In a previous blog post we examined how ScyllaDB’s paging works, explained the problems with it and introduced the new stateful paging in ScyllaDB 2.2 that solves these problems for singular partition queries by making paging stateful.
In this second blog post we are going to look into how stateful paging was extended to support range-scans as well in ScyllaDB Open Source 3.0. We were able to increase the throughput of range scans by 30% and how we also significantly reduced the amount of data read from the disk by 39% and the amount of disk operations by 73%.
A range scan, or a full table scan, is a query which does not use the partition key in the WHERE clause. Such scans are less efficient than a single partition scan, but they are very useful for ad-hoc queries and analytics, where the selection criteria does not match the partition key.
How do Range Scans Work in ScyllaDB 2.3?
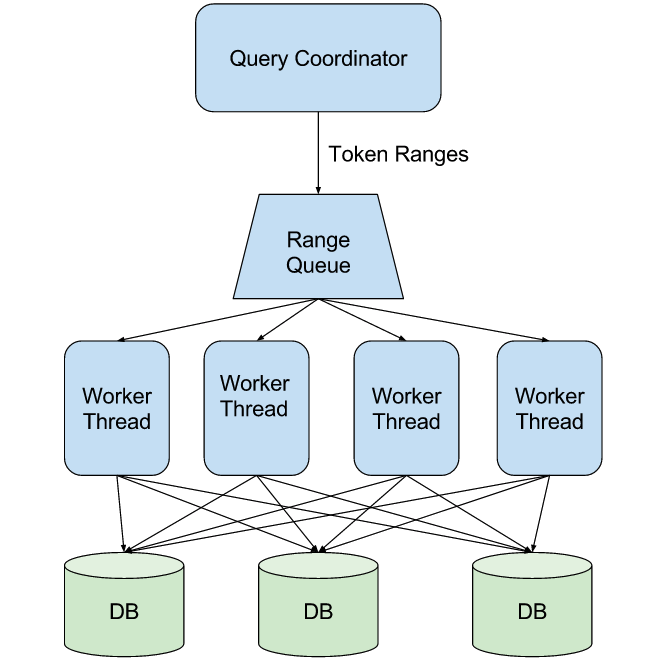
Range scans work quite differently compared to singular partition queries. As opposed to singular partition queries, which read a single partition or a list of distinct partitions, range scans read all of the partitions that fall into the range specified by the client. The exact number of partitions that belong to a given range and their identity cannot be determined up-front, so the query has to read all of the data from all of the nodes that contain data for the range.
Tokens (and thus partitions) in ScyllaDB are distributed on two levels. To quickly recap, a token is the hash value of the partition key, and is used as the basis for distributing the partitions in the cluster.
Tokens are distributed among the nodes, each node owning a configurable amount of chunks from the token ring. These chunks are called vnodes. Note that when the replication factor (RF) of a keyspace is larger than 1, a single vnode can be found on a number of nodes, this number being equal to the replication factor (RF).
On each node, tokens of a vnode are further distributed among the shards of the node. The token of a partition key in ScyllaDB (which uses the MurmurHash3 hashing algorithm), is a signed 64 bit integer. The sharding algorithm ignores the 12 most significant bit of this integer, and maps the rest to a shard id. This results in a distribution that resembles a round robin.

Figure 1: ScyllaDB’s distribution of tokens of a vnode across the shards of a node.
A range scan also works on two levels. The coordinator has to read all vnodes that intersect with the read range, and each contacted replica has to read all shard chunks that intersect with the read vnode. Both of these present an excellent opportunity for parallelism that ScyllaDB exploits. As already mentioned, the amount of data each vnode, and further down each shard chunk contains is unknown. Yet the read operates with a page limit that has to be respected on both levels. It is easy to see that it is impossible to find a fixed concurrency that works well on both sparse and dense tables, and everything in between. A low concurrency would be unbearably slow on a sparse table, as most requests would return very little data or no data at all. A high concurrency would overread on a dense table and most of the results would have to be discarded.
To overcome this, an adaptive algorithm is used on both the coordinator and the replicas. The algorithm works in an iterative fashion The first iteration starts with a concurrency of 1 and if the current iteration did not yield enough data to fill the page, the concurrency is doubled on the next iteration. This exponentially increasing concurrency works quite well for both dense and sparse tables. For dense tables, it will fill the page in a single iteration. For sparse tables, it will quickly reach high enough concurrency to fill the page in reasonable time.
Although this algorithm works reasonably well, it’s not perfect. It works best for dense tables where the page is filled in a single iteration. For tables that don’t have enough data to fill a page in a single iteration, it suffers from a cold-start on the beginning of each page while the concurrency is ramping up. The algorithm may also end up discarding data when the amount of data returned by the concurrent requests is above what was required to fill the page, which is quite common once the concurrency is above 1.
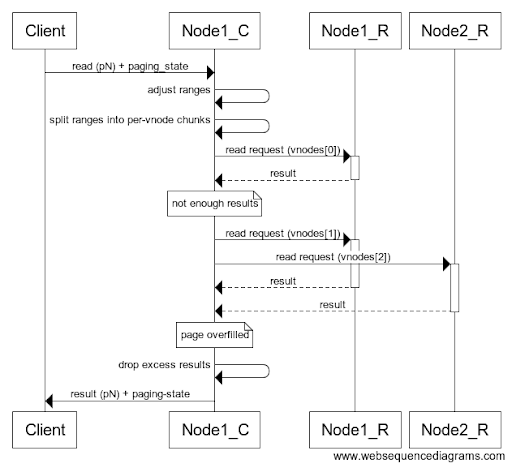
Figure 2: Flow diagram of an example of a page being filled on the coordinator. Note how the second iteration increases concurrency, reading two vnodes in parallel.
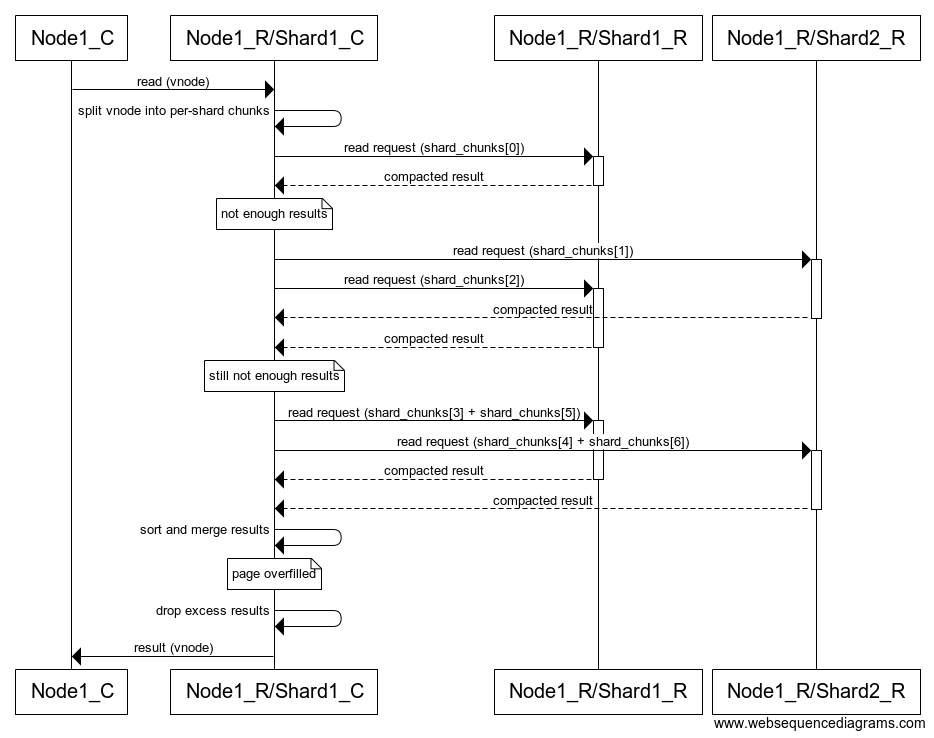
Figure 3: Flow diagram of an example of the stateless algorithm reading a vnode on the replica. Note the exponentially increasing concurrency. When the concurrency exceeds the number of shards, some shards (both in this example) will be asked for multiple chunks. When this happens the results need to be sorted and then merged as read ranges of the shards overlap.
Similarly to singular partition queries, the coordinator adjusts the read range (trim the part that was already read) at the start of each page and saves the position of the page at the end.
To reiterate, all this is completely stateless. Nothing is stored on the replicas or the coordinator. At the end of each page, all those objects created and all that work invested into serving the read is discarded, and on the next page it has to be done again from scratch. The only state the query has is the paging-state cookie, which stores just enough information so that the coordinator can compute the remaining range to-be-read on the beginning of each page.
Making Range Scans Stateful
To make range scans stateful we used the existing infrastructure, introduced for making singular partition queries stateful. To reiterate, the solution we came up with was to save the reading pipeline (queriers) on the replicas in a special cache, called the querier cache. Queriers are saved at the end of the page and looked up on the beginning of the next page and used to continue the query where it was left off. To ensure that the resources consumed by this cache stay bounded, it implements several eviction strategies. Queriers can be evicted if they stay in the cache for too long or if there is a shortage of resources.
Making range scans stateful proved to be much more challenging than it was for singular partition queries. We had to make significant changes to the reading pipeline on the replica to facilitate making it stateful. The vast majority of these changes revolved around designing a new algorithm, for reading all data belonging to a range from all shards, which can be suspended and resumed from this saved state later. The new algorithm is essentially a multiplexer that combines the output of readers opened on affected shards into a single stream. The readers are created on-demand when the shard is attempted to be read from the first time. To ensure that the read won’t stall, the algorithm uses buffering and read-ahead.
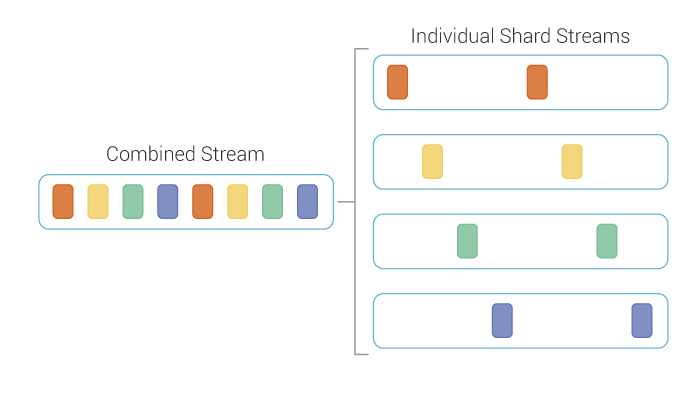
Figure 4: The new algorithm for reading the contents of a vnode on a replica.
This algorithm has several desirable properties with regards to suspending and resuming later. The most important of these is that it doesn’t need to discard data. Discarding data means that the reader, from which the data originates from, cannot be saved, because its read position will be ahead compared to the position where the read should continue from. While the new algorithm can also overread (due to the buffering and read-ahead) it will overread less, and since data is in raw form, it can be moved back to the originating readers, restoring them into a state as if they stopped reading right at reaching the limit. It doesn’t need complex exponentially increasing concurrency and the problems that come with it. No slow start and expensive sorting and merging for sparse tables.
When the page is filled only the shard readers are saved, buffered but unconsumed data is pushed back to them so there is no need to save the state of the reading algorithm. This ensures that the saved state, as a whole, is resilient to individual readers being evicted from the querier cache. Saving the state of the reading algorithm as well would have the advantage of not having to move already read data back to the originating shard when the page is over, at the cost of introducing a special state that, if evicted, would make all the shard readers unusable, as their read position would suddenly be ahead, due to data already read into buffers being discarded. This is highly undesirable, so instead we opted for moving buffered but unconsumed data back to the originating readers and saving only the shard readers. As a side note, saving the algorithm’s state would also tie the remaining pages of the query to be processed on the same shard, which is bad for load balancing.
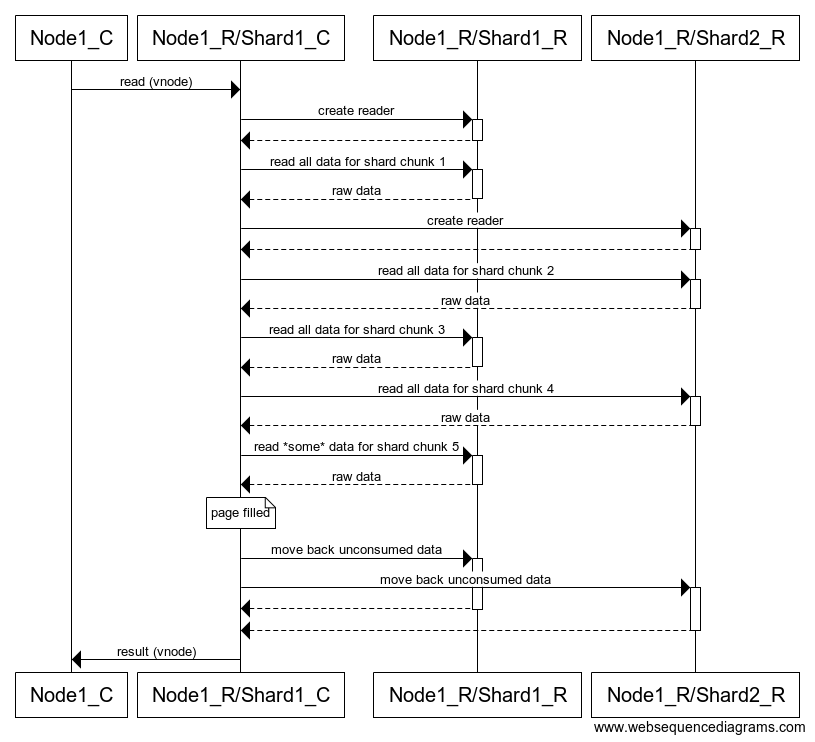
Figure 5: Flow diagram of an example of the new algorithm filling a page. Readers are created on demand. There is no need to discard data as when reading shard chunk 5, the read stops exactly when the page is filled. Data that is not consumed but is already in the buffers is moved back to the originating shard reader. Read ahead and buffering is not represented on the diagram to keep it simple.
Diagnostics
As stateful range scans use the existing infrastructure, introduced for singular partition queries, for saving and restoring readers, the effectiveness of this caching can be observed via the same metrics, already introduced in the More Efficient Query Paging with ScyllaDB 2.2 blog post.
Moving buffered but unconsumed data back to the originating shard can cause problems for partitions that contain loads of range tombstones. To help spot cases like this two new metrics are added:
multishard_query_unpopped_fragmentscounts the number of fragments (roughly rows) that had to be moved back to the originating reader.multishard_query_unpopped_bytescounts the number of bytes that had to be moved back to the originating reader.
These counters are soft badness counters, they will normally not be zero, but outstanding spikes in their values can explain problems and thus should be looked at when queries are slower than expected.
Saving individual readers can fail. Although this will not fail the read itself, we still want to know when this happens. To track these events two additional counters are added:
multishard_query_failed_reader_stopscounts the number of times stopping a reader, executing a background read-ahead when the page ended, failed.multishard_query_failed_reader_savescounts the number of times saving a successfully stopped reader failed.
These counters are hard badness counters, they should be zero at all times, any other value indicates either serious problems with the node (no available memory or I/O errors) or a bug.
Performance
To measure the performance benefits of making range scans stateful, we compared the recently released 2.3.0 (which doesn’t have this optimization) with current master, the future ScyllaDB Open Source 3.0.
We populated a cluster of 3 nodes with roughly 1TB of data then ran full scans against it. The nodes were n1-highmem-16 (16 vCPUs, 104GB memory) GCE nodes, with 2 local NVME SSD disks in RAID0. The dataset was composed of roughly 1.6M partitions, of which 1% was large (1M-20M), around 20% medium (100K-1M) and the rest small (>100K). We also fully compacted the table to filter out any differences due to differences in the effectiveness of compaction. The measurements were done with cache disabled.
We loaded the cluster with scylla-bench which implements an efficient range scan algorithm. This algorithm runs the scan by splitting the range into chunks and executing scans for these chunks concurrently. We could fully load the ScyllaDB Open Source 2.3.0 cluster with two loaders, adding a third loader resulted in reads timing out. In comparison the ScyllaDB Open Source 3.0 cluster could comfortably handle even five loaders, of course individual scans took more time compared to a run with two loaders.
After normalizing the results of the measurement we found that ScyllaDB Open Source 3.0 can handle 1.3X more reads/s than ScyllaDB Open Source 2.3.0. While this doesn’t sound very impressive, especially in light of the 2.5X improvements measured for singular partition queries, there is more to this than a single number.
In ScyllaDB Open Source 3.0, the bottleneck during range-scans moves from the disk to the CPU. This is because ScyllaDB Open Source 3.0 needs to read up to 39% less bytes and issue up to 73% less disk OPS per read, which allows the CPU cost of range scans to dominate the execution time.
In the case of a table that is not fully compacted, the improvements are expected to be even larger.
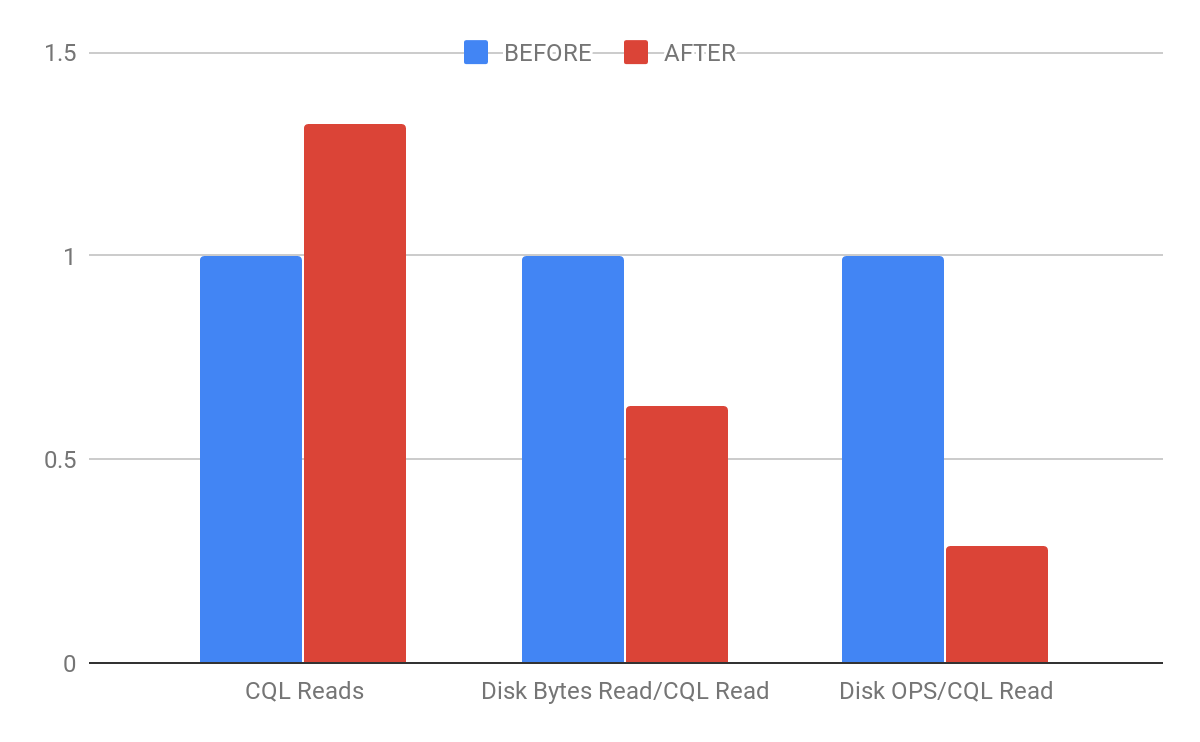
Figure 6: Chart for comparing normalized results for BEFORE (stateless scans) and AFTER (stateful scans).
Summary
Making range scans stateful delivers on the promise of reducing the strain on the cluster while also increasing the throughput. It is also evident that range scans are a lot more complex than singular partition queries and being stateless was a smaller factor in their performance as compared to singular partition queries. Nevertheless, the improvements are significant and they should allow you to run range scans against your cluster knowing that your application will perform better.
Range Scan Paging at ScyllaDB Summit 2018
At ScyllaDB Summit 2018, ScyllaDB engineer Botond Denes presented on How we Made Large Partition Scans Over Two Times Faster. Check our our Tech Talks section to see the full list of ScyllaDB Summit videos, to read his presentation slides, or watch the video embedded below.
Next Steps
- Learn more about ScyllaDB from our product page.
- Learn more about ScyllaDB Open Source Release 3.0.
- See what our users are saying about ScyllaDB.
- Download ScyllaDB. Check out our download page to run ScyllaDB on AWS, install it locally in a Virtual Machine, or run it in Docker.
Editor’s Note: This blog has been revised to reflect that this feature is now available in ScyllaDB Open Source Release 3.0.