads
- Uses the same installation as standard ScyllaDB
- Requires minimal configuration changes:
- Uses a port specification for Alternator traffic
- Offers read-modify-write operation isolation settings
See how Yieldmo and Digital Turbine used Alternator.
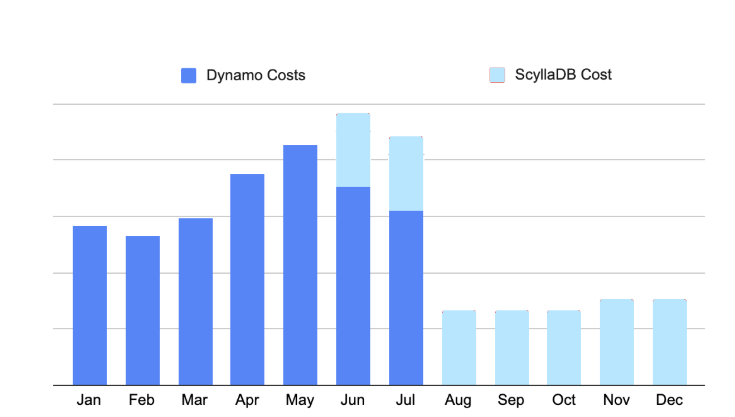
DynamoDB Cost Resources
Explore our collection of useful DynamoDB cost resources to enhance your understanding of how DynamoDB pricing works and how to optimize your costs.
DynamoDB Cost – Articles and Videos
DynamoDB Cost Optimization Masterclass: This masterclass offers a structured introduction to the factors that drive DynamoDB spending, covering core pricing dimensions such as read/write capacity modes, data transfer, and storage. It presents optimization strategies applicable across a range of workloads and team sizes. Engineers and architects seeking to reduce infrastructure costs will find it a practical starting point. Presenters include DynamoDB Book author Alex DeBrie and SADA CTO Miles Ward.
How to Reduce DynamoDB Costs: Expert Tips from Alex DeBrie: Alex DeBrie is widely regarded as one of the foremost authorities on DynamoDB data modeling and pricing, and this article distills his practical experience into concrete, actionable recommendations. Readers benefit from the perspective of a practitioner who has worked with DynamoDB at scale across many organizational contexts, rather than relying solely on vendor documentation. The piece is particularly relevant for teams that have already deployed DynamoDB in production and are encountering unexpectedly high costs.
Understanding DynamoDB Cost Spikes Through Real Usage Scenarios: Cost spikes in DynamoDB are often counterintuitive, arising from access patterns or configuration choices that appear reasonable in isolation but prove expensive at scale. This article examines real-world scenarios in which bills increased sharply, offering readers a diagnostic lens for evaluating their own workloads. It is particularly useful for teams preparing to scale an existing deployment or onboarding new application features that change query patterns.
Why AWS DynamoDB Costs Catch Teams Off Guard: DynamoDB’s pricing model differs substantially from traditional relational databases, and the gap between expected and actual costs frequently surprises engineering teams. This article examines the structural reasons why DynamoDB billing is difficult to predict, including the interplay between capacity modes, secondary indexes, and access patterns. It serves as a useful reference for teams conducting post-mortems on billing anomalies or evaluating DynamoDB for a new use case.
How Yieldmo Cut Database Costs and Cloud Dependencies: This case study documents how Yieldmo, an advertising technology company, reduced its database spending while decreasing reliance on a single cloud provider. It provides a detailed account of the technical and organizational factors that drove the migration decision, offering a template for teams evaluating similar transitions. Its focus on both cost outcomes and operational independence makes it relevant to broader conversations about vendor lock-in.
A New Way to Estimate DynamoDB Costs: Accurate cost estimation for DynamoDB has historically required manual calculation across multiple pricing dimensions, making it difficult to model expenses during the design phase of a project. This article introduces a structured approach and associated tooling for generating more reliable cost estimates before a workload goes to production. It is also useful for teams auditing an existing deployment who want a repeatable framework for understanding where costs originate.
Understanding the True Cost of DynamoDB: This webinar examines the full range of factors that contribute to DynamoDB costs, going beyond list prices to address the operational and architectural decisions that drive real-world bills. It is aimed at engineering and infrastructure teams who need a deeper understanding of how DynamoDB pricing behaves under production conditions. The content is relevant both for teams already running DynamoDB workloads and those evaluating it as part of a new architecture.
How You Should Think about DynamoDB Costs: This in-depth guide from DynamoDB expert Alex DeBrie provides a thorough breakdown of every dimension of DynamoDB pricing, including read/write capacity, storage, data transfer, and secondary indexes. It is widely referenced as a foundational resource for understanding how the various components of DynamoDB billing interact with one another. Teams at any stage of a DynamoDB deployment — from initial evaluation to cost optimization — will find it a valuable reference.
How to Optimize DynamoDB Costs: This guide covers practical techniques for optimizing your DynamoDB spending across capacity planning, data modeling, automatic cleanup, and global deployments.
Interactive DynamoDB Cost Tools
DynamoDB Cost Calculator: This interactive calculator allows teams to estimate and compare database costs across different workload profiles, including baseline and peak throughput scenarios. Users can adjust parameters such as read/write rates, storage, replication, and compression to model how infrastructure choices affect total cost. It also lets you review various real-world DynamoDB cost scenarios and adjust the numbers to explore “what if” scenarios.
AWS Pricing Calculator: The AWS Pricing Calculator is the official tool for estimating costs across AWS services, including DynamoDB. Users can configure capacity modes, request rates, storage, and data transfer to generate a projected monthly bill. It serves as a reference point for teams building budget forecasts or comparing the cost implications of different DynamoDB configurations.
DynamoDB Pricing Calculator: This third-party calculator offers a streamlined interface for estimating DynamoDB costs based on read/write request volume, storage, and capacity mode. It is designed for quick, focused cost estimates without the broader complexity of the official AWS tooling.