Today’s blog is a lesson taken from ScyllaDB University course tS110: The Mutant Monitoring System (MMS) A Graph Data System Powered by ScyllaDB and JanusGraph. Feel free to log in or register for ScyllaDB University to get credit for the course, and to see all the rest of the NoSQL database courses available.
TAKE THIS COURSE IN SCYLLADB UNIVERSITY
This lesson will teach you how to deploy a Graph Data System, using JanusGraph and ScyllaDB as the underlying data storage layer.
A graph data system (or graph database) is a database that uses a graph structure with nodes and edges to represent data. Edges represent relationships between nodes, and these relationships allow the data to be linked and for the graph to be visualized. It’s possible to use different storage mechanisms for the underlying data, and this choice affects the performance, scalability, ease of maintenance, and cost.
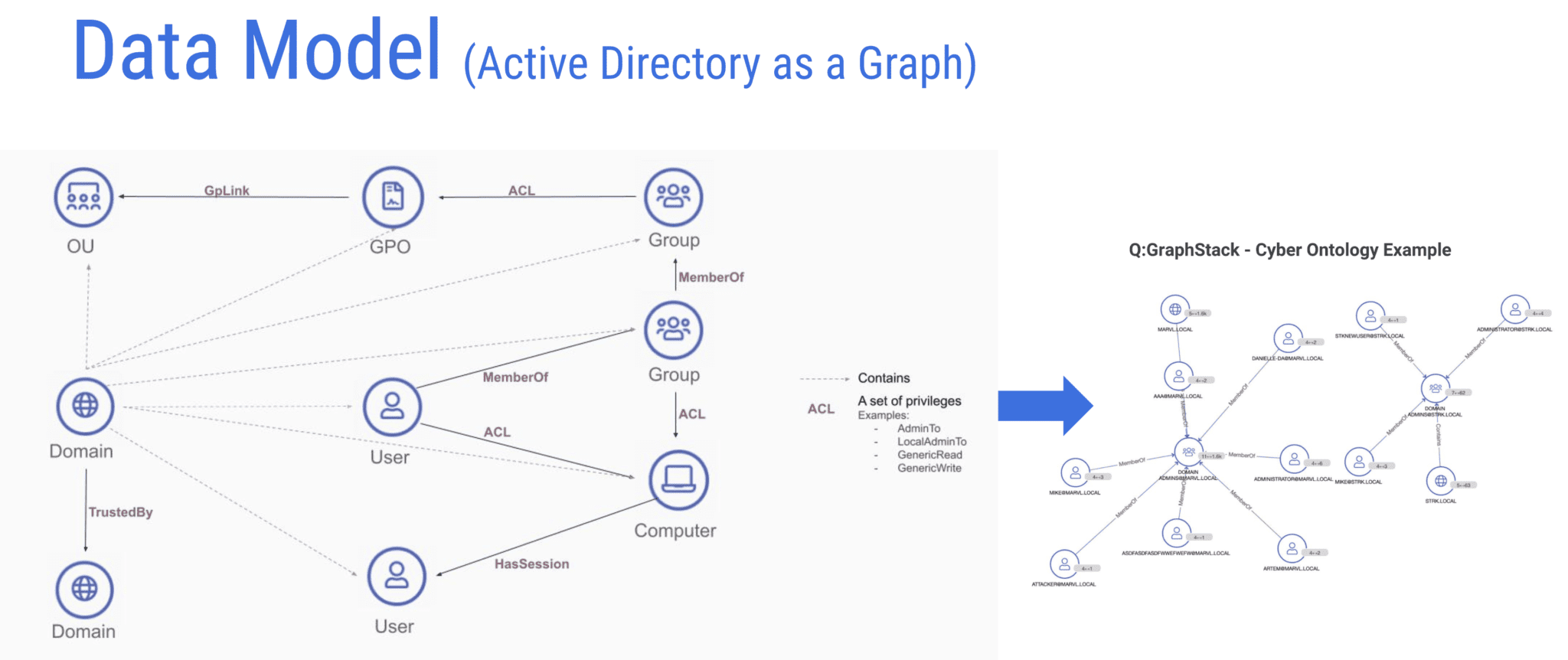
Some common use cases for graph databases are knowledge graphs, recommendation applications, social networks, and fraud detection.
JanusGraph is a scalable open-source graph database that’s optimized for storing and querying graphs containing hundreds of billions of vertices and edges distributed across a multi-machine cluster. It stores graphs in adjacency list format, which means that a graph is stored as a collection of vertices with their edges and properties.
JanusGraph natively supports the graph traversal language Gremlin. Gremlin is a part of Apache TinkerPop and is developed and maintained separately from JanusGraph. Many graph databases support it, and by using it, users avoid vendor lock-in as their applications can be migrated to other graph databases. You can learn more about the architecture on the JanusGraph Documentation page.
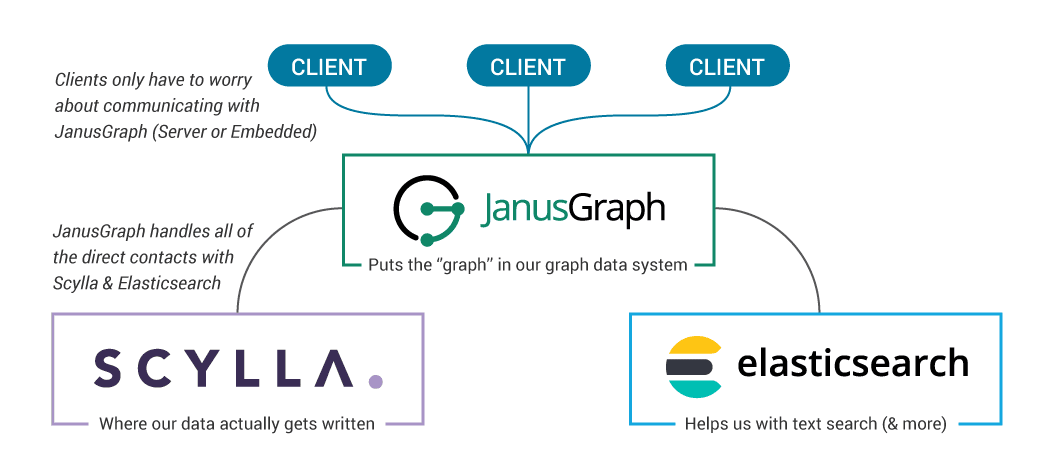
JanusGraphs supports ElasticSearch as an indexing backend. ElasticSearch is a search and analytics engine based on Apache Lucene. JanusGraph server (see Running the JanusGraph server) automatically starts a local ElasticSearch instance. It’s also possible to manually start a local ElasticSearch instance, however, this is not in the scope of this lesson. (However, see the documentation here.)
This lesson presents a step-by-step, hands-on example for deploying JanusGraph and performing some basic operations. Here are the main steps in the lesson:
- Spinning up a virtual machine on AWS
- Installing the prerequisites
- Running the JanusGraph server (using Docker)
- Running a Gremlin Console to connect to the new server (also in Docker)
- Spinning up a three-node Scylla Cluster and setting it as the data storage for the JanusGraph server
- Performing some basic graph operations
Since there are many moving parts to setting up JanusGraph and lots of options, the lesson goes over each step in the setup process. It uses AWS, but you can follow through with the example with another cloud provider or with a local machine.
Note that this example is for training purposes only and in production, things should be done differently. For example, each Scylla node should be run on a single server.
Launch an AWS EC2 Instance
Start by spinning up a t3.large Amazon Linux machine. From the EC2 console, select Instances and Launch Instances. In the first step choose the “Amazon Linux 2 AMI (HVM) – Kernel 5.10, SSD Volume Type – ami-008e1e7f1fcbe9b80 (64-bit x86)” AMI. In the second step, select t3.2xlarge. The reason for using an 2xlarge machine is that we’re running a few docker instances on the same server and it requires some resources. Change the storage to 16gb.
Once the machine is running, connect to it using SSH. In the command below, replace the path to your key pair and the public DNS name of your instance.
ssh -i ~/Downloads/aws/guy-janus.pem ec2-user@ec2-3-21-28-125.us-east-2.compute.amazonaws.comNext, make sure all your packages are updated:
sudo yum updateInstall Java
JanusGraph requires Java. To install Java and its prerequisites, run:
sudo yum install javaRun the following command to make sure the installation succeeded:
java -versionJanusGraph required the $JAVA_HOME environment variable to be set, and it also needs to be added to the $PATH. This isn’t automatically set when installing Java. So you’ll set it manually.
Locate the Java installation location by running:
sudo update-alternatives --config javaCopy the path to the Java Installation. Now, edit the .bashrc file found in the home directory of the ec2-user user, and add the two lines below to the file, replacing the path with the one you copied, without the /bin/java at the end.
export JAVA_HOME="/usr/lib/jvm/java-17-amazon-corretto.x86_64"PATH=$JAVA_HOME/bin:$PATHSave the file and run the following command:
source .bashrcMake sure the environment variables were set:
echo $JAVA_HOMEecho $PATHDocker Installation
Next, since you’ll be running JanusGraph and Scylla in Docker containers, install docker and its prerequisites:
sudo yum install dockerStart the Docker service:
sudo service docker startand (optionally) to ensure that the Docker daemon starts after each system reboot:
sudo systemctl enable dockerAdd the current user (ec2-user) to the docker group so you can execute Docker commands without using sudo:
sudo usermod -a -G docker ec2-userTo activate the changes to the groups, run:
newgrp dockerFinally, make sure that the Docker engine was successfully installed by running the hello-world image:
docker run hello-worldDeploying JanusGraph
There are a few options for how to deploy JanusGraph. In this lesson, you’ll deploy JanusGraph in a docker container to simplify the process. To learn about other ways of deploying JanusGraph read the Installation Guide.
Start a docker container for the JanusGraph server:
docker run --name janusgraph-default janusgraph/janusgraph:latestScyllaDB Data Storage Backend, Transactional and Analytical Workloads
In this part, you’ll spin up a three-node Scylla cluster which you’ll then use as a data storage backend for JanusGraph. The data storage layer for JanusGraph is pluggable. Some options for the data storage layer are Apache HBase, Google Cloud Bigtable, Oracle Berkeley DB Java Edition, Apache Cassandra, and ScyllaDB. The storage backend you use for your application is extremely important. By using ScyllaDB, some of the advantages you’ll get are low and consistent latency, high availability, up to x10 throughput, ease of use, and a highly scalable system.
A group at IBM compared using ScyllaDB as the JanusGraph storage backend vs. Apache Cassandra and HBase. They found that Scylla displayed nearly 35% higher throughput when inserting vertices than HBase and almost 3X Cassandra’s throughput. When inserting edges, Scylla’s throughput was 160% better than HBase and more than 4X that of Cassandra. In a query performance test, Scylla performed 72% better than Cassandra and nearly 150% better than HBase.
With graph data systems, just like with any data system, we can separate our workloads into two categories – transactional and analytical. JanusGraph follows the Apache TinkerPop project’s approach to graph computation. The Gremlin graph traversal language allows us to traverse a graph, traveling from vertex to vertex via the connecting edges. We can use the same approach for both OLTP and OLAP workloads.
Transactional workloads begin with a small number of vertices (found with the help of an index) and then traverse across a reasonably small number of edges and vertices to return a result or add a new graph element. We can describe these transactional workloads as graph local traversals. Our goal with these traversals is to minimize latency.
Analytical workloads require traversing a substantial portion of the vertices and edges in the graph to find our answer. Many classic analytical graph algorithms fit into this bucket. We can describe these as graph global traversals. Our goal with these traversals is to maximize throughput.
With our JanusGraph – Scylla graph data system, we can blend both capabilities. Backed by the high-IO performance of Scylla, we can achieve scalable, single-digit millisecond responses for transactional workloads. We can also leverage Spark to handle large-scale analytical workloads.
With the server running in the foreground in your previous terminal, open a new terminal window and connect to your VM like before:
ssh -i ~/Downloads/aws/guy-janus.pem ec2-user@ec2-3-21-28-125.us-east-2.compute.amazonaws.comUsing Docker, you’ll spin up a three-node Scylla cluster:
Start by setting up a Docker container with one node, called Node_X:
docker run --name Node_X -d scylladb/scylla:4.5.0 --smp 1 --overprovisioned 1 --memory 750MCreate two more nodes, Node_Y and Node_Z, and add them to the cluster of Node_X. The command “$(docker inspect –format='{{ .NetworkSettings.IPAddress }}’ Node_X)” translates to the IP address of Node_X:
docker run --name Node_Y -d scylladb/scylla:4.5.0 --seeds="$(docker inspect --format='{{ .NetworkSettings.IPAddress }}' Node_X)" --smp 1 --overprovisioned 1 --memory 750M
docker run --name Node_Z -d scylladb/scylla:4.5.0 --seeds="$(docker inspect --format='{{ .NetworkSettings.IPAddress }}' Node_X)" --smp 1 --overprovisioned 1 --memory 750MWait a minute or so and check the node status:
docker exec -it Node_Z nodetool statusOnce all nodes are in up status (UN), continue to the next step.
Gremlin Console and Testing
Gremlin is a graph traversal query language developed by Apache TinkerPop. It works for OLTP and OLAP type traversals and supports multiple graph systems. JanusGraph, Neo4j, and Hadoop are some examples.
Run the Gremlin console, and link it to the already running server container:
docker run --rm --link janusgraph-default:janusgraph -e GREMLIN_REMOTE_HOSTS=janusgraph -it janusgraph/janusgraph:latest ./bin/gremlin.shNow in the gremlin console, connect to the server:
:remote connect tinkerpop.server conf/remote.yamlNext, set Scylla as the data storage and instantiate our JanusGraph object in the console with a JanusGraphFactory. Make sure to replace the IP in the command below with the IP of one of your Scylla cluster nodes:
JanusGraph graph = JanusGraphFactory.build().set("storage.backend", "cql").set("storage.hostname", "172.17.0.4").open();g = TinkerGraph.open().traversal()Now we can perform some basic queries. Make sure the graph is empty to begin with:
g.V().count()Add two vertices
g.addV('person').property('name', 'guy')
g.addV('person').property('name', 'john')And make sure they were added:
g.V().values('name')Summary
In this lesson, you learned how to deploy JanusGraph with Scylla as the underlying database. There are different ways to deploy JanusGraph and Scylla. To simplify the lesson, it uses Docker. The main steps were: Spinning up a virtual machine on AWS, running the JanusGraph server, running a Gremlin Console to connect to the new server, spinning up a three-node Scylla cluster, and setting it as the data storage for the JanusGraph server, and performing some basic graph operations.
You can learn more about using JanusGraph with Scylla from this real-world Cybersecurity use case. Another use case is Zeotap, which built a graph of twenty billion IDs on Scylla and JanusGraph, which they use for their customer intelligence platform. In terms of performance, a group at IBM compared using ScyllaDB as the JanusGraph storage backend vs. Apache Cassandra and HBase. They found that when inserting vertices, Scylla displayed nearly 35% higher throughput than HBase and almost 3X Cassandra’s throughput. Scylla’s throughput was 160% better than HBase and more than 4X that of Cassandra when inserting edges. Scylla performed 72% better than Cassandra in a query performance test and nearly 150% better than HBase.
These ScyllaDB benchmarks compare its performance to Cassandra, DynamoDB, Bigtable, and CockroachDB.