




ScyllaDB Open Source 3.0 ships with a new format for on-disk representation, SSTable 3.0. In this article, we will discuss some of the benefits that emerge from the adoption of this format and the scenarios in which they apply. We will discuss the differences between the old and new formats, and demonstrate use cases in which the new format has significant advantages, and others where the advantages are much smaller.
This is truly a situation of “Your Mileage May Vary.” For example, in one test result below, we were able to show a 53% reduction in table size. Other use cases with extremely wide rows may see a savings of up to 80%. Yet in a second use case also shown below, we describe a situation with disk savings of only a few percentage points. Let’s explain why these results diverge so greatly starting with what’s changed in the SSTable format itself.
The SSTable Format
Sorted Strings Table (SSTable) is the persistent file format used by ScyllaDB and Apache Cassandra (as well as many other databases). ScyllaDB has always tried to maintain compatibility with Apache Cassandra, and file formats are no exception. SSTable is saved as a persistent, ordered, immutable set of files on disk. Immutable means SSTables are never modified; they are created by a MemTable flush and are deleted by a compaction.
Up to ScyllaDB 2.x, the supported formats were “ka” and “la“, where the first letter stands for the major version and the second letter stands for the minor version. The new SSTables 3.0 format is named “mc“, “m” being the next after “l” and “c” being the third minor version of the format.
SSTables 3.0 is a complete overhaul of the way data is stored and represented in the binary files, and in order to understand the advantages, we will first briefly go over the older formats and their disadvantages.
Old format structure
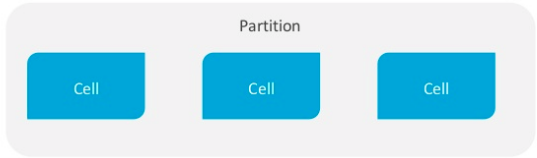
In the old format, each file contains a set of cells, with no notion of rows.

Each cell has a name and a value, where each cell name consists of the clustering key value and the column name, plus the column value.
Some of the more significant problems with this method of storing data:
First, there is a lot of data duplication. Cell name (which consists of the clustering key value and column name) is repeated across cells. This can cause very significant bloat, especially if the cell name is a long, meaningful set of values. Full TTLs and timestamps are also present in every cell, also increasing the on-disk space used. These are the most prominent issues with the old SSTables format.
Second, the old format is not aligned with CQL and how it represents data. Same-row cells are not grouped, so in order to read a row, we have to read irrelevant cells until we actually reach the end of the row, which results in performing redundant IO and CPU cycles.
The old SSTable format kept an index inside each partition if the partitions were over a certain size. Such an index was designed to make it more efficient to find a row inside a partition but the format was such that only linear searches were supported through this intra-partition index. In the mc file format, this index is now represented as a binary tree allowing for even faster searches within a wide partition.
What is added in SSTables 3.0 or the “mc” format
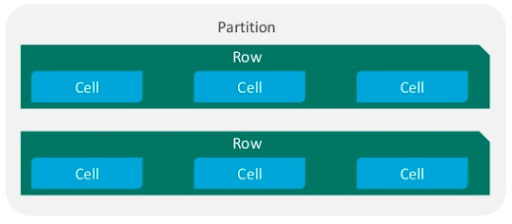
From the start, one major advantage of adopting the “mc” file format is that files from Apache Cassandra 3.x can now be directly imported into ScyllaDB, which means that ScyllaDB is fully compatible at the format level with Apache Cassandra 3.x. But beyond compatibility, the new file format design brings in a host of changes that directly affect users.
The new format introduces the notion of rows. Each partition consists of rows, and each row contains cells. This is aligned with CQL’s data representation. In order to read a row, we simply need to find and read it, instead of assembling it from disparate cells. Data is easier read, analysed and parsed. Also, Inherent row attributes have been added. Additional row metadata is added, so that it is directly possible find out whether the row is alive, expiring, etc. This is done in a specialized structure, and not as another cell, within the row.
Users will see significant disk space savings, depending on their schema, which can reach anywhere from just a few percent to 80%. We have taken the two extreme examples to show these differences in the benchmark presented below. In case of wide rows with long column names, the space savings will increase with the row count and column name length. The disk space savings introduced by the new format can be significant enough that we can now consider disabling compression in order to save some cycles and improve the latency.
In large part, the space savings come from the fact that column metadata is stored separately from the data file and no longer needs to be repeated. The benefits of this change go beyond space saving: In the old format, the SSTables files could not be made sense of without the table schema as well. The new format makes it possible now to read the data in SSTables files without consulting the schema, with all the data required available from the SSTables files directly. This allows easier parsing of the SSTables themselves when decoupled from the database in operations like backups/restores and migrations.
There are other improvements that contribute to space savings as well. Variable-length integers are introduced. A typical integer value uses 8 bytes, but that is wasteful when the actual value is small. variable-length integer can be stored in only 1-2 bytes, depending on its size.
Delta-based encoding has also been added. When we want to store, for example, timestamps for a particular row it isn’t necessary to store a timestamp for every cell. Instead the smallest timestamp is taken, and the rest can contain smaller delta values from the base value. The deltas are much smaller (less bytes) than a full timestamp, which saves additional disk space.
The new format supports binary searching through the index of rows inside the partition, instead of linear searches. This means the search will take O(log n) instead of O(n), which can be a huge performance gain for large partitions.
Learn More about the New SSTable 3.0 Format:
ScyllaDB’s Roadmap for the SSTables 3 Format
In the current version ScyllaDB Open Source 3.0:
To be conservative in rolling out this new feature, and to ease the transition from ScyllaDB Open Source 2.x to 3.0, by default SSTables 3.0 are disabled. In release 3.0, SSTables 3.0 need to be enabled by adding the following statement to /etc/scylla/scylla.yaml:
enable_sstables_mc_format: true
This will set the cluster so it reads and writes SSTables 3.0, with reading the old formats supported as well. Note that this feature is set only once per cluster, and is not configurable per keyspace or per table.
Old SSTables will be upgraded to the new format through compaction. Over time and with use, you will see your files converted to the “mc” format, as compactions are performed. New files will be created in the new format.
In a future ScyllaDB Open Source 3.x release:
Binary searching through promoted index on sliced reads will be supported.
A future version will also support caching of promoted index blocks, for additional performance improvement in wide partitions.
Lastly, SSTable 3.0 will be enabled by default. Read operations to tables in old formats will still be supported.
Testing the New Format
To provide a practical example of the space savings of the new SSTable 3.0 format, we have created a simple benchmark, which simulates two typical use-cases: a) a simple key-value schema designed to cause minimal bloat with “la” format SSTables (very short column names, no clustering key) and b) an IoT use case with a set of sensors storing data.
The goal is to demonstrate how space savings happen as a function of the schema. Since each cell in an “la” formatted file contains the column name and clustering keys, having longer column names and using clustering keys (also with long names) will cause each cell to take up more space. Using the old “la” format, the more numerous and longer-named columns are present, the bigger the bloat, and thus, by comparison, the new “mc” format should present larger savings. On the other hand, the less numerous and shorter-named the columns are, the less “la” format bloat should be present, and the smaller the difference between the disk-space used by the two formats.
In terms of disk space use, our two use cases should represent the opposite poles of the data stored by a ScyllaDB user. In both cases, compression has been disabled, in order to see actual data sizes on-disk.
Use case 1:
simple Key-Value data This format consists of a simple key-value schema, with the “key” column as the primary key, no clustering key and fixed key and value sizes. We populated the table with 15 million key-value sets.
CREATE TABLE kvexample (
key text,
val text,
PRIMARY KEY (key))
WITH compression = {}
Full yaml available here
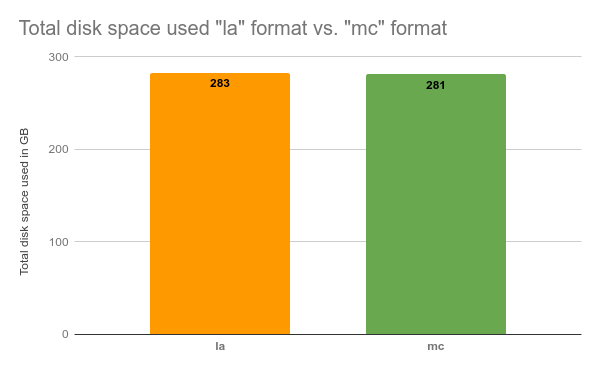
After generating the data, we could see only about 0.3% in disk space savings:
Results:
la format: 283GB
mc format: 281GB
Use case 2: IoT sensors data
This is a more complex schema, with a clustering key and long and meaningful column names, representing a large set sensors storing several columns of data. This is, of course, not the widest possible row we could come up with, but simply a reasonable approximation of a standard use case. As the schema grows, the disk space savings will also increase.
This is the cassandra-stress yaml, used for generating the IoT sensor data. It consists of 20 million sensors, over 4000 data points, with the the sensor as primary key and timestamp as the clustering key:
CREATE TABLE iotexample (
sensor uuid,
temperature int,
humidity int,
pressure float,
weathersource text,
timestamp timestamp,
PRIMARY KEY (sensor, timestamp))
WITH compression = {}
Full yaml available here
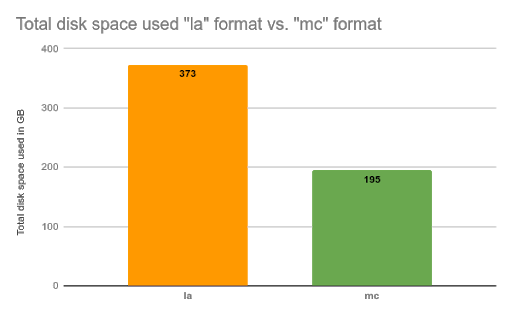
In this case, each cell in the old format will contain the sensor UUID and the timestamp, in addition to the cell value. In the new format, all that redundant data will be omitted. After generating the data, we saw 53% in disk space savings:
Results:
la format: total of 373GB
mc format: total of 195GB
In conclusion, the new SSTables 3.0 format comes with significant performance, compatibility and disk space advantages. However, it is important to keep in mind that not all workloads will benefit the same from its introduction. The main improvement is in disk space savings in wide rows, with long meaningful column names (the need to keep column names very short is now gone). Keep in mind that the more complex the schema, the more columns there are, the higher the space savings are expected to become. In this post, we have demonstrated a rather small schema with 53% total disk-space savings, and in different schemas we expect even higher figures, closer to the 80% mark and higher.
Now that ScyllaDB is Cassandra 3.0 compatible, it’s not the end of our SSTable 3.0 work. There will be additional performance improvements coming in ScyllaDB 3.x. So stay tuned!
Additional SSTables 3.0 format information:




