





FireEye (now Trellix) is a NASDAQ-traded cybersecurity firm that offers a broad portfolio ranging from a robust enterprise threat intelligence platform, hardware appliances to managed defenses and security consulting. Its customers span the gamut from global telecommunications giants to healthcare providers, universities to research facilities, financial institutions to school systems, municipalities, states, and government ministries.
In such an environment, where being wrong only once can lead to damaging and even dangerous breaches, security analytics must keep up with the velocity and volume of the threats faced at Internet scale.
At ScyllaDB Summit 2019, Rahul Gaikwad and Krishna Palati of the FireEye Threat Intelligence DevOps team gave an overview of their work and provided insights into the graph database architecture that drives their platform’s intelligence. That system is built on the open source JanusGraph database using ScyllaDB as the scalable, performant underlying storage engine.
Graph Data Analytics for Cybersecurity
Krishna gave background into the initial architecture of the system: it was a homegrown database written on top of PostgreSQL. This system was designed to organize and process threat intelligence data, to track threat groups, and manage a wide range of data objects. “In a nutshell the system is a bunch of nodes [vertices] and edges,” explained Krishna, “We have 500 million-plus nodes that we have aggregated over time, with over a billion edges between them. And each of these nodes has a hundred-plus properties for them.” Given this data complexity, FireEye analysts could ask over a trillion different questions of the data to provide insights to their customers.
“Each node represents a single object, event or evidence.” For example, a node could be an organization, an actor, a host (server), a file, or a fully qualified domain name (FQDN). “Edges present the relationships between the nodes.” So, for example, the relationship between a threat group and their location.
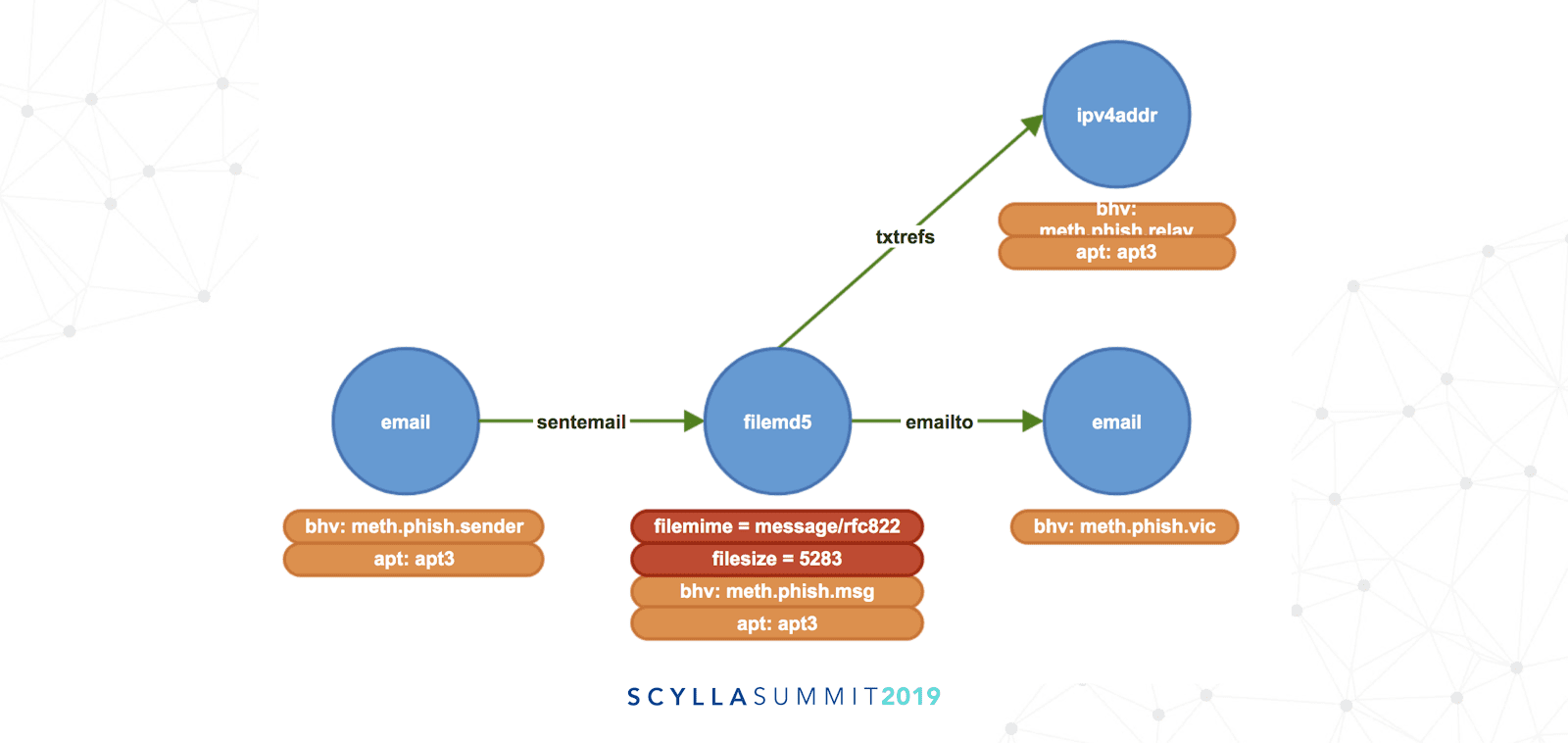
An example of a malware-infected email described as a graph model.
In the example graph above an email is a node (or vertex, symbolized by a blue circle) with an edge (green arrow) relating it as a sent email to a 128-bit Message Digest 5 (MD5) hash for a file attachment. This attachment is also set with the file’s MIME type and size in bytes (properties are red labels). Based on the MD5 this attachment was identified as an email phishing campaign threat (indicated by an orange box). FireEye also then tracks the target of the email and the IPv4 relay address from which the threat emanated. This email, the file attachment, and the source IP address are correlated to the group known as Advanced Persistent Threat 3 (APT3), also known as the “UPS Team.” (Click here to learn more about APT groups from FireEye.) All of this identification and attribution has to happen with an ultra-low-latency response time to proactively head off any malicious activity attempted against the target.
While the system originally created to conduct this work was operational on PostgreSQL, it presented a number of performance, scalability and stability challenges. Nor did it have the inherent high availability and distribution attributes required by FireEye for its 24x7x365 global operations.
The system was wildly popular, going from just a few to hundreds of internal users, putting a great deal of load on the system. Which meant FireEye was faced with the need to re-architect their system on a new technology base that could scale to meet its growing demands.
Evaluation
The FireEye team considered a range of graph database options, including OrientDB, Synapse and AWS Neptune before settling on JanusGraph through MoSCoW analysis. FireEye’s functional criteria included traversing speed, full/free text search, and concurrent user support. Non-functional criteria included requirements for highly availability and disaster recovery, plus a pluggable storage backend for flexibility. Their supportability criteria included the activity of the database user communities as well as the quality of documentation.
Beyond meeting the above requirements they appreciated the user-controllable indexing, schema management, triggers and OLAP capabilities for distributed graph processing.
Deciding on JanusGraph was not the end of FireEye’s evaluation. Since JanusGraph supports pluggable backend storage, FireEye then needed to compare the various options for a primary storage engine: ScyllaDB, Apache HBase, Apache Cassandra, or Oracle BerkeleyDB. (They chose Elasticsearch for free text search secondary data storage.)
For performance, FireEye was looking to avoid Java Virtual Machine (JVM) pauses due to Garbage Collection (GC). This weighed heavily against the Java-based databases (Cassandra and HBase).
What FireEye found was that ScyllaDB has easy cluster setup and was easy to manage in a cloud environment. They also appreciated its self-tuning and automatic load distribution and compression capabilities.
ScyllaDB: Providing Faster Threat Analytics
“Since our data represents threat activity we can get the answer… like who is the threat actor? What is the malware they are using? Who’s the victim?” Rahul observed. “Because a graph database tells the story about connecting the dots.”
![]()
FireEye used Gremlin queries to traverse their JanusGraph/ScyllaDB database to find particular nodes with certain properties, and from there to find all the connected nodes via specific edges. On the relational system it could take anywhere from 30 seconds to three minutes per workload query to return. By comparison a Gremlin query on JanusGraph/ScyllaDB traversed over 15,000 nodes, delivering the results in 332 milliseconds. Rahul was emphatic, “That was a game changer for us.”
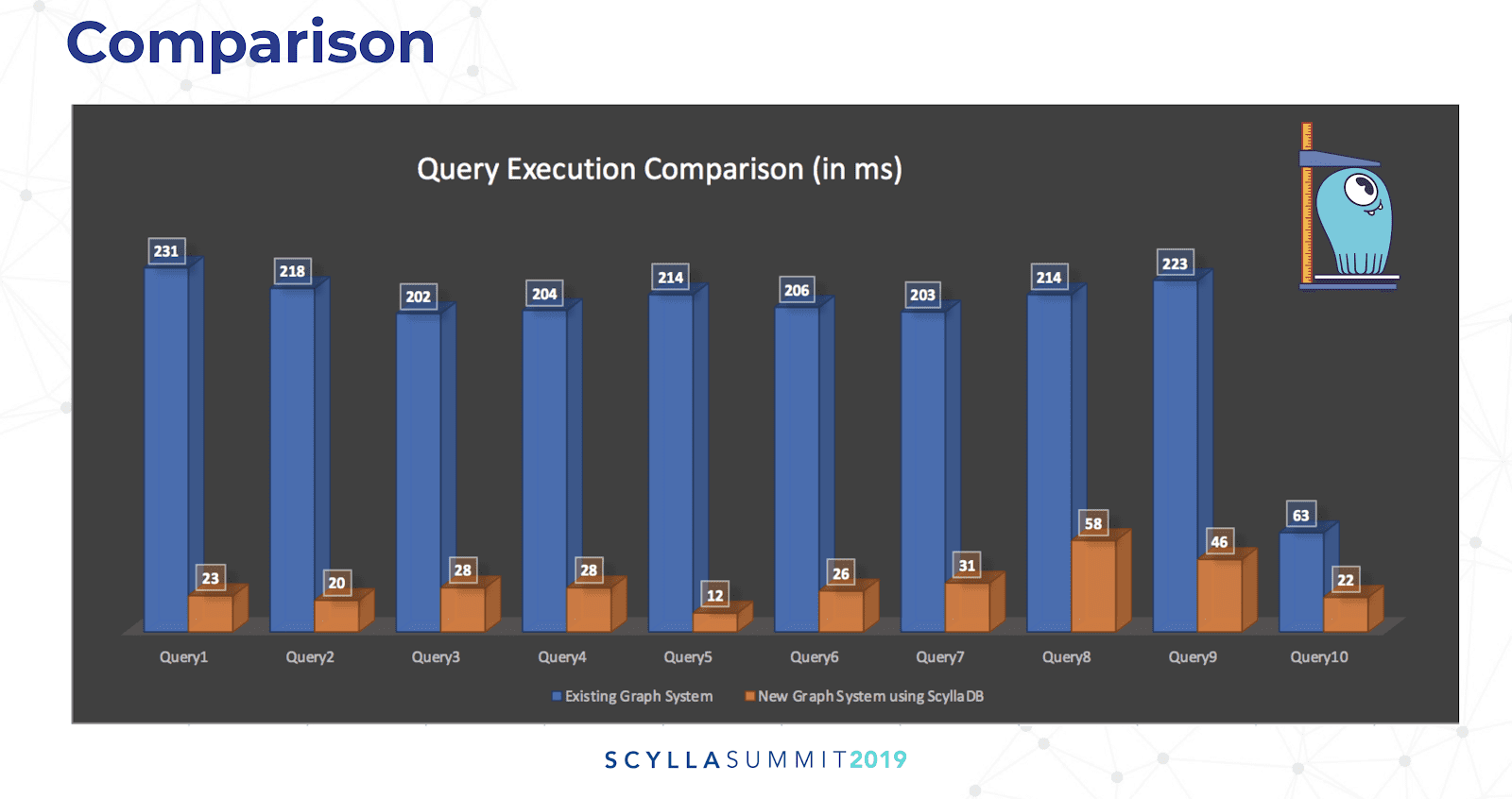
A comparison of query execution time for JanusGraph+ScyllaDB (in orange) versus the legacy system (in blue) built on top of PostgreSQL. In almost all cases the new system was faster by an order of magnitude (or more).
Architecture
FireEye implemented a robust architecture comprised of distributed NGINX web servers in front of AWS Elastic Load Balancing (ELB) cluster. This was connected on the back end to JanusGraph servers using ScyllaDB for primary data storage and Elasticsearch for full text search / secondary data storage. This was deployed across multiple availability zones to be protected from zone failures. FireEye maintains four clusters of seven nodes each (the separate clusters are for development, QA, staging and production). The instance types in AWS EC2 are the i3.8xlarge. All of this was protected by being deployed to its own Virtual Private Cloud (VPC), which required LDAP to access.
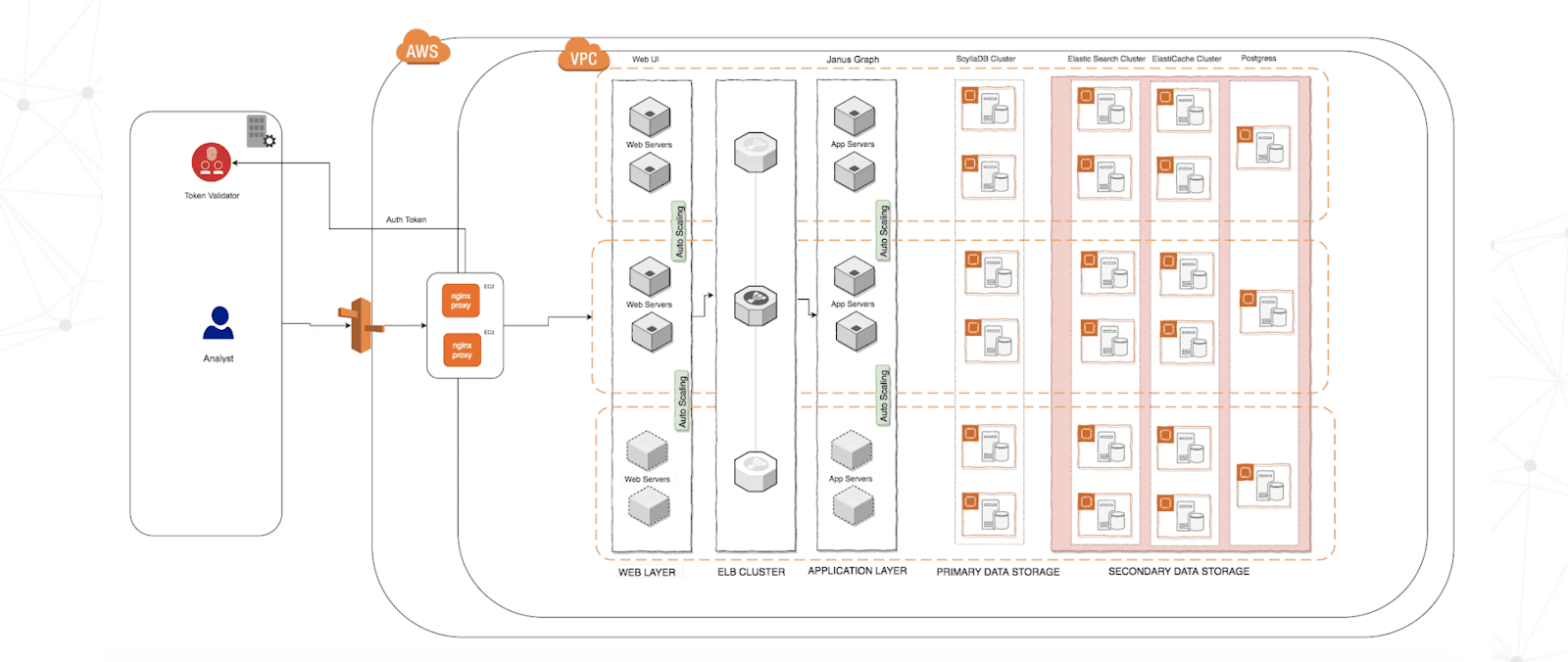
FireEye’s JanusGraph + ScyllaDB deployment in an AWS Virtual Private Cloud (VPC) secured through LDAP. Other components include NGINX web servers, AWS ELB, and Elasticsearch
FireEye ScyllaDB Cluster
| Node Type: AWS EC2 i3.8xlarge x 7 | Per Node | Total for Cluster |
| vCPUs | 32 | 224 |
| RAM (GiB) | 244 | 1,708 |
| Disk (TB) | 7.6 | 53.2 |
Though this was the initial deployment, Krishna pointed out that because ScyllaDB was so efficient FireEye was actually able to decommission a portion of their nodes and still maintain their high level of performance, saving them significant expenses.
You can watch the full presentation by clicking the image above, and check out the slides on our Tech Talks page.
Next Steps
If you wish to learn how to set up ScyllaDB and JanusGraph together, read this blog by Ryan Stauffer, another of our ScyllaDB Summit 2019 speakers, who provides step-by-step instructions and even sample source code. While it is written with Google Cloud Platform (GCP) in mind rather than AWS, many of the principles remain the same. And if you have any questions about deploying JanusGraph in your own operations, feel free to check out the JanusGraph users list, or for ScyllaDB-specific issues, join us in Slack.







