



Streaming in ScyllaDB is an internal operation that moves data from node to node over a network. It is the foundation of various ScyllaDB cluster operations. For example, it is used by an “add node” operation to copy data to a new node in a cluster. It is also used by a “decommission” operation that removes a node from a cluster and streams the data it holds to the other nodes. Another example is a “rebuild” operation that rebuilds the data that a node should hold from replicas on other nodes. It is also used by a “repair” operation that is used to synchronize data between nodes.
In this blog post, we will take a closer look at how ScyllaDB streaming works in detail and how ScyllaDB Open Source 3.0’s new streaming improves streaming bandwidth by 240% and reduces the time it takes to perform a “rebuild” operation by 70%.
How ScyllaDB Streaming Works
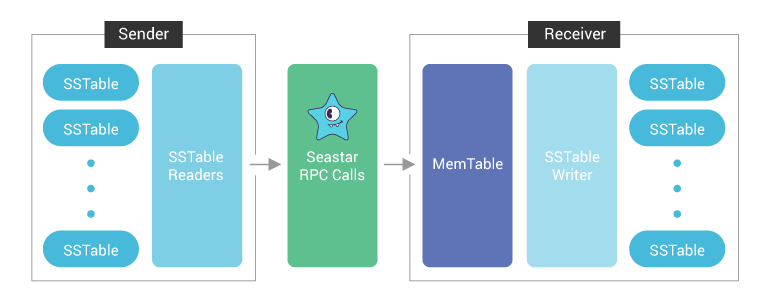
The idea behind ScyllaDB streaming is very simple. It’s all about reading data on one node, sending it to another node, and applying the data to disk. The diagram below shows the current path of data streaming. The sender creates sstable readers to read the rows from sstables on disk and sends them over the network. The receiver receives the rows from the network and writes them to the memtable. The rows in memtable are flushed into sstables periodically or when the memtable is full.
How We’re Improving ScyllaDB Streaming
You can see that on the receiver side, the data is applied to a memtable. In normal CQL writes, memtables help by sorting the CQL writes in the form of mutations. When the CQL writes in memtables are flushed to an SSTable, the mutations are sorted. However, when streaming, the mutations are already sorted. This is because they are in the same order when the sender reads the mutations from the SSTable. That’s great! We can remove the memtable from the process. The advantages are:
- Less memory consumption. The saved memory can be used to handle your CQL workload instead.
- Less CPU consumption. No CPU cycles are used to insert and sort memtables.
- Bigger SSTables and fewer compactions. Once the Memtable is full, it is flushed to an SSTable on disk. This happens during the whole streaming process repeatedly, thus generating many smaller SSTable files. This volume of SSTables adds pressure to compaction. By removing the memtable from the streaming process, we can write the mutations to a single SSTable.
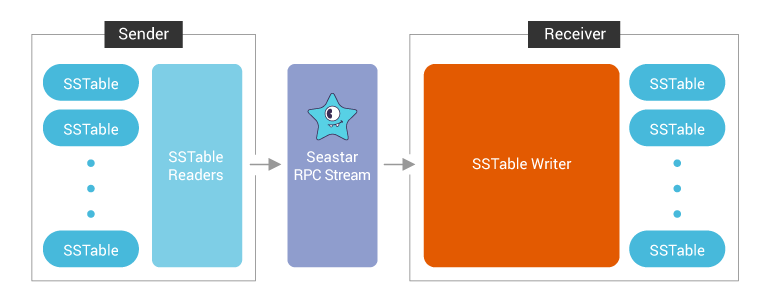
If we look at the sender and receiver as a sandwich, the secret sauce is the Seastar RPC framework. To send a row, a Seastar RPC call is invoked. The sender invokes the RPC call repetitively until all the rows are sent. The RPC call is used in request-response models. For streaming, the goal is to send a stream of data with higher throughput and less time and not to request the remote node to process the data and give a response with lower latency for each individual request. Thus, it makes more sense to use the newly introduced Seastar RPC Streaming interface. With the new Seastar RPC Streaming interface, we need to use the RPC call only once to get handlers called Sink and Source, dramatically reducing the number of RPC calls to send streaming data. On the sender side, the rows are pushed to the Sink handler, which sends them over the network. On the receiver side, the rows are pulled from the Source handler. It’s also worth noting that we can remove the batching at the streaming layer since the Seastar RPC streaming interface will do the batching automatically.
With the new workflow in place, the new streaming data path looks like this:
Performance Improvements
In this part, we will run tests to evaluate the streaming performance improvements. For this, we chose to use the rebuild operation that streams data from existing nodes to rebuild the database. Of course, the rebuild operation uses ScyllaDB streaming.
We created a cluster of 3 ScyllaDB nodes on AWS using i3.xlarge instance. (You can find the setup details at the end of this blog post.) Afterward, we created a keyspace with a replication factor of 3 and inserted 1 billion partitions to each of the 3 nodes. After the insertion, each node held 240 GiB of data. Lastly, we removed all the SSTables on one of the nodes and ran the “nodetool rebuild” operation. The sender nodes with the replicas send the data to the receiver node in parallel. Thus, in our test, there were two nodes streaming in parallel to the node that ran the rebuild operation.
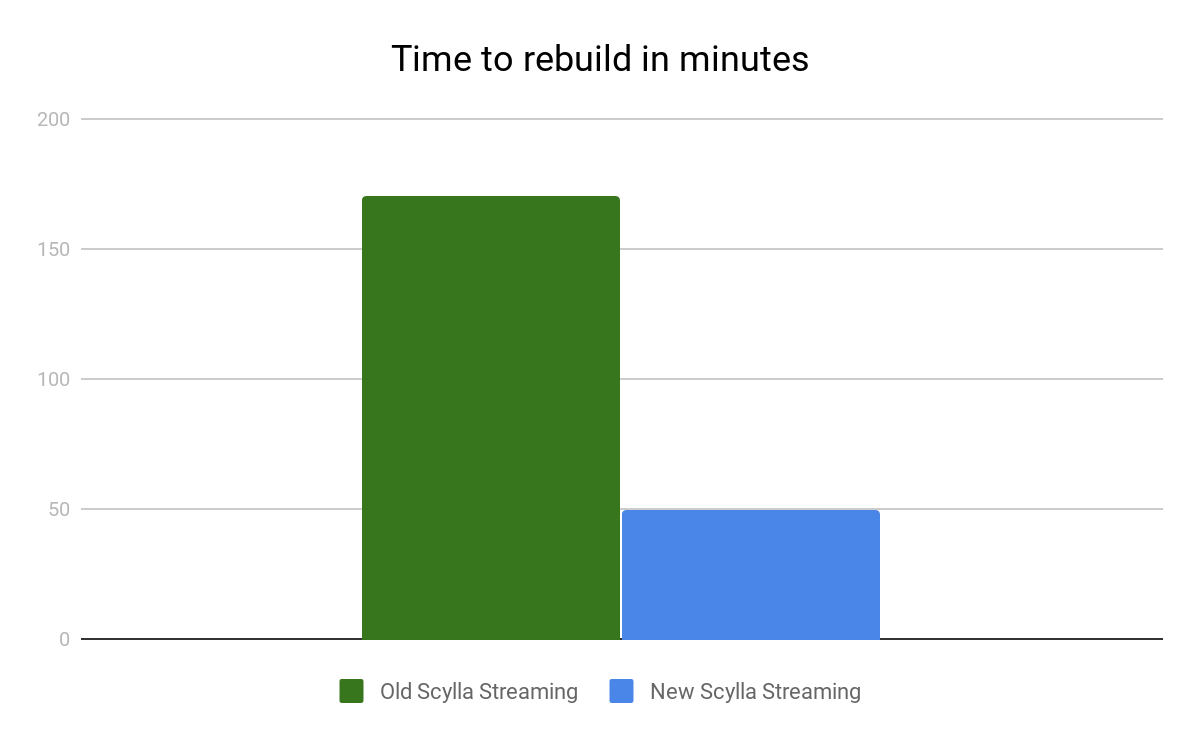
We compared the time it took to complete the rebuild operation and the streaming bandwidth on the receiver node before and after the new streaming changes.
| Tests | Old ScyllaDB Streaming | New ScyllaDB Streaming | Improvement |
| Time To Rebuild | 170 minutes | 50 minutes | 70% |
| Streaming Bandwidth | 36 MiB/s | 123 MiB/s | 240% |
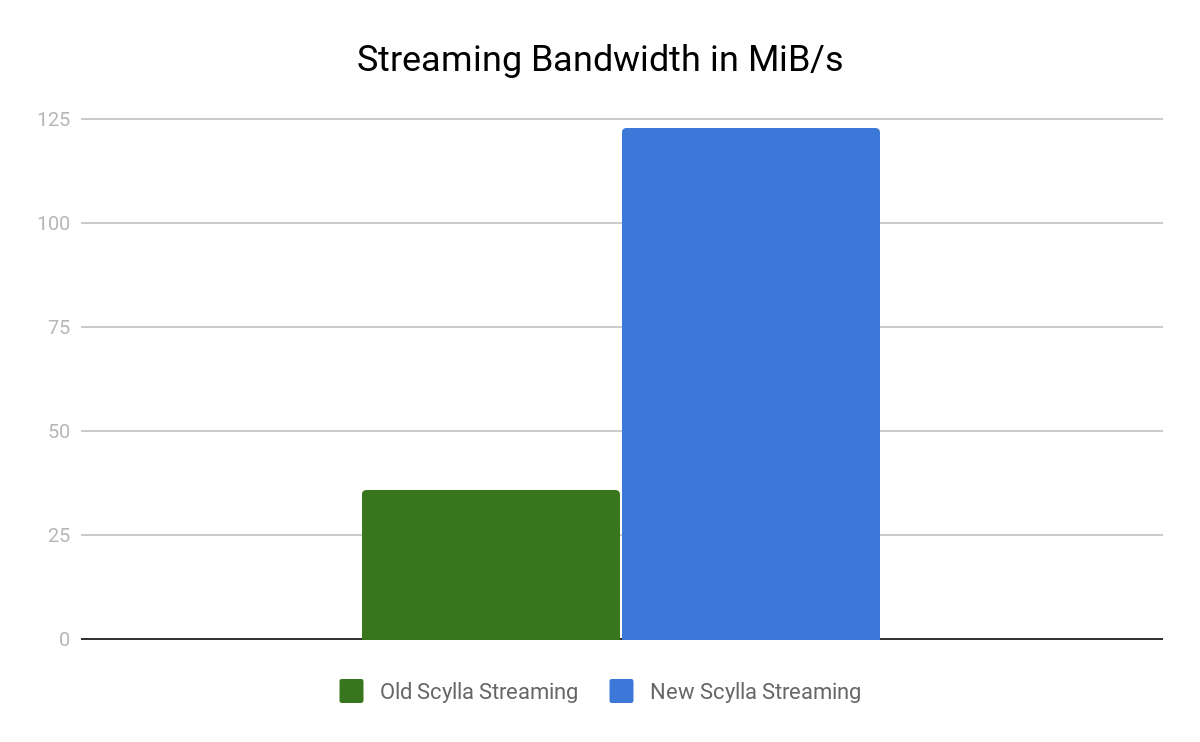 To look at the streaming performance on bigger machines, we did the above test again with 3 i3.8xlarge nodes. Since the instance is 8 times larger, we inserted 8 billion partitions to each of the 3 nodes. Each node held 1.89TiB of data. The test results are in the tables below.
To look at the streaming performance on bigger machines, we did the above test again with 3 i3.8xlarge nodes. Since the instance is 8 times larger, we inserted 8 billion partitions to each of the 3 nodes. Each node held 1.89TiB of data. The test results are in the tables below.
| Tests | Old ScyllaDB Streaming | New ScyllaDB Streaming | Improvement |
| Time To Rebuild | 218 minutes | 66 minutes | 70% |
| Streaming Bandwidth | 228 MiB/s | 765 MiB/s | 235% |
Conclusion
With our new ScyllaDB streaming, streaming data is written to the SSTable on disk directly and skips the memtable completely resulting in less memory and CPU usage and less compaction. The data is sent over network utilizing the new Seastar RPC Streaming interface.
The changes described here will be released in the upcoming ScyllaDB 3.0 release. It will make the ScyllaDB cluster operations like add new node, decommission node and repair node even faster.
You can follow our progress at implementing the streaming improvement on GitHub: #3591.
Next Steps
- ScyllaDB Summit 2018 is around the corner. Register now!
- Learn more about ScyllaDB from our product page.
- See what our users are saying about ScyllaDB.
- Download ScyllaDB. Check out our download page to run ScyllaDB on AWS, install it locally in a Virtual Machine, or run it in Docker.
Setup Details
DB Nodes: 3
Instance Type: i3.xlarge / i3.8xlarge
Replication Factor (RF): 3
Consistency Level (CL): QUORUM
Compaction Strategy: Size-Tiered
ScyllaDB Version: ScyllaDB master commit 31d4d37161bdc26ff6089ca4052408576a4e6ae7 with the new streaming disabled / enabled.
Streaming Repair at ScyllaDB Summit 2018
ScyllaDB engineer Asias He presented in depth on how streaming repairs were implemented, and the performance benefit it brings at ScyllaDB Summit 2018. Below is his ScyllaDB Summit video. You can also go to our Tech Talks section to see his presentation slides and all of the other videos and slides from the event.
Next Steps
- Learn more about ScyllaDB from our product page.
- Learn more about ScyllaDB Open Source Release 3.0.
- See what our users are saying about ScyllaDB.
- Download ScyllaDB. Check out our download page to run ScyllaDB on AWS, install it locally in a Virtual Machine, or run it in Docker.
Editor’s Note: This blog has been revised to reflect that this feature is now available in ScyllaDB Open Source Release 3.0.





