




Update 9/30/2025: For more on io_uring (and more by Glauber), see the talks at P99 CONF.
Things will never be the same again after the dust settles. And yes, I’m talking about Linux.
As I write this, most of the world is in lockdown due to COVID-19. It’s hard to say how things will look when this is over (it will be over, right?), but one thing is for sure: the world is no longer the same. It’s a weird feeling: it’s as if we ended 2019 in one planet and started 2020 in another.
While we all worry about jobs, the economy and our healthcare systems, one other thing that has changed dramatically may have escaped your attention: the Linux kernel.
That’s because every now and then something shows up that replaces evolution with revolution. The black swan. Joyful things like the introduction of the automobile, which forever changed the landscape of cities around the world. Sometimes it’s less joyful things, like 9/11 or our current nemesis, COVID-19.
I’ll put what happened to Linux in the joyful bucket. But it’s a sure revolution, one that most people haven’t noticed yet. That’s because of two new, exciting interfaces: eBPF (or BPF for short) and io_uring, the latter added to Linux in 2019 and still in very active development. Those interfaces may look evolutionary, but they are revolutionary in the sense that they will — we bet — completely change the way applications work with and think about the Linux Kernel.
In this article, we will explore what makes these interfaces special and so powerfully transformational, and dig deeper into our experience at ScyllaDB with io_uring.
How Did Linux I/O System Calls Evolve?
In the old days of the Linux you grew to know and love, the kernel offered the following system calls to deal with file descriptors, be they storage files or sockets:
Those system calls are what we call blocking system calls. When your code calls them it will sleep and be taken out of the processor until the operation is completed. Maybe the data is in a file that resides in the Linux page cache, in which case it will actually return immediately, or maybe it needs to be fetched over the network in a TCP connection or read from an HDD.
Every modern programmer knows what is wrong with this: As devices continue to get faster and programs more complex, blocking becomes undesirable for all but the simplest things. New system calls, like select() and poll() and their more modern counterpart, epoll() came into play: once called, they will return a list of file descriptors that are ready. In other words, reading from or writing to them wouldn’t block. The application can now be sure that blocking will not occur.
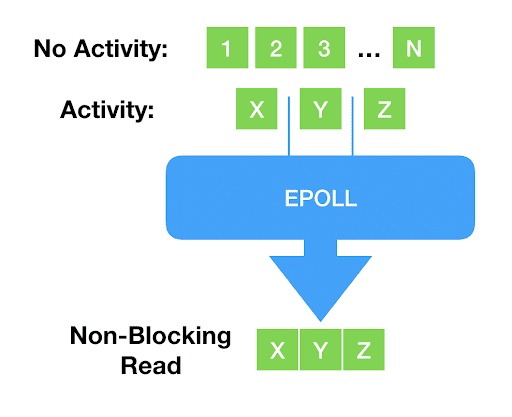
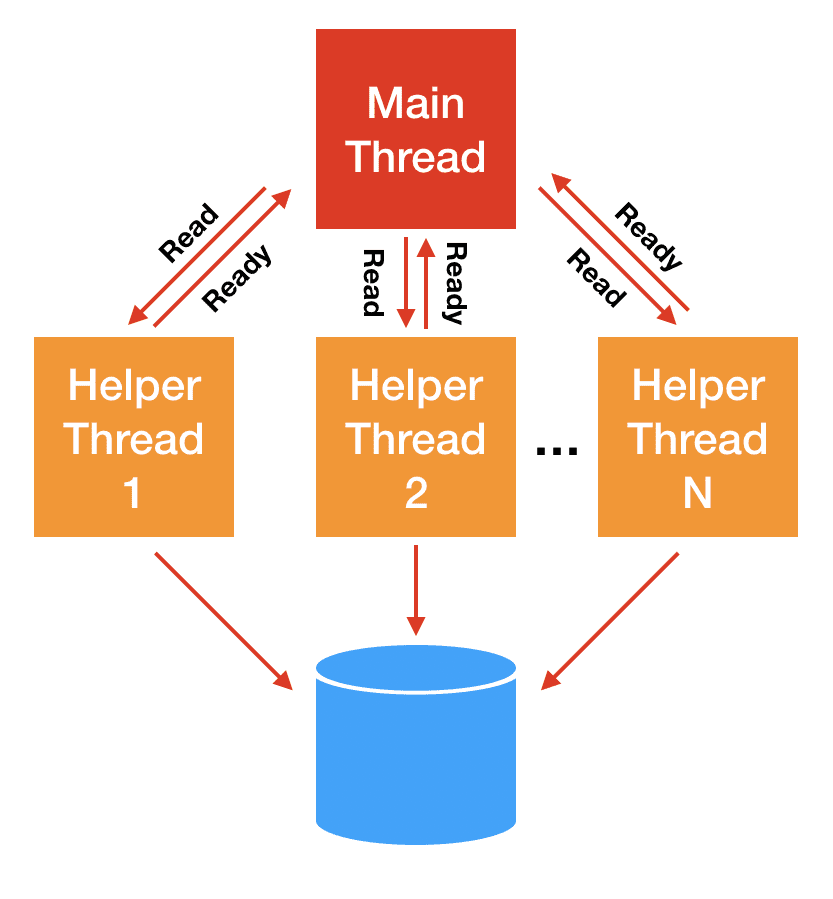
It’s beyond our scope to explain why, but this readiness mechanism really works only for network sockets and pipes — to the point that epoll() doesn’t even accept storage files. For storage I/O, classically the blocking problem has been solved with thread pools: the main thread of execution dispatches the actual I/O to helper threads that will block and carry the operation on the main thread’s behalf.
As time passed, Linux grew even more flexible and powerful: it turns out database software may not want to use the Linux page cache. It then became possible to open a file and specify that we want direct access to the device. Direct access, commonly referred to as Direct I/O, or the O_DIRECT flag, required the application to manage its own caches — which databases may want to do anyway, but also allow for zero-copy I/O as the application buffers can be sent to and populate from the storage device directly.
As storage devices got faster, context switches to helper threads became even less desirable. Some devices in the market today, like the Intel Optane series have latencies in the single-digit microsecond range — the same order of magnitude of a context switch. Think of it this way: every context switch is a missed opportunity to dispatch I/O.
With Linux 2.6, the kernel gained an Asynchronous I/O (linux-aio for short) interface. Asynchronous I/O in Linux is simple at the surface: you can submit I/O with the io_submit system call, and at a later time you can call io_getevents and receive back events that are ready. Recently, Linux even gained the ability to add epoll() to the mix: now you could not only submit storage I/O work, but also submit your intention to know whether a socket (or pipe) is readable or writable.
Linux-aio was a potential game-changer. It allows programmers to make their code fully asynchronous. But due to the way it evolved, it fell short of these expectations. To try and understand why, let’s hear from Mr. Torvalds himself in his usual upbeat mood, in response to someone trying to extend the interface to support opening files asynchronously:
So I think this is ridiculously ugly.
AIO is a horrible ad-hoc design, with the main excuse being “other, less gifted people, made that design, and we are implementing it for compatibility because database people — who seldom have any shred of taste — actually use it”.
— Linus Torvalds (on lwn.net)
First, as database people ourselves, we’d like to take this opportunity to apologize to Linus for our lack of taste. But also expand on why he is right. Linux AIO is indeed rigged with problems and limitations:
- Linux-aio only works for
O_DIRECTfiles, rendering it virtually useless for normal, non-database applications. - The interface is not designed to be extensible. Although it is possible — we did extend it — every new addition is complex.
- Although the interface is technically non-blocking, there are many reasons that can lead it to blocking, often in ways that are impossible to predict.
We can clearly see the evolutionary aspect of this: interfaces grew organically, with new interfaces being added to operate in conjunction with the old ones. The problem of blocking sockets was dealt with with an interface to test for readiness. Storage I/O gained an asynchronous interface tailored-fit to work with the kind of applications that really needed it at the moment and nothing else. That was the nature of things. Until… io_uring came along.
What Is io_uring?
io_uring is the brainchild of Jens Axboe, a seasoned kernel developer who has been involved in the Linux I/O stack for a while. Mailing list archaeology tells us that this work started with a simple motivation: as devices get extremely fast, interrupt-driven work is no longer as efficient as polling for completions — a common theme that underlies the architecture of performance-oriented I/O systems.
But as the work evolved, it grew into a radically different interface, conceived from the ground up to allow fully asynchronous operation. Its basic theory of operation is close to linux-aio: there is an interface to push work into the kernel, and another interface to retrieve completed work.
But there are some crucial differences:
- By design, the interfaces are designed to be truly asynchronous. With the right set of flags, it will never initiate any work in the system call context itself and will just queue work. This guarantees that the application will never block.
- It works with any kind of I/O: it doesn’t matter if they are cached files, direct-access files, or even blocking sockets. That is right: because of its async-by-design nature, there is no need for poll+read/write to deal with sockets. One submits a blocking read, and once it is ready it will show up in the completion ring.
- It is flexible and extensible: new opcodes are being added at a rate that leads us to believe that indeed soon it will grow to re-implement every single Linux system call.
The io_uring interface works through two main data structures: the submission queue entry (sqe) and the completion queue entry (cqe). Instances of those structures live in a shared memory single-producer-single-consumer ring buffer between the kernel and the application.
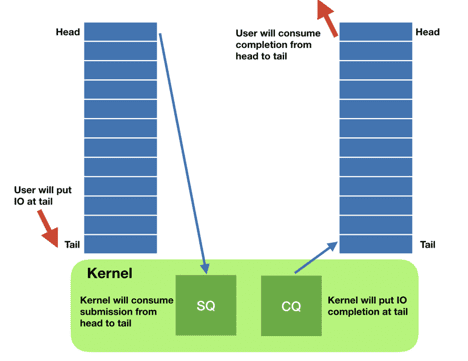
The application asynchronously adds sqes to the queue (potentially many) and then tells the kernel that there is work to do. The kernel does its thing, and when work is ready it posts the results in the cqe ring. This also has the added advantage that system calls are now batched. Remember Meltdown? At the time I wrote about how little it affected our ScyllaDB NoSQL database, since we would batch our I/O system calls through aio. Except now we can batch much more than just the storage I/O system calls, and this power is also available to any application.
The application, whenever it wants to check whether work is ready or not, just looks at the cqe ring buffer and consumes entries if they are ready. There is no need to go to the kernel to consume those entries.
Here are some of the operations that io_uring supports: read, write, send, recv, accept, openat, stat, and even way more specialized ones like fallocate.
This is not an evolutionary step. Although io_uring is slightly similar to aio, its extensibility and architecture are disruptive: it brings the power of asynchronous operations to anyone, instead of confining it to specialized database applications.
Our CTO, Avi Kivity, made the case for async at the Core C++ 2019 event. The bottom line is this; in modern multicore, multi-CPU devices, the CPU itself is now basically a network, the intercommunication between all the CPUs is another network, and calls to disk I/O are effectively another. There are good reasons why network programming is done asynchronously, and you should consider that for your own application development too.
It fundamentally changes the way Linux applications are to be designed: Instead of a flow of code that issues syscalls when needed, that have to think about whether or not a file is ready, they naturally become an event-loop that constantly add things to a shared buffer, deals with the previous entries that completed, rinse, repeat.
So, what does that look like? The code block below is an example on how to dispatch an entire array of reads to multiple file descriptors at once down the io_uring interface:
At a later time, in an event-loop manner, we can check which reads are ready and process them. The best part of it is that due to its shared-memory interface, no system calls are needed to consume those events. The user just has to be careful to tell the io_uring interface that the events were consumed.
This simplified example works for reads only, but it is easy to see how we can batch all kinds of operations together through this unified interface. A queue pattern also goes very well with it: you can just queue operations at one end, dispatch, and consume what’s ready at the other end.
Advanced Features
Aside from the consistency and extensibility of the interface, io_uring offers a plethora of advanced features for specialized use cases. Here are some of them:
- File registration: every time an operation is issued for a file descriptor, the kernel has to spend cycles mapping the file descriptor to its internal representation. For repeated operations over the same file,
io_uringallows you to pre-register those files and save on the lookup. - Buffer registration: analogous to file registration, the kernel has to map and unmap memory areas for Direct I/O.
io_uringallows those areas to be pre-registered if the buffers can be reused. - Poll ring: for very fast devices, the cost of processing interrupts is substantial.
io_uringallows the user to turn off those interrupts and consume all available events through polling. - Linked operations: allows the user to send two operations that are dependent on each other. They are dispatched at the same time, but the second operation only starts when the first one returns.
And as with other areas of the interface, new features are also being added quickly.
Performance
As we said, the io_uring interface is largely driven by the needs of modern hardware. So we would expect some performance gains. Are they here?
For users of linux-aio, like ScyllaDB, the gains are expected to be few, focused in some particular workloads and come mostly from the advanced features like buffer and file registration and the poll ring. This is because io_uring and linux-aio are not that different as we hope to have made clear in this article: io_uring is first and foremost bringing all the nice features of linux-aio to the masses.
We have used the well-known fio utility to evaluate 4 different interfaces: synchronous reads, posix-aio (which is implemented as a thread pool), linux-aio and io_uring. In the first test, we want all reads to hit the storage, and not use the operating system page cache at all. We then ran the tests with the Direct I/O flags, which should be the bread and butter for linux-aio. The test is conducted on NVMe storage that should be able to read at 3.5M IOPS. We used 8 CPUs to run 72 fio jobs, each issuing random reads across four files with an iodepth of 8. This makes sure that the CPUs run at saturation for all backends and will be the limiting factor in the benchmark. This allows us to see the behavior of each interface at saturation. Note that with enough CPUs all interfaces would be able to at some point achieve the full disk bandwidth. Such a test wouldn’t tell us much.
| backend | IOPS | context switches | IOPS ±% vs io_uring |
sync |
814,000 | 27,625,004 | -42.6% |
posix-aio (thread pool) |
433,000 | 64,112,335 | -69.4% |
linux-aio |
1,322,000 | 10,114,149 | -6.7% |
io_uring (basic) |
1,417,000 | 11,309,574 | — |
io_uring (enhanced) |
1,486,000 | 11,483,468 | 4.9% |
Table 1: performance comparison of 1kB random reads at 100% CPU utilization using Direct I/O, where data is never cached: synchronous reads, posix-aio (uses a thread pool), linux-aio, and the basic io_uring as well as io_uring using its advanced features.
We can see that as we expect, io_uring is a bit faster than linux-aio, but nothing revolutionary. Using advanced features like buffer and file registration (io_uring enhanced) gives us an extra boost, which is nice, but nothing that justifies changing your entire application, unless you are a database trying to squeeze out every operation the hardware can give. Both io_uring and linux-aio are around twice as fast as the synchronous read interface, which in turn is twice as fast as the thread pool approach employed by posix-aio, which is surprisingly at first.
The reason why posix-aio is the slowest is easy to understand if we look at the context switches column at Table 1: every event in which the system call would block, implies one additional context switch. And in this test, all reads will block. The situation is just worse for posix-aio. Now not only there is the context switch between the kernel and the application for blocking, the various threads in the application have to go in and out the CPU.
But the real power of io_uring can be understood when we look at the other side of the scale. In a second test, we preloaded all the memory with the data in the files and proceeded to issue the same random reads. Everything is equal to the previous test, except we now use buffered I/O and expect the synchronous interface to never block — all results are coming from the operating system page cache, and none from storage.
| Backend | IOPS | context switches | IOPS ±% vs io_uring |
sync |
4,906,000 | 105,797 | -2.3% |
posix-aio (thread pool) |
1,070,000 | 114,791,187 | -78.7% |
linux-aio |
4,127,000 | 105,052 | -17.9% |
io_uring |
5,024,000 | 106,683 | — |
Table 2: comparison between the various backends. Test issues 1kB random reads using buffered I/O files with preloaded files and a hot cache. The test is run at 100% CPU.
We don’t expect a lot of difference between synchronous reads and io_uring interface in this case because no reads will block. And that’s indeed what we see. Note, however, that in real life applications that do more than just read all the time there will be a difference, since io_uring supports batching many operations in the same system call.
The other two interfaces, however, suffer a big penalty: the large number of context switches in the posix-aio interface due to its thread pool completely destroys the benchmark performance at saturation. Linux-aio, which is not designed for buffered I/O, at all, actually becomes a synchronous interface when used with buffered I/O files. So now we pay the price of the asynchronous interface — having to split the operation in a dispatch and consume phase, without realizing any of the benefits.
Real applications will be somewhere in the middle: some blocking, some non-blocking operations. Except now there is no longer the need to worry about what will happen. The io_uring interface performs well in any circumstance. It doesn’t impose a penalty when the operations would not block, is fully asynchronous when the operations would block, and does not rely on threads and expensive context switches to achieve its asynchronous behavior. And what’s even better: although our example focused on random reads, io_uring will work for a large list of opcodes. It can open and close files, set timers, transfer data to and from network sockets. All using the same interface.
ScyllaDB and io_uring
Because ScyllaDB scales up to 100% of server capacity before scaling out, it relies exclusively on Direct I/O and we have been using linux-aio since the start.
In our journey towards io_uring, we have initially seen results as high as 50% better in some workloads. At closer inspection, that made clear that this is because our implementation of linux-aio was not as good as it could be. This, in my view, highlights one usually underappreciated aspect of performance: how easy it is to achieve it. As we fixed our linux-aio implementation according to the deficiencies io_uring shed light into, the performance difference all but disappeared. But that took effort, to fix an interface we have been using for many years. For io_uring, achieving that was trivial.
However, aside from that, io_uring can be used for much more than just file I/O (as already mentioned many times throughout this article). And it comes with specialized high performance interfaces like buffer registration, file registration, and a poll interface with no interrupts.
When io_uring’s advanced features are used, we do see a performance difference: we observed a 5% speedup when reading 512-byte payloads from a single CPU in an Intel Optane device, which is consistent with the fio results in Tables 1 and 2. While that doesn’t sound like a lot, that’s very valuable for databases trying to make the most out of the hardware.
|
|
Reading 512-byte buffers from an Intel Optane device from a single CPU. Parallelism of 1000 in-flight requests. There is very little difference between linux-aio and io_uring for the basic interface. But when advanced features are used, a 5% difference is seen. |
|
The io_uring interface is advancing rapidly. For many of its features to come, it plans to rely on another earth-shattering new addition to the Linux Kernel: eBPF.
What Is eBPF?
eBPF stands for extended Berkeley Packet Filter. Remember iptables? As the name implies, the original BPF allows the user to specify rules that will be applied to network packets as they flow through the network. This has been part of Linux for years.
But when BPF got extended, it allowed users to add code that is executed by the kernel in a safe manner in various points of its execution, not only in the network code.
I will suggest the reader to pause here and read this sentence again, to fully capture its implications: You can execute arbitrary code in the Linux kernel now. To do essentially whatever you want.
eBPF programs have types, which determine what they will attach to. In other words, which events will trigger their execution. The old-style packet filtering use case is still there. It’s a program of the BPF_PROG_TYPE_SOCKET_FILTER type.
But over the past decade or so, Linux has been accumulating an enormous infrastructure for performance analysis, that adds tracepoints and probe points almost everywhere in the kernel. You can attach a tracepoint, for example, to a syscall — any syscall — entry or return points. And through the BPF_PROG_TYPE_KPROBE and BPF_PROG_TYPE_TRACEPOINT types, you can attach bpf programs essentially anywhere.
The most obvious use case for this is performance analysis and monitoring. A lot of those tools are being maintained through the bcc project. It’s not like it wasn’t possible to attach code into those tracepoints before: Tools like systemtap allowed the user to do just that. But previously all that such probes could do was pass on information to the application in raw form which would then constantly switch to and from the kernel, making it unusably slow.
Because eBPF probes run in kernel space, they can do complex analysis, collect large swathes of information, and then only return to the application with summaries and final conclusions. Pandora’s box has been opened.
Here are some examples of what those tools can do:
- Trace how much time an application spends sleeping, and what led to those sleeps. (
wakeuptime) - Find all programs in the system that reached a particular place in the code (
trace) - Analyze network TCP throughput aggregated by subnet (
tcpsubnet) - Measure how much time the kernel spent processing softirqs (
softirqs) - Capture information about all short-lived files, where they come from, and for how long they were opened (
filelife)
The entire bcc collection is a gold mine and I strongly recommend the reader to take a look. But the savvy reader had already noticed by now that the main point is not that there are new tools. Rather, the point is that these tools are built upon an extensible framework that allows them to be highly specialized.
We could always measure network bandwidth in Linux. But now we can split it per subnet, because that’s just a program that was written and injected into the kernel. Which means if you ever need to insert specifics of your own network and scenario, now you can too.
Having a framework to execute code in the kernel goes beyond just performance analysis and debugging. We can’t know for sure how the marriage between io_uring and bpf will look like, but here are some interesting things that can happen:
io_uring supports linking operations, but there is no way to generically pass the result of one system call to the next. With a simple bpf program, the application can tell the kernel how the result of open is to be passed to read — including the error handling, which then allocates its own buffers and keeps reading until the entire file is consumed and finally closed: we can checksum, compress, or search an entire file with a single system call.
Where Is All This Going?
These two new features, io_uring and eBPF, will revolutionize programming in Linux. Now you can design apps that can truly take advantage of these large multicore multiprocessor systems like the Amazon i3en “meganode” systems, or take advantage of µsecond-scale storage I/O latencies of Intel Optane persistent memory.
You’re also going to be able to run arbitrary code in the kernel, which is hugely empowering for tooling and debugging. For those who have only done synchronous or POSIX aio thread pooling, there’s now a lot of new capabilities to take advantage of. These are exciting developments — even for those of you who are not database developers like us.
Originally published in The New Stack.



