




ScyllaDB Enterprise is a high-performance enterprise NoSQL database for real-time big data workloads that offers the horizontal scale-out and fault-tolerance of Apache Cassandra, yet delivers 10X the throughput and consistent, low single-digit latencies. Implemented from scratch in C++, ScyllaDB’s close-to-the-hardware design significantly reduces the number of database nodes you require and self-optimizes to dynamic workloads and various hardware combinations.
With ScyllaDB Enterprise 2019.1 we’ve introduced new capabilities, as well as inherited a rich set of new features from our ScyllaDB Open Source 3.0 release for more efficient querying, reduced storage requirements, lower repair times, and better overall database performance. Already the industry’s most performant NoSQL database, ScyllaDB now includes production-ready features that surpass the capabilities of Apache Cassandra.
ScyllaDB Enterprise 2019.1 is now available for download for existing customers.
If you’re not yet a customer, you can register for a 30-day trial.
New Features in 2019.1
ScyllaDB Enterprise 2019.1 includes all the ScyllaDB Enterprise features of previous releases, including Auditing and In-Memory Tables. It also now includes an innovative new feature that’s exclusive to ScyllaDB Enterprise:
Workload Prioritization (Technology Preview)
ScyllaDB Enterprise will enable its users to safely balance multiple real-time workloads within a single database cluster. For example, Online Transaction Processing (OLTP) and Online Analytical Processing (OLAP), which have very different data access patterns and characteristics, can be run concurrently on the same cluster. OLTP involves many small and varied transactions, including mixed writes, updates, and reads, with a high sensitivity to latency. In contrast, OLAP emphasizes the throughput of broad scans across datasets. By introducing capabilities that isolate workloads, ScyllaDB Enterprise will uniquely support simultaneous OLTP and OLAP workloads without sacrificing latency or throughput. However, workload prioritization can be used to differentiate between any two or more different workloads (for example, different OLTP workloads with different priorities or SLAs). More on Workload Prioritization
Features Inherited from ScyllaDB Open Source
The following features that were previously introduced in ScyllaDB Open Source NoSQL Database are now part of the Enterprise branch and are included with the ScyllaDB 2019.1 release:
Materialized Views (MV)
Material Views automate the tedious and inefficient chores created when an application maintains several tables with the same data organized differently. Data is divided into partitions that can be found by a partition key. Sometimes the application needs to find a partition or partitions by the value of another column. Doing this efficiently without scanning all of the partitions requires indexing.
People have been using Materialized Views, also calling them denormalization, for years as a client-side implementation. In such implementations, the application maintained two or more views and two or more separate tables with the same data but under a different partition key. Every time the application wanted to write data, it needed to write to both tables, and reads were done directly (and efficiently) from the desired table. However, ensuring any level of consistency between the data in the two or more views required complex and slow application logic.
ScyllaDB’s Materialized Views feature moves this complexity out of the application and into the servers. As a result, the implementation is faster (fewer round trips to the applications) and more reliable. This approach makes it much easier for applications to begin using multiple views into their data. The application just declares the additional views, ScyllaDB creates the new view tables, and on every update to the base table the view tables are automatically updated as well. Writes are executed only on the base table directly and are automatically propagated to the view tables. Reads go directly to the view tables.
As usual, the ScyllaDB version is compatible – in features and CQL syntax – with the Apache Cassandra version (where it is still in experimental mode).

Global Secondary Indexes (GSI)
ScyllaDB Enterprise 2019.1 now supports production-ready global secondary indexes that can scale to any size distributed cluster — unlike the local-indexing approach adopted by Apache Cassandra.
The secondary index uses a Materialized View index under the hood in order to make the index independent from the amount of nodes in the cluster. Secondary Indexes are (mostly) transparent to the application.
Queries have access to all the columns in the table and you can add and remove indexes without changing the application. Secondary Indexes can also have less storage overhead than Materialized Views because Secondary Indexes need to duplicate only the indexed column and primary key, not the queried columns like with a Materialized View.
For the same reason, updates can be more efficient with Secondary Indexes because only changes to the primary key and indexed column cause an update in the index view. In the case of a Materialized View, an update to any of the columns that appear in the view requires the backing view to be updated.
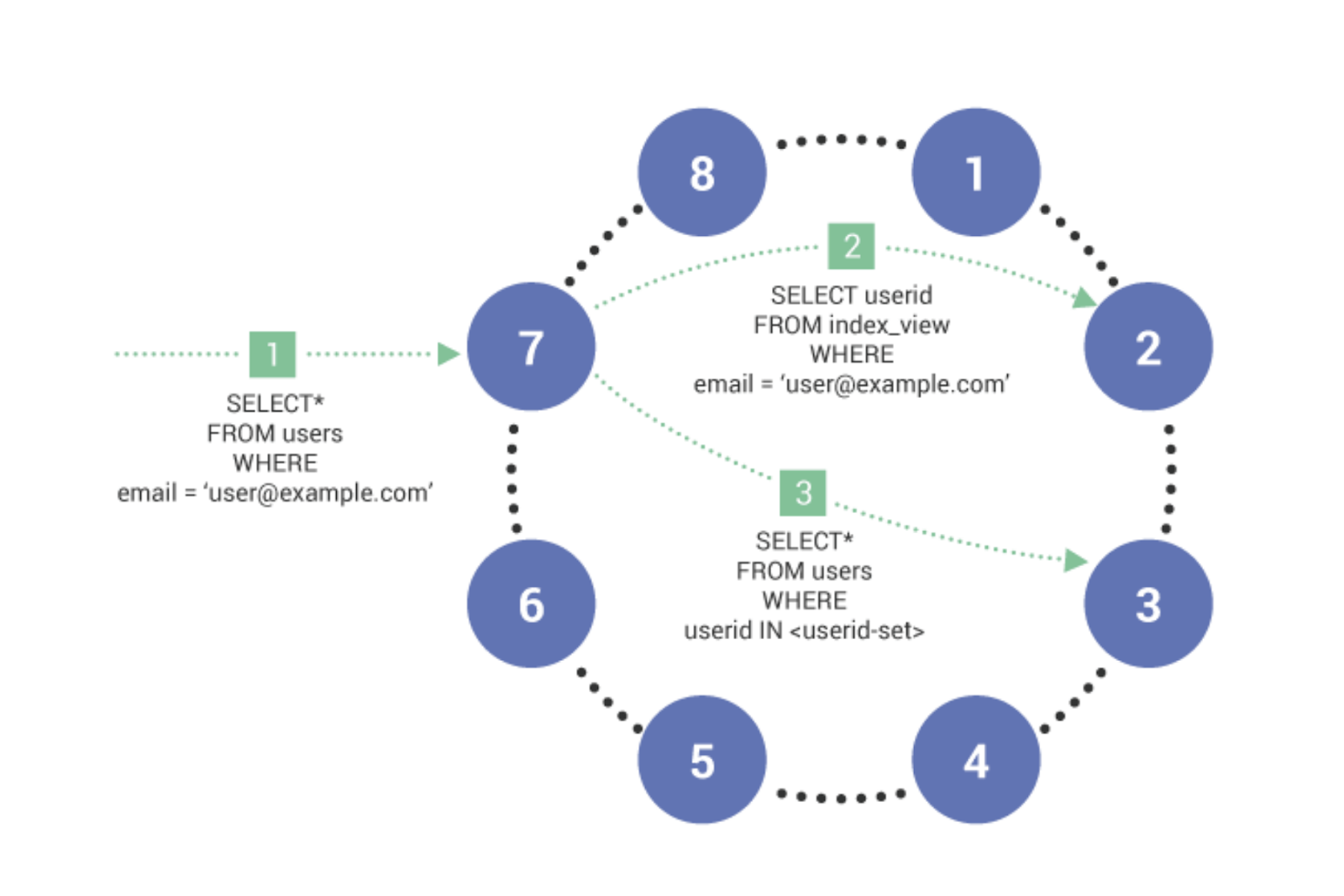
As always, the decision whether to use Secondary Indexes or Materialized Views really depends on the requirements of your application. If you need maximum performance and are likely to query a specific set of columns, you should use Materialized Views. However, if the application needs to query different sets of columns, Secondary Indexes are a better choice because they can be added and removed with less storage overhead depending on application needs.
Global secondary indexes minimize the amount of data retrieved from the database, providing many benefits:
- Results are paged and customizable
- Filtering is supported to narrow result sets
- Keys, rather than data, are denormalized
- Supports more general-purpose use cases than Materialized Views
CQL: Enable ALLOW FILTERING for regular and primary key columns
Allow filtering is a way to make a more complex query, returning only a subset of matching results. Because the filtering is done on the server, this feature also reduces the amount of data transferred over the network between the cluster and the application. Such filtering may incur processing impacts to the ScyllaDB cluster. For example, a query might require the database to filter an extremely large data set before returning a response. By default, such queries are prevented from execution, returning the following message:
Bad Request: Cannot execute this query as it might involve data filtering and thus may have unpredictable performance.
Unpermitted queries include those that restrict:
- Non-partition key fields
- Parts of primary keys that are not prefixes
- Partition keys with something other than an equality relation (though you can combine SI with ALLOW FILTERING to support inequalities; >= or <=; see below)
- Clustering keys with a range restriction and then by other conditions (see this blog)
However, in some cases (usually due to data modeling decisions), applications need to make queries that violate these basic rules. Queries can be appended with the ALLOW FILTERING keyword to bypass this restriction and utilize server-side filtering.
The benefits of filtering include:
- Cassandra query compatibility
- Spark-Cassandra connector query compatibility
- Query flexibility against legacy data sets
Hinted Handoffs
Hinted handoffs are designed to help when any individual node is temporarily unresponsive due to heavy write load, network weather, hardware failure, or any other factor. Hinted handoffs also help in the event of short-term network issues or node restarts, reducing the time for scheduled repairs, and resulting in higher overall performance for distributed deployments.
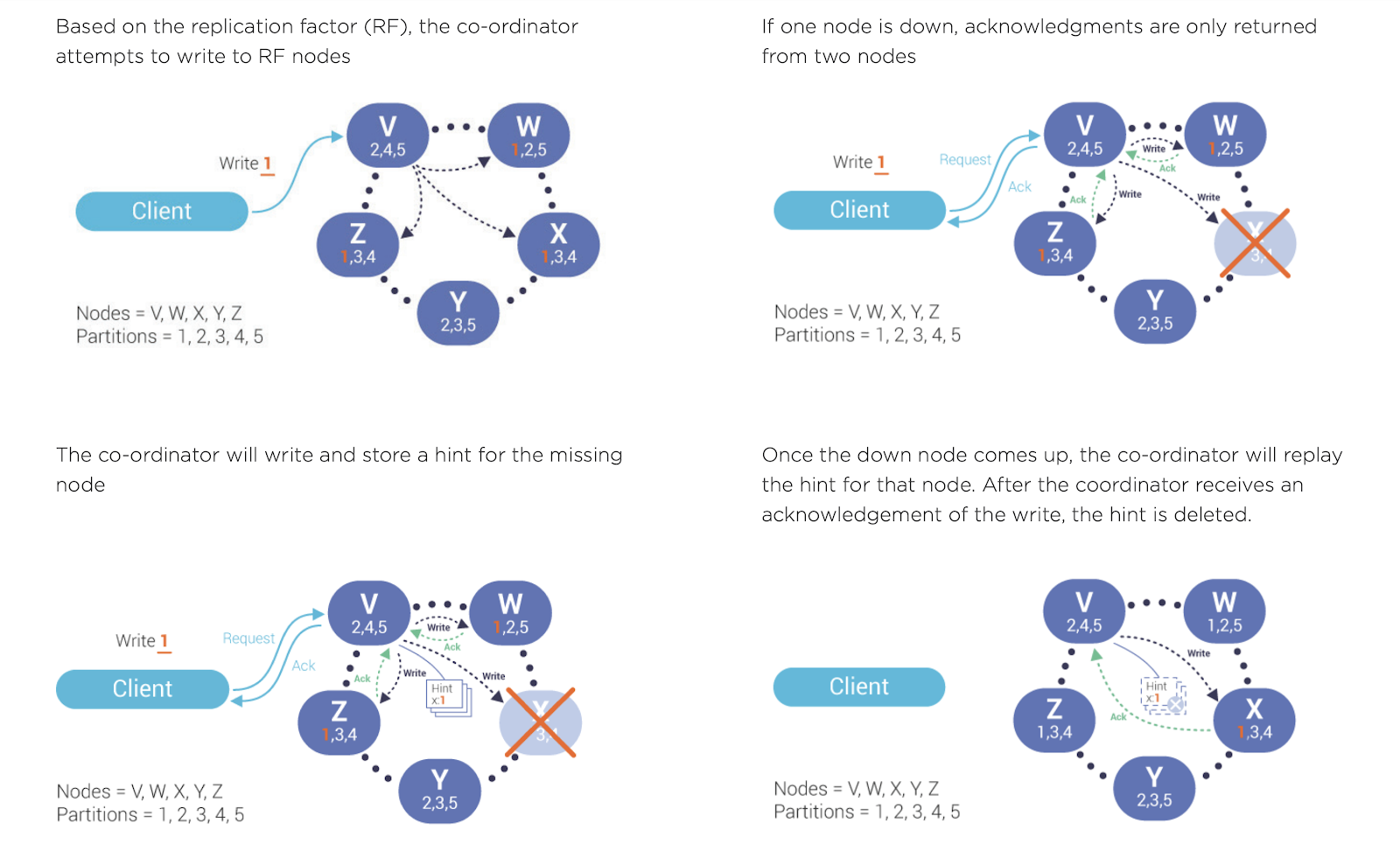
Technically, a ‘hint’ is a record of a write request held by the coordinator until an unresponsive replica node comes back online. When a write is deemed successful but one or more replica nodes fail to acknowledge it, ScyllaDB will write a hint that is replayed to those nodes when they recover. Once the node becomes available again, the write request data in the hint is written to the replica node.
Hinted handoffs deliver the following benefits:
- Minimizes the difference between data in the nodes when nodes are down—whether for scheduled upgrades or for all-too-common intermittent network issues.
- Reduces the amount of data transferred during repair.
- Reduces the chances of checksum mismatch (during read-repair) and thus improves overall latency.
New File Format (SSTable 3.0 “mc” format)
ScyllaDB Enterprise 2019.1 now has support for a more performant storage format (SSTable), which is not only compatible with Apache Cassandra 3.x but also reduces storage volume by as much as 3X. The older 2.x format used to duplicate the column name next to each cell on disk. The new format eliminates the duplication and the column names are stored once, within the schema.
The newly introduced format is identical to that used by Apache Cassandra 3.x, while remaining backward-compatible with prior ScyllaDB SSTable formats. New deployments of ScyllaDB Enterprise 2019.1 will automatically use the new format, while existing files remain unchanged.
This new storage format delivers important benefits, including:
- Can read existing Apache Cassandra 3.x files when migrating
- Faster than previous versions
- Reduced storage footprint of up to 66%, depending on the data model used
- Range delete support
Full (multi-partition) scan improvement
ScyllaDB Enterprise 2019.1builds on earlier improvements by extending stateful paging to support range scans as well. As opposed to other partition queries, which read a single partition or a list of distinct partitions, range scans read all of the partitions that fall into the range specified by the client. Since the precise number and identity of partitions in a given range cannot be determined in advance, the query must read data from all nodes containing data for the range.
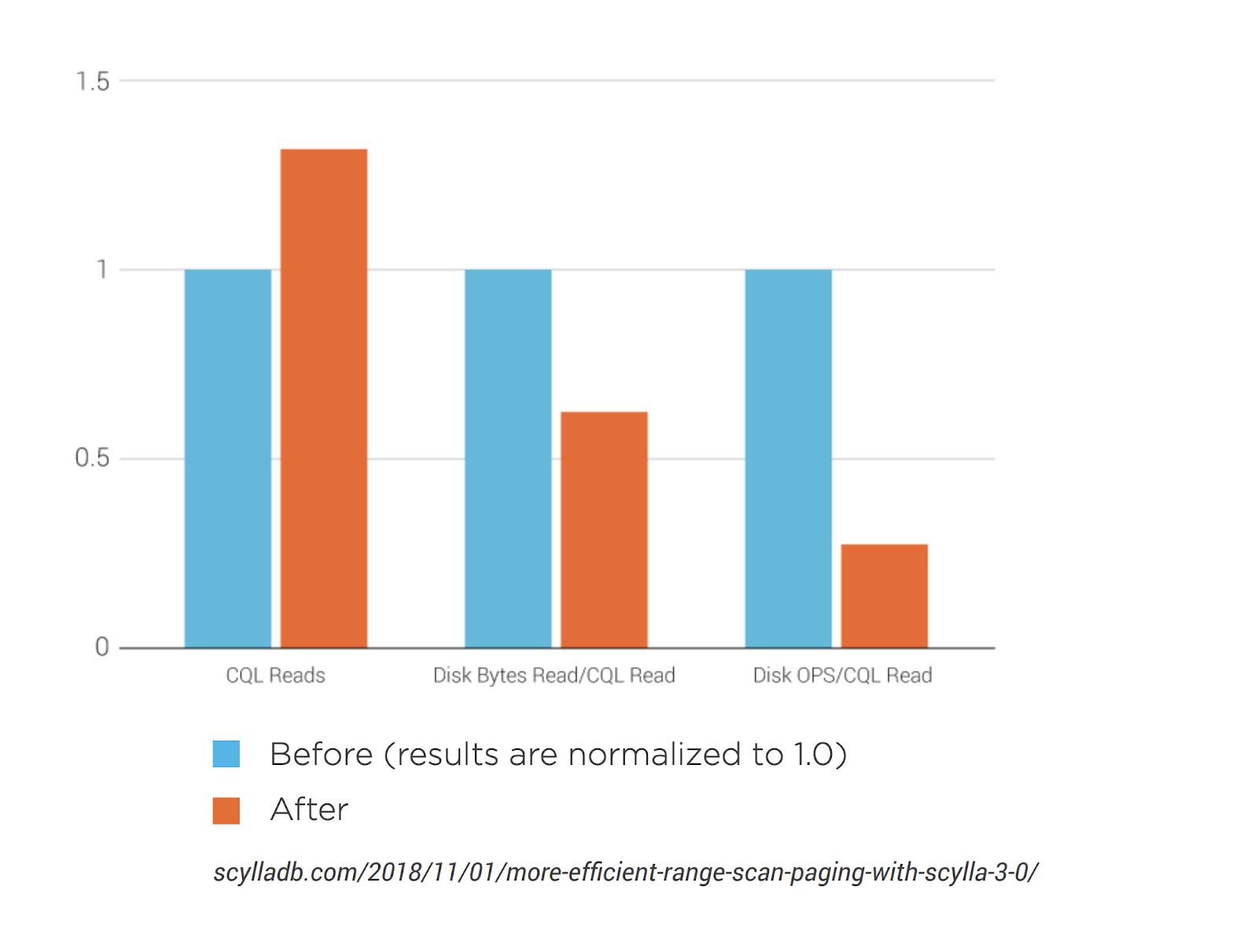
To improve range scan paging, ScyllaDB Enterprise now has a new control algorithm for reading all data belonging to a range from all shards, which caches the intermediate streams on each of the shards and directs paged queries to the matching, previously used, cached results. The new algorithm is essentially a multiplexer that combines the output of readers opened on affected shards into a single stream. The readers are created on-demand when the partition scan attempts to read from the shard. To ensure that the read won’t stall, the algorithm uses buffering and read-ahead.
Benefits include:
- Improved system responsiveness
- Throughput of range scans improved by as much as 30%
- Amount of data read from the disk reduced by as much as 40%
- Disk operations lowered by as much as 75%
Role-Based Access Control (RBAC)
Role-Based Access Control (RBAC) is a method of reducing lists of authorized users to a few roles assigned to multiple users. RBAC is sometimes referred to as role-based security.
GoogleCloudSnitch
Use the GoogleCloudSnitch for deploying ScyllaDB on the Google Cloud Engine (GCE) platform across one or more regions. The region is treated as a datacenter and the availability zones are treated as racks within the datacenter. All communication occurs over private IP addresses within the same logical network.
To use the GoogleCloudSnitch, add the snitch to the scylla.yaml file which is located under /etc/scylla/ for all nodes in the cluster.
Tooling
Large Partitions
ScyllaDB Enterprise 2019.1 comes with a helping hand for discovering and investigating large partitions present in a cluster — system.large_partitions table. Sometimes you have such issues without realizing it. It’s useful to be able to see which tables have large partitions and how many of them exist in a cluster. Aside from table name and size, system.large_partitions contains information on the offending partition key, when the compaction that led to the creation of this large partition occurred, and its sstable name (which makes it easy to locate its filename).
The large partition warning threshold defaults to 100MiB, which implies that each larger partition will be registered into system.large_partitions table the moment it’s written, either because of memtable flush or as a result of compaction. The threshold can be configured with an already existing parameter in scylla.yaml:
compaction_large_partition_warning_threshold_mb: 100
iotune v2
Iotune is a storage benchmarking tool that runs as part of the scylla_setup script. Iotune runs a short benchmark on the ScyllaDB storage and uses the results to set the ScyllaDB io_properties.yaml configuration file (formerly called io.conf). ScyllaDB uses these settings to optimize I/O performance, specifically through setting max storage bandwidth and max concurrent requests.The new iotune output matches the IO scheduler configuration, is time-limited (2 minutes) and produces more consistent results than the previous version.
CQL
Datetime Functions Support
ScyllaDB supports Cassandra-style datetime functions, including currentTimestamp, currentDate, currentTime, and currentTimeUUID.
Support for the Javascript Object Notation (JSON) format, including inserting JSON documents, retrieving data in JSON and providing helper functions to transform native CQL types into JSON and vice versa. Schemas are still enforced for all operations — one cannot just insert random JSON documents into a table. The new API is simply a convenient way of working with JSON without having to convert everything back and forth on the client-side.
Performance Improvements
Streaming Improvements
Streaming is used during node recovery to populate restored nodes with data replicated from running nodes. The ScyllaDB streaming model reads data on one node, transmits it to another node, and then writes to disk. The sender creates SSTable readers to read the rows from SSTables on disk and sends them over the network. The receiver receives the rows from the network and writes them to a memtable. The rows in memtable are flushed into SSTables periodically or when the memtable is full.
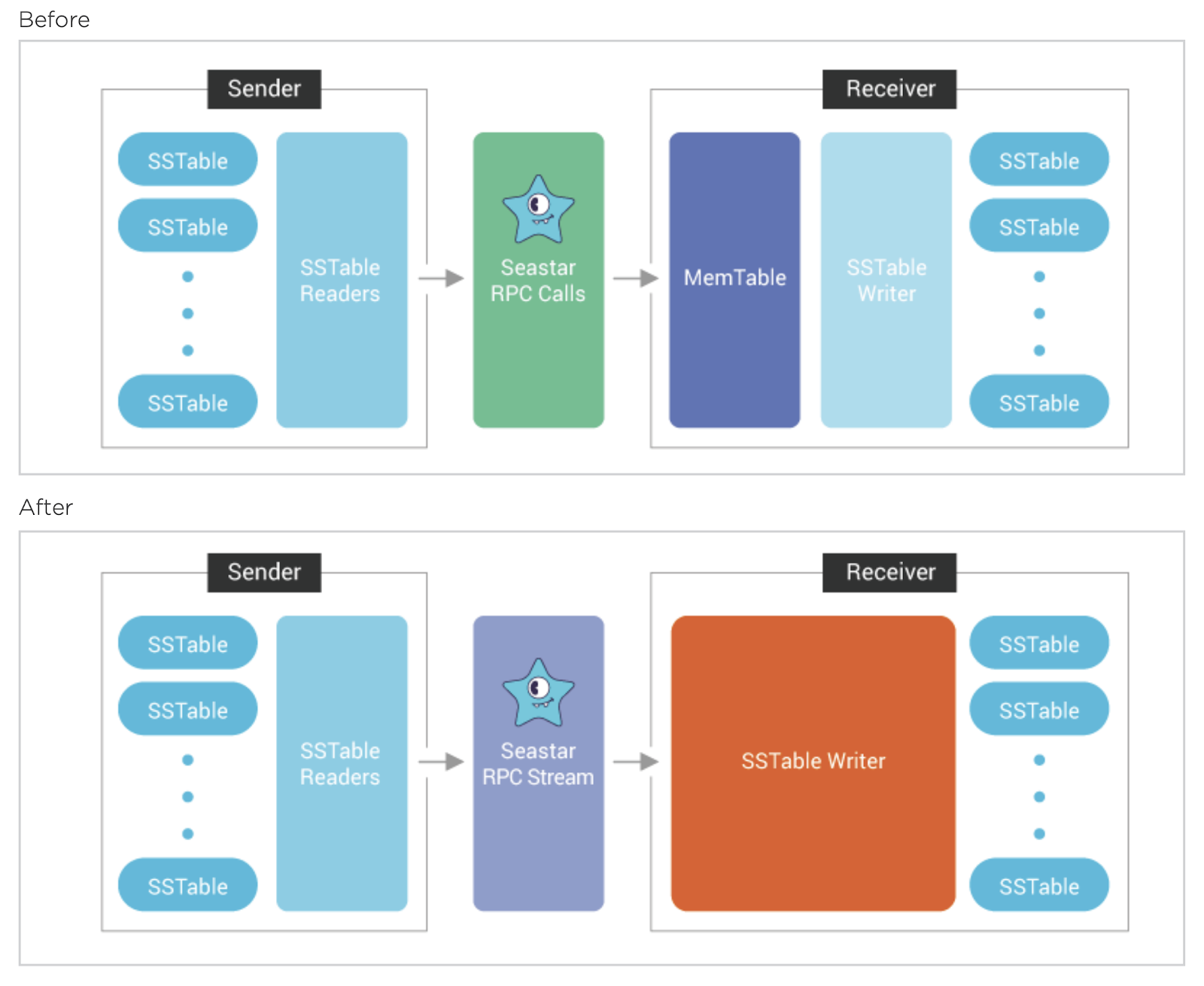
In ScyllaDB Enterprise 2019.1, stream synchronization between nodes bypasses memtables, significantly reducing the time to repair, add and remove nodes. These improvements result in higher performance when there is a change in the cluster topology, improving streaming bandwidth by as much as 240% and reducing the time it takes to perform a “rebuild” operation by 70%.
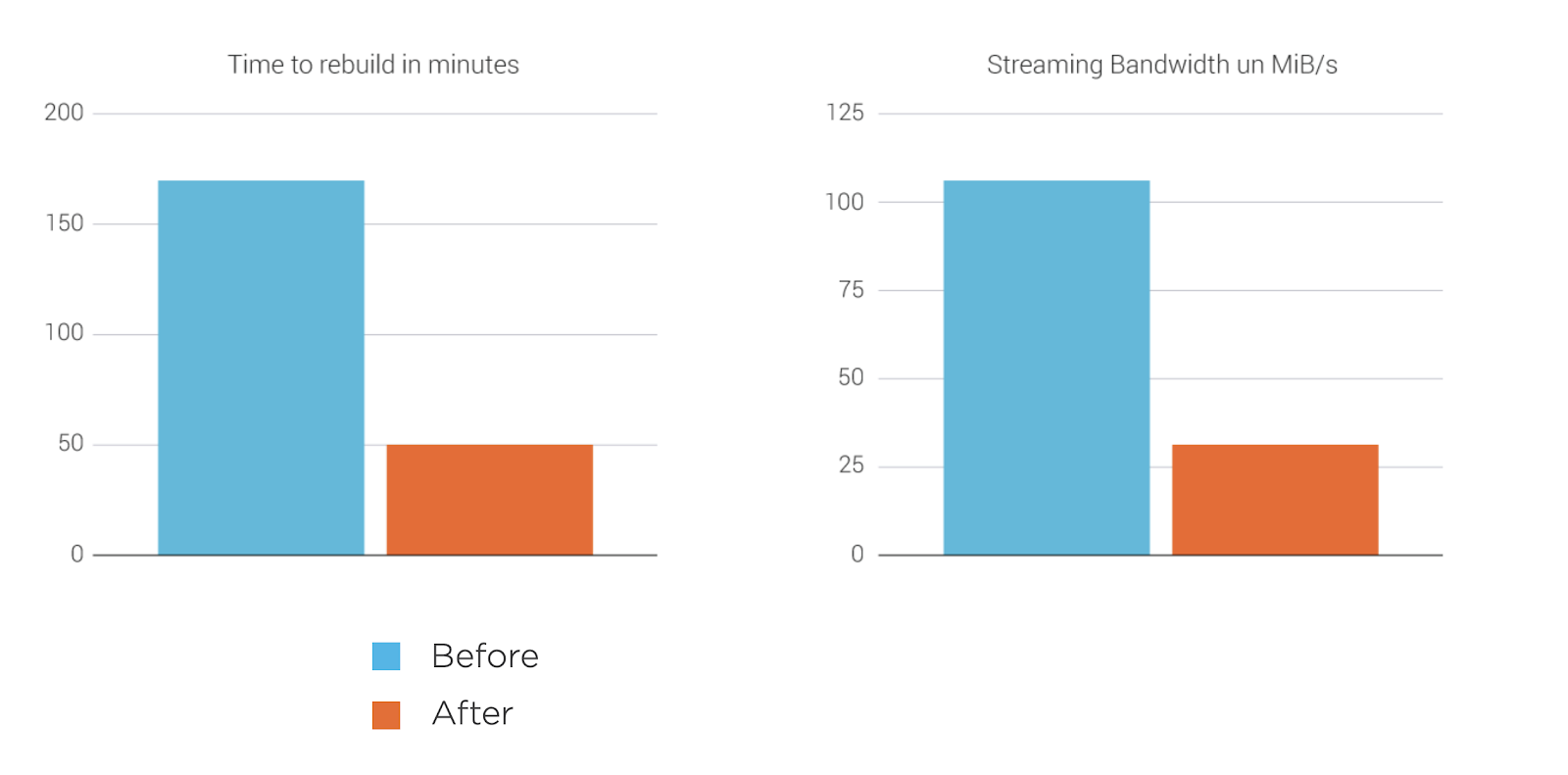
ScyllaDB’s new streaming improvements provide the following benefits:
- Lower memory consumption. The saved memory can be used to handle your CQL workload instead.
- Better CPU utilization. No CPU cycles are used to insert and sort memtables.
- Bigger SSTables and fewer compactions.
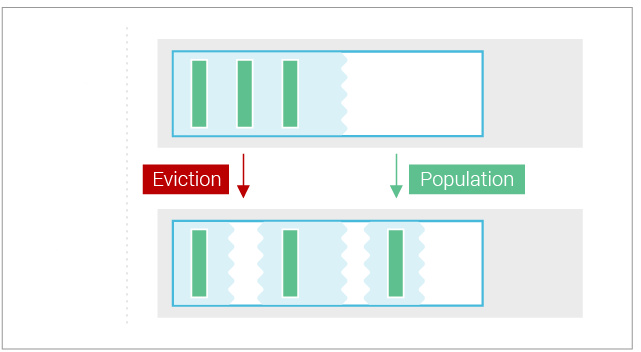
Row-level Cache Eviction
The cache is capable of freeing individual rows to satisfy memory reclamation requests. Rows are freed starting from the least recently used ones, with insertion counting as a use. For example, a time-series workload, which inserts new rows in the front of a partition, will cause eviction from the back of the partition. More recent data in the front of the partition will be kept in cache.
CPU Scheduler and Compaction Controllers
With ScyllaDB’s thread-per-core architecture, many internal workloads are multiplexed on a single thread. These internal workloads include compaction, flushing memtables, serving user reads and writes, and streaming. The CPU scheduler isolates these workloads from each other, preventing, for example, a compaction using all of the CPU and preventing normal read and write traffic from using its fair share. The CPU scheduler complements the I/O scheduler, which solves the same problem for disk I/O. Together, these two are the building blocks for the compaction controller. More on using Control Theory to keep compactions Under Control.
Release Notes
You can read more details about ScyllaDB Enterprise 2019.1 in the Release Notes.







