Opera is a growing brand in the web browser industry, with hundreds of millions of monthly active users. In particular, its rate of growth has been greatly accelerated by adoption across Africa, where it offers its own content and news hubs, making Opera a vital factor in a faster and more accessible Internet experience.
At ScyllaDB Summit 2019 we had the pleasure of hosting Rafal Furmanski and Piotr Olchawa of Opera, who explained how they use ScyllaDB to synchronize user data across different browsers and platforms.

Founded in 1995 in Oslo, Norway, Opera is now a NASDAQ-traded company (OPRA), with offices in Poland, Sweden and China. Its portfolio ranges from lightweight mobile browsers like Opera Mini, Opera for Android and Opera Touch to desktop browsers like Opera GX, designed for gamers looking to engage with their favorite brands and content.
Opera GX is Opera’s new web browser for gamers, with direct integrations for sites like Twitch, Discord, Reddit and YouTube, as well as features like WebRTC, crypto wallets, and VPNs.
Users want a seamless experience across their desktop and mobile devices. Opera Sync is the service Opera offers to ensure users can find what they are looking for and use it in a way they are familiar with across their many browsers. It synchronizes data, from favorite sites, bookmarks, and browser histories, to passwords and preferences. While not everyone who uses an Opera browser relies upon the Opera Sync feature, each month tens of millions of users depend on it to make their access across platforms fast, familiar and easy.
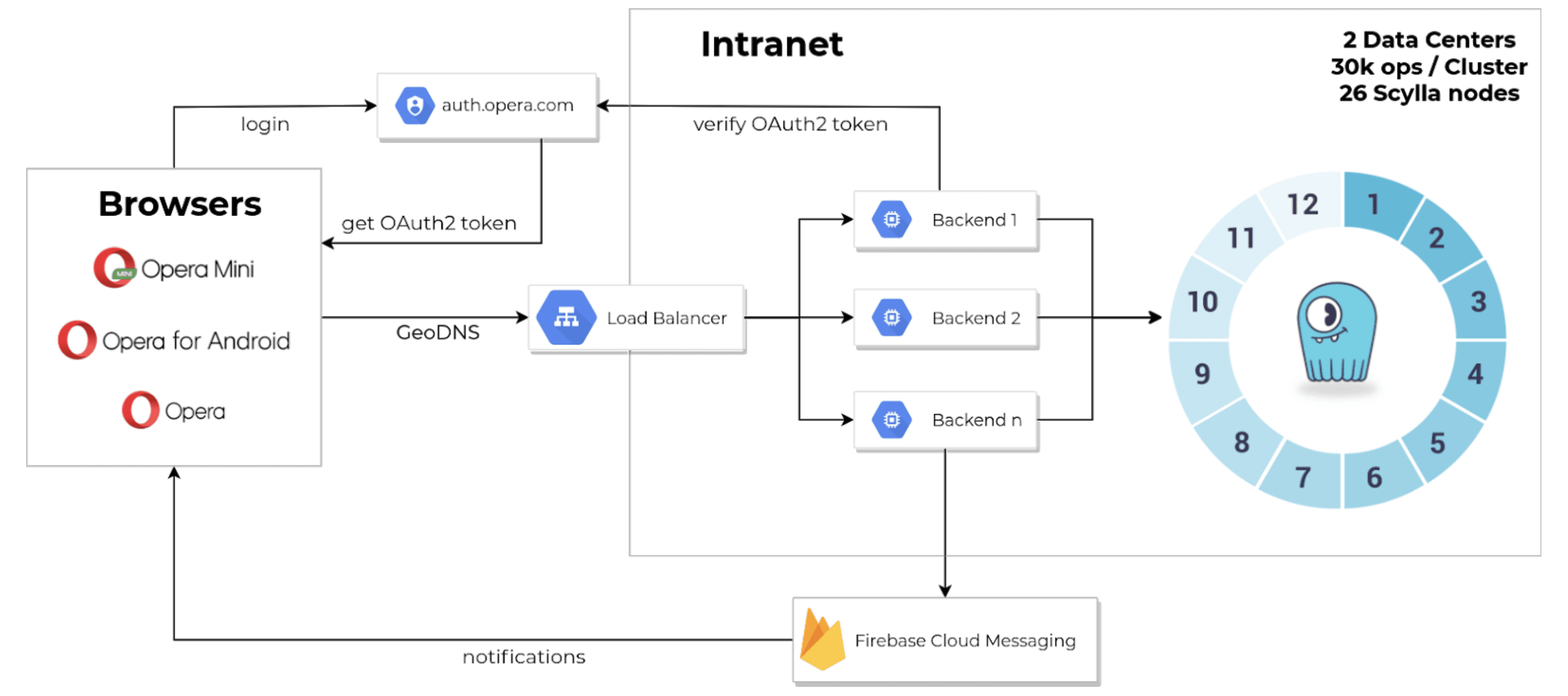
Opera Sync runs on Google Cloud Platform, using ScyllaDB as a backend source of truth data store on 26 nodes across two data centers; one in the U.S. and one in the Netherlands. It also uses Firebase Cloud Messaging to update mobile clients as changes occur.
Opera maintains a data model in ScyllaDB for what information needs to be shared across browsers. This is an example of a bookmark:
class Bookmark(Model):
user_id = columns.Text(partition_key=True)
version = columns.BigInt(primary_key=True, clustering_order='ASC')
id = columns.Text(primary_key=True)
parent_id = columns.Text()
position = columns.Bytes()
name = columns.Text()
ctime = columns.DateTime()
mtime = columns.DateTime()
deleted = columns.Boolean(default=False)
folder = columns.Boolean(default=False)
specifics = columns.Bytes()The userid is a partition key, so that all user data is collocated. The version and ID of the object then comprise the primary key of the object, and the version acts as a clustering key to enable queries such as selecting all bookmarks for a user of a particular version, or, in another case, changing or removing bookmarks of a certain version. (Versions, in Opera’s case, are set as precise timestamps.)
Benchmarking ScyllaDB vs. Cassandra
Opera had started using Cassandra with release 2.1, and according to Rafal, “we immediately got hit by some very, very ugly bugs like lost writes or ghost entries showing here and there. NullPointerExceptions, out-of-memory errors, crashes during repair. It was really a nightmare for us.”
“Besides all of these bugs, we observed very, very high read and write latencies,” Rafal noted that while general performance was okay, p99 latencies could be up to five seconds. Cassandra suffered Java Garbage Collection (GC) pauses with a direct correlation to uptime: the longer the node was up, the longer the GC pause. Cassandra gave Opera many “stop the world” problems. For instance, there were failures of the gossip and CQL binary protocols. Even if you used nodetool status, a node might not respond even if nodetool said that the node was okay.
Beyond this, Rafal recounted more headaches administering their Cassandra cluster: crashes without specific reasons, problems with bootstrapping new nodes, and never-ending repairs. “When you have to bootstrap a new node, it has to stream data from the other nodes. And if one of these nodes was down because of these problems I mentioned before, you basically had to start over with the bootstrap process.”
The “solutions” to these issues were often just exacerbating underlying problems, such as throwing more nodes to maintain uptime. This was because as soon as a node reached 700 gigabytes of data it became unresponsive. “We also tried to tune every piece of Java and Casandra config. If you come from the Cassandra world, you know that there are a lot of things to configure there.” They sought help from Cassandra gurus, but the problems Opera was having seemed unique to them. As a stop-gap fix, Rafal’s team even added a cron job to periodically restart Cassandra nodes that died.
While they were dealing with their production problems, Rafal encountered ScyllaDB at the Cassandra Summit where it debuted in 2015. Recalling sitting in the audience listening to Avi’s presentation Rafal commented, “I was really amazed about its shard-per-core architecture.” Opera’s barrier to adoption was the wait for counters to be production-ready (available in ScyllaDB 2.0 by late 2017). By July 2018 he created Opera’s first ScyllaDB cluster and performed benchmarks. Within a month, they made the decision to migrate all their user data to ScyllaDB. By May 2019, Opera decommissioned their last node of Cassandra.
The benchmark was performed on a 3-node bare-metal cluster with a mixed workload of 50% reads (GetUpdates) and 50% writes (Commits). These were the same node models Opera was using in production. Against this they ran a cassandra stress test with a bookmark table identical to how it was defined in production. Their results were clear: ScyllaDB sustained three times more operations per second, with far lower latencies — nearly an order of magnitude faster for p99.
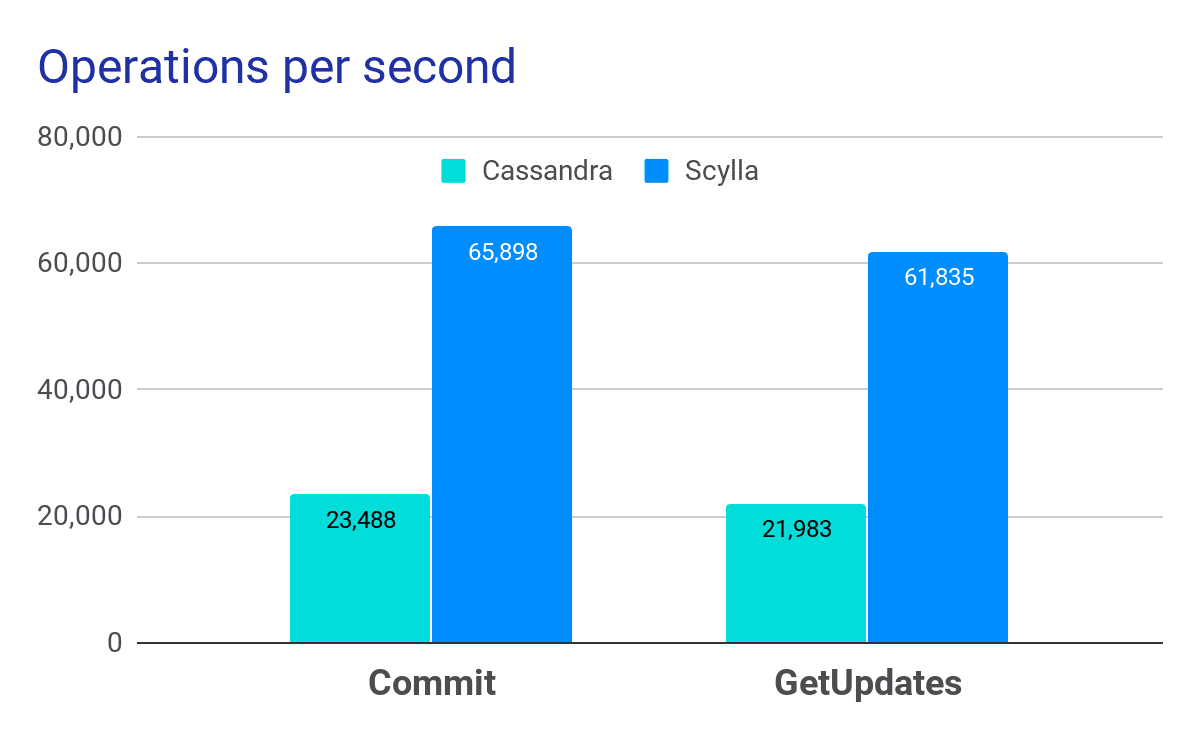
In Opera’s benchmarks, ScyllaDB provided nearly 3x the throughput of Apache Cassandra
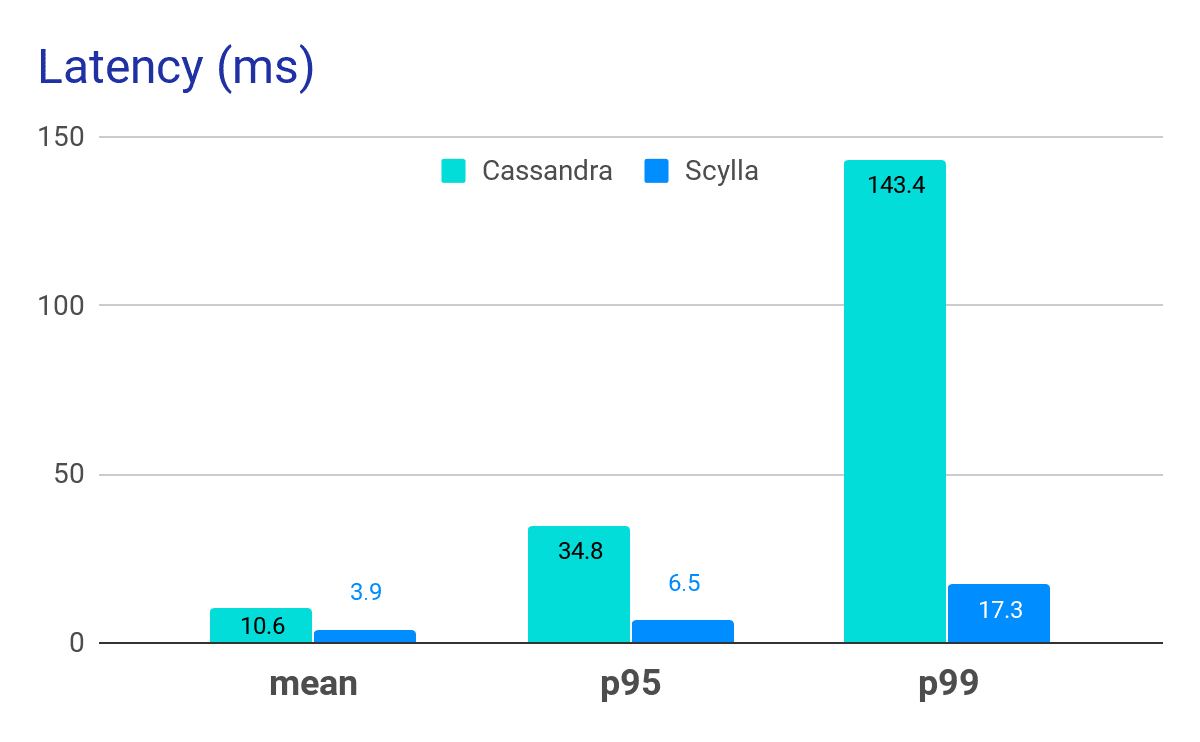
In Opera’s benchmarks, ScyllaDB’s mean (p50) latencies were less than half of Apache Cassandra, while long-tail (p99) latencies were 8x faster
In terms of one unanticipated bottleneck, Rafal was somewhat apologetic. “In the case of ScyllaDB, I was throttled by our one gig networking card. So these results could be even better.”
Migrating from Cassandra to ScyllaDB
Opera’s backend uses a Python and Django framework. So they modified their in-house library to connect to more than one database as a first step. They then prepared a 3-node cluster per datacenter, along with monitoring. They moved a few test users to ScyllaDB (specifically, Rafal and his coworkers) to see if it worked. Once they proved there were no errors, they began moving all new users to ScyllaDB (about 8,000 users daily, or a quarter million per month) keeping the existing users on Cassandra.
After a while, they migrated existing users to ScyllaDB and began decommissioning nodes and performing final migration cleanup. These were the settings for their Django settings.py script, showing how it could simultaneously connect to Cassandra and ScyllaDB, and how it was topology aware:
DATABASES = {
'cassandra': {...}
'scylla': {
'ENGINE': 'django_cassandra_engine',
'NAME': 'sync',
'HOST': SCYLLA_DC_HOSTS[DC],
'USER': SCYLLA_USER,
'PASSWORD': SCYLLA_PASSWORD,
'OPTIONS': {
'replication': {
'strategy_class': 'NetworkTopologyStrategy',
'Amsterdam': 3,
'Ashburn': 3
},
'connection': {..}
}
}
}To determine a user’s connection, and which database to connect to for a specific user, Opera used the following code, written in Python, which then queried a memcached cluster:
def get_user_store(user_id):
connection = UserStore.maybe_get_user_connection(user_id) # from cache
if connection is not None: # We know exactly which connection to use
with ContextQuery(UserStore, connection=connection) as US:
return US.objects.get(user_id=user_id)
else: # We have no clue which connection is correct for this user
try:
with ContextQuery(UserStore, connection='cassandra') as US:
user_store = US.objects.get(user_id=user_id)
except UserStore.DoesNotExist:
with ContextQuery(UserStore, connection='scylla') as US:
user_store = US.objects.get(user_id=user_id)
user_store.cache_user_connection()
return user_storeIn the first step, they tried to get the user’s connection from cache. If there was a hit on the cache they would safely return the database to use. If that query failed, they would then check the databases (Cassandra, then ScyllaDB, in order) and add which location the user data was located in to the cache for subsequent queries.
Their migration scripts had the requirement of being able to move the user data from Cassandra to ScyllaDB and back (in case they needed to revert for any reason). It also needed to perform a consistency check after migrating, and needed to support concurrency, so that multiple migration scripts could run in parallel. Additionally, it needed to “measure everything” — number of migrated users, migration time, migration errors (and the reasons), failures, etc.
Their migration script would be a free user (one not currently synchronizing data), and mark it for migration. It would set user_store_migration_pending = True, with a time-to-live (TTL). After the data was migrated and the consistency check was performed, they would remove the data from Cassandra and clear the connection cache. Then, finally, they would set the user_store_migration_pending = False.
During the migration Cassandra still provided problems, in the form of timeouts and unavailability. Even as the number of nodes and users active on that Cassandra cluster dwindled. Migrating huge accounts took time. Plus, during the migration period, the user was unable to utilize Opera sync.
After the migration, Opera was able to shrink their cluster from 32 nodes down to 26. However, they had plans to move to higher density nodes and shrink further down to 8 nodes. Their bootstrapping, which used to take days, now takes hours. Their performance, as stated before, was far faster, with a significant drop in latencies. But best of all, their team had “no more sleepless nights.”
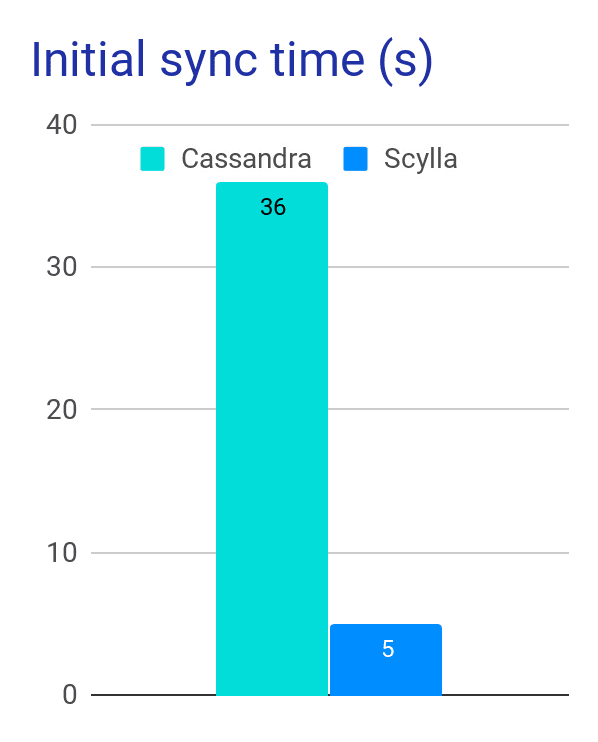
Initial sync time with ScyllaDB dropped 6x over Cassandra
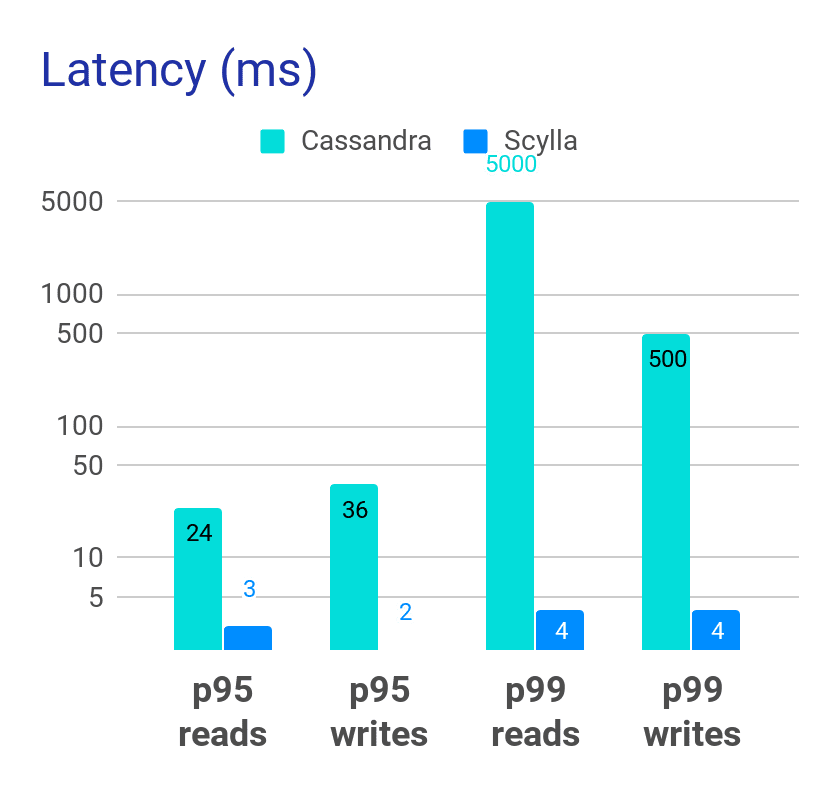
Long-tail latencies (p95 and p99), which had ranged as high as five seconds for reads on Cassandra, were now all safely in the single-digit millisecond range with ScyllaDB.
Next Steps
If you want to view the full video, you can watch it below, and read Opera’s slides in our Tech Talks page. In the full video you can hear more about Opera’s open source scylla-cli project for managing and repairing ScyllaDB, the monstrously fast and scalable NoSQL database, in a smart way.