June 28, 2022 Migration to ScyllaDB Cloud: Why Disney+ Hotstar Replaced Redis and Elasticsearch User Stories
March 11, 2021 QOMPLX: Using ScyllaDB with JanusGraph for Cybersecurity Events, User Stories, Integrations, News & Events
February 4, 2020 FireEye (Trellix): Providing Real-Time Threat Analysis using a Graph Database Events, User Stories, Integrations
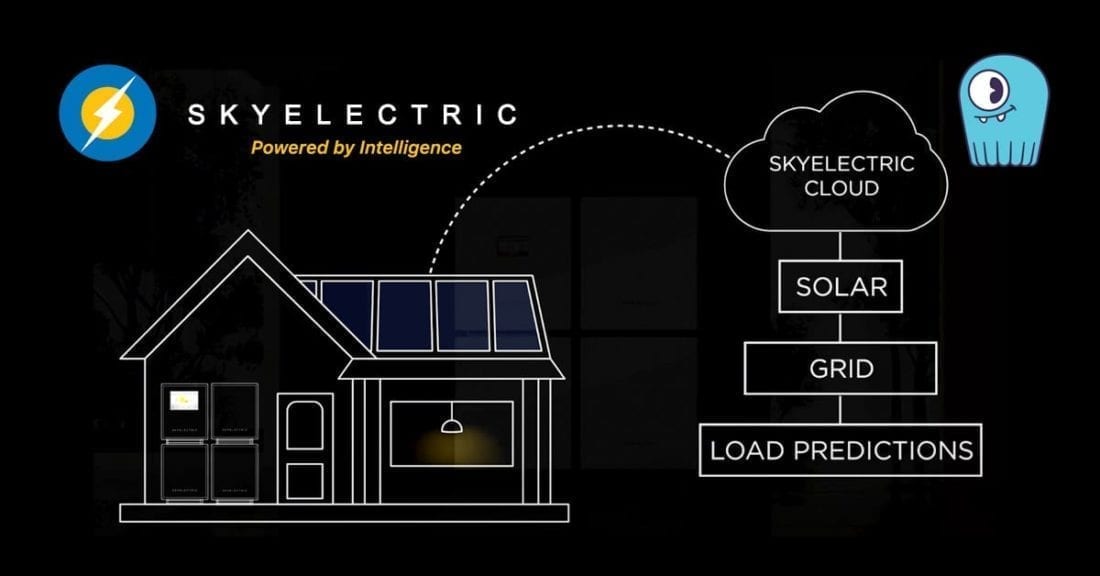
December 18, 2019 How SkyElectric Uses ScyllaDB to Power Its Smart Energy Platform Events, User Stories
October 29, 2019 Q&A with FireEye’s Rahul Gaikwad and Krishna Palati on Threat Analysis using Graph Databases Events
November 29, 2017 Zenly: The Journey for a Database Replacement Featured, User Stories, ScyllaDB Open Source