




Global cybersecurity leader Palo Alto Networks processes terabytes of network security events each day. They analyze, correlate, and respond to millions of events per second– many different types of events, using many different schemas, reported by many different sensors and data sources. One of their many challenges is understanding which of those events actually describe the same network “story” from different viewpoints.
Accomplishing this would traditionally require both a database to store the events and a message queue to notify consumers about new events that arrived into the system. But, to mitigate the cost and operational overhead of deploying yet another stateful component to their system, Palo Alto Networks’ engineering team decided to take a different approach.
This blog explores why and how Palo Alto Networks completely eliminated the MQ layer for a project that correlates events in near real time. Instead of using Kafka, Palo Alto Networks decided to use their existing low-latency distributed database (ScyllaDB) as an event data store and as a message queue – enabling them to eliminate Kafka. It’s based on the information that Daniel Belenky, Principal Software Engineer at Palo Alto Networks, recently shared at ScyllaDB Summit.
Watch On Demand
The Palo Alto Networks session from ScyllaDB Summit 2022 is available for you to watch right now on demand. You can also watch all the rest of the ScyllaDB Summit 2022 videos and check out the slides here.
Background: Events, Events Everywhere
Belenky’s team develops the initial data pipelines that receive the data from endpoints, clean the data, process it, and prepare it for further analysis in other parts of the system. One of their top priorities is building accurate stories. As Belenky explains, “We receive multiple event types from multiple different data sources. Each of these data sources might be describing the same network session, but from different points on the network. We need to know if multiple events – say, one event from the firewall, one event from the endpoint, and one event from the cloud provider– are all telling the same story from different perspectives.” Their ultimate goal is to produce one core enriched event that comprises all the related events and their critical details.
For example, assume a router’s sensor generates a message (here, it’s two DNS queries). Then, one second later, a custom system sends a message indicating that someone performed a log-in and someone else performed a sign-up. After 8 minutes, a third sensor sends another event: some HTTP logs. All these events which arrived at different times might actually describe the same session and the same network activity.
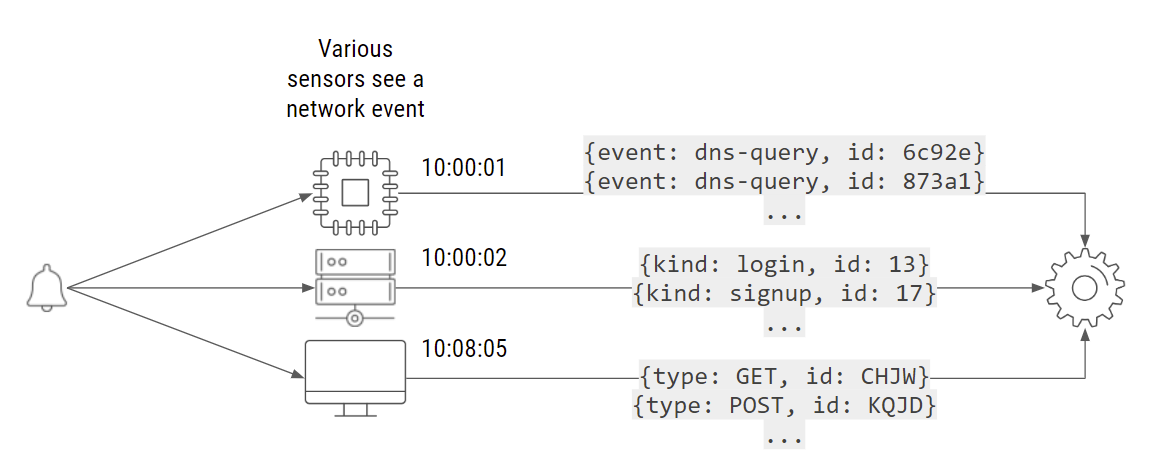
Different events might describe the same network activity in different ways
The system ingests the data reported by the different devices at different times and normalizes it to a canonical form that the rest of the system can process. But there’s a problem: this results in millions of normalized but unassociated entries. There’s a ton of data across the discrete events, but not (yet) any clear insight into what’s really happening on the network and which of those events are cause for concern.
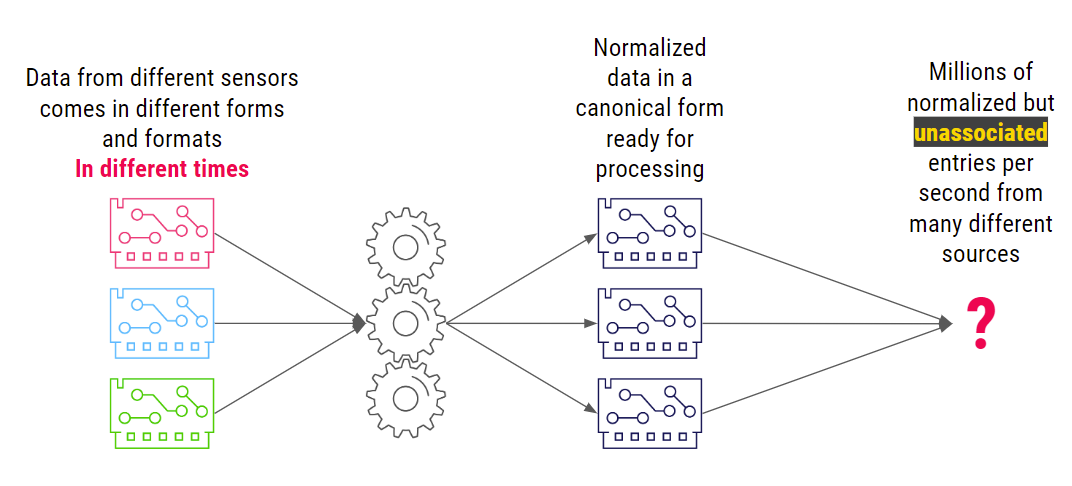
Palo Alto Networks needed a way to group unassociated events into meaningful stories
about network activity
Evolving from Events to Stories
Why is it so hard to associate discrete entries that describe the same network session?
- Clock skew across different sensors: Sensors might be located across different datacenters, computers, and networks, so their clocks might not be synchronized to the millisecond.
- Thousands of deployments to manage: Given the nature of their business, Palo Alto Networks provides each customer a unique deployment. This means that their solution must be optimized for everything from small deployments that process bytes per second to larger ones that process gigabytes per second.
- Sensor’s viewpoint on the session: Different sensors have different perspectives on the same session. One sensor’s message might report the transaction from point A to point B, and another might report the same transaction in the reverse direction.
- Zero tolerance for data loss: For a cybersecurity solution, data loss could mean undetected threats. That’s simply not an option for Palo Alto Networks.
- Continuous out-of-order stream: Sensors send data at different times, and the event time (when the event occurred) is not necessarily the same as the ingestion time (when the event was sent to the system) or the processing time (when they were able to start working on this event).
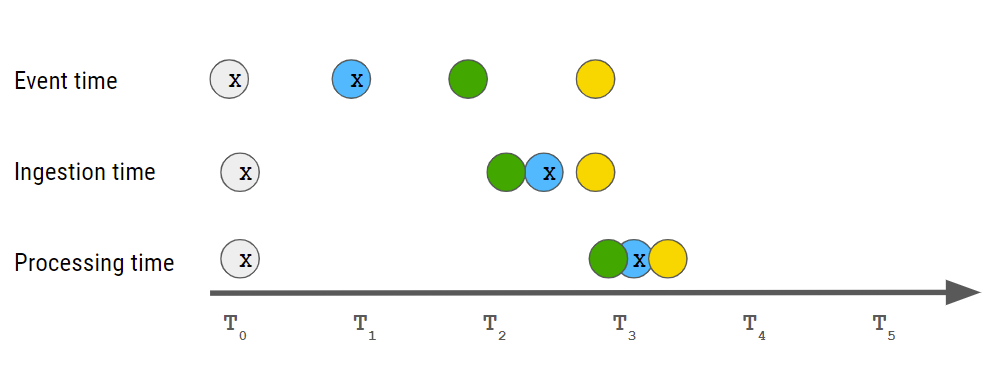
The gray events are related to one story, and the blue events are related to another story. Note that while the gray ones are received in order, the blue ones are not.
From an application perspective, what’s required to convert the millions of discrete events into clear stories that help Palo Alto Networks protect their clients? From a technical perspective, the system needs to:
- Receive a stream of events
- Wait some amount of time to allow related events to arrive
- Decide which events are related to each other
- Publish the results
Additionally, there are two key business requirements to address. Belenky explained, “We need to provide each client a single-tenant deployment to provide complete isolation. And we need to support deployments with everything from several KB per hour up to several GBs per second at a reasonable cost.”
Belenky and team implemented and evaluated four different architectural approaches for meeting this challenge:
- Relational Database
- NoSQL + Message Queue
- NoSQL + Cloud-Managed Message Queue
- NoSQL, No Message Queue
Let’s look at each implementation in turn.
Implementation 1: Relational Database
Using a relational database was the most straightforward solution – and also the easiest to implement. Here, normalized data is stored in a relational database, and some periodic tasks run complex queries to determine which events are part of the same story. It then publishes the resulting stories so other parts of the system can respond as needed.
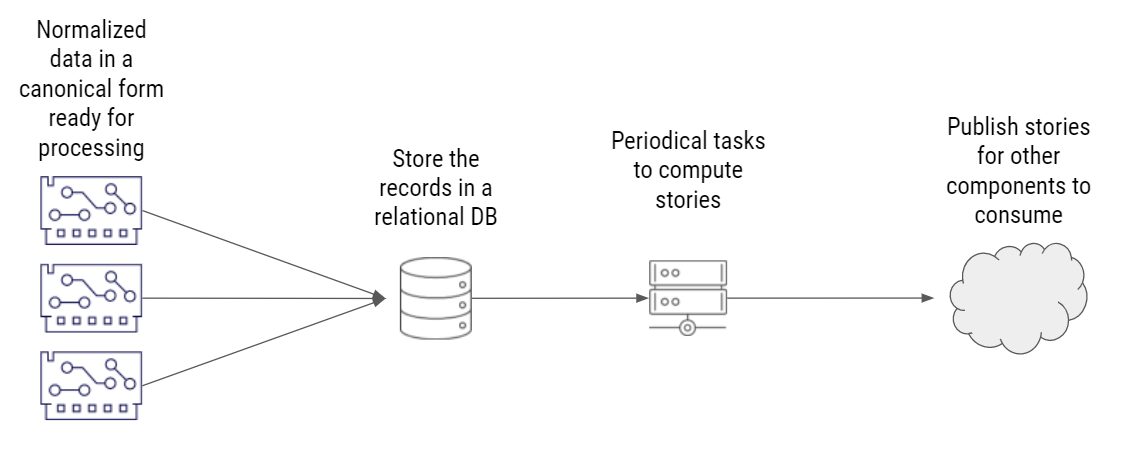
Implementation 1: Relational Database
Pros
- The implementation was relatively simple. Palo Alto Networks deployed a database and wrote some queries, but didn’t need to implement complex logic for correlating stories.
Cons
- Since this approach required them to deploy, maintain and operate a new relational database in their ecosystem, it would cause considerable operational overhead. Over time, this would add up.
- Performance was limited since relational database queries are slower than queries on a low-latency NoSQL database like ScyllaDB.
- They would incur higher operational cost since complex queries require more CPU and are thus more expensive.
Implementation 2: NoSQL + Message Queue
Next, they implemented a solution with ScyllaDB as a NoSQL data store and Kafka as a message queue. Like the first solution, normalized data is stored in a database – but in this implementation, it’s a NoSQL database instead of a relational database. In parallel, they publish the keys that will later allow them to fetch those event records from the database. Each row represents one event from different sources.
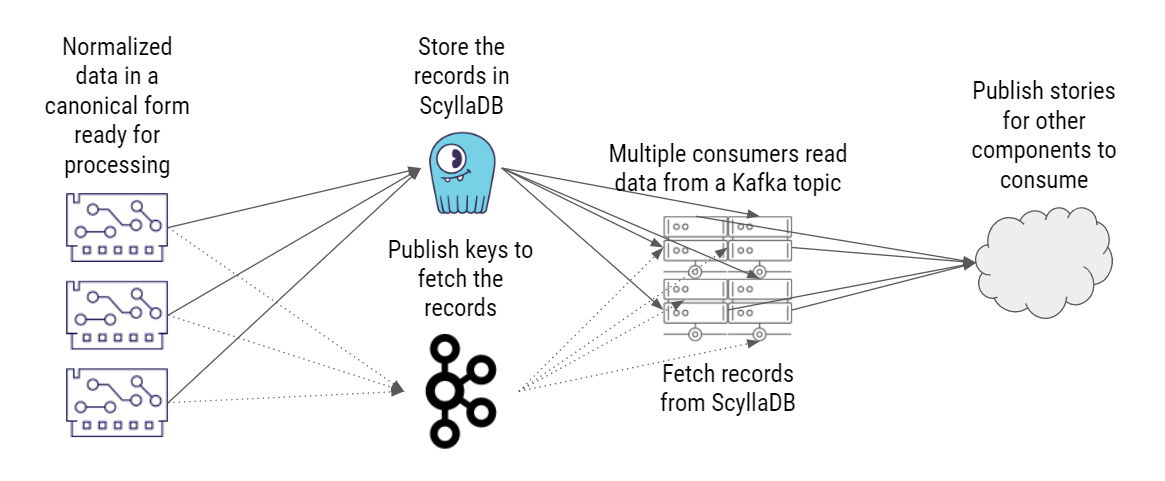
Implementation 2: NoSQL + Message Queue
Multiple consumers read the data from a Kafka topic. Again, this data contains only the key – just enough data to allow those consumers to fetch those records from the database. These consumers then get the actual records from the database, build stories by determining the relations between those events, and publish the stories so that other system components can consume them.
Why not store the records and publish the records directly on Kafka? Belenky explained, “The problem is that those records can be big, several megabytes in size. We can’t afford to run this through Kafka due to the performance impact. To meet our performance expectations, Kafka must work from memory, and we don’t have much memory to give it.”
Pros
- Very high throughput compared to the relational database with batch queries
- One less database to maintain (ScyllaDB was already used across Palo Alto Networks)
Cons
- Required implementation of complex logic to identify correlations and build stories
- Complex architecture and deployment with data being sent to Kafka and the database in parallel
- Providing an isolated deployment for each client meant maintaining thousands of Kafka deployments. Even the smallest customer required two or three Kafka instances
Implementation 3: NoSQL + Cloud-Managed Message Queue
This implementation is largely the same as the previous one. The only exception is that they replaced Kafka with a cloud-managed queue.
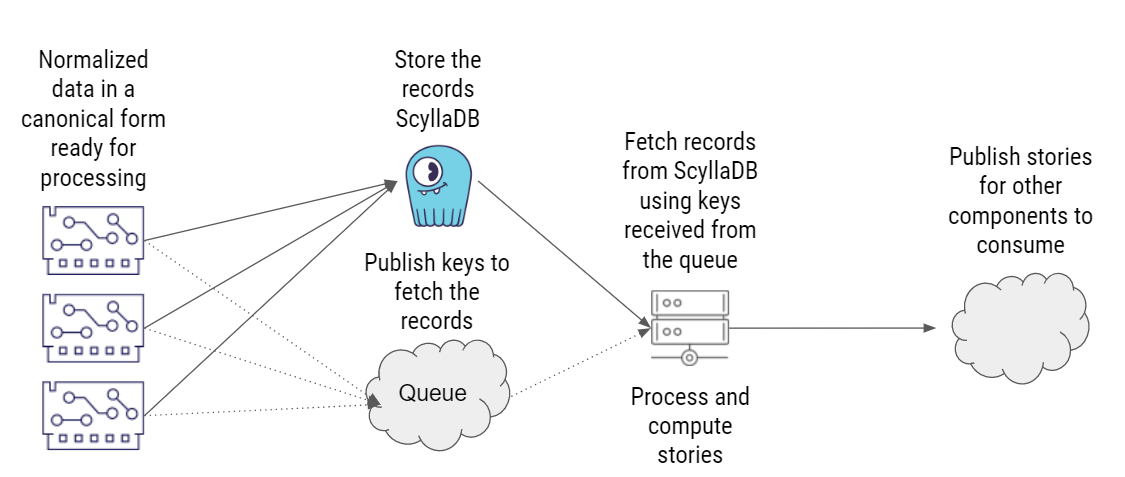
Implementation 3: NoSQL + Cloud-Managed Message Queue
Pros
- Very high throughput compared to the relational database with batch queries
- One less database to maintain (ScyllaDB was already used across Palo Alto Networks)
- No need to maintain Kafka deployments
Cons
- Required implementation of complex logic to identify correlations and build stories
- Much slower performance when compared to Kafka
They quickly dismissed this approach because it was essentially the worst of both worlds: slow performance as well as high complexity.
Implementation 4: NoSQL (ScyllaDB), No Message Queue
Ultimately, the solution that worked best for them was ScyllaDB NoSQL without a message queue.
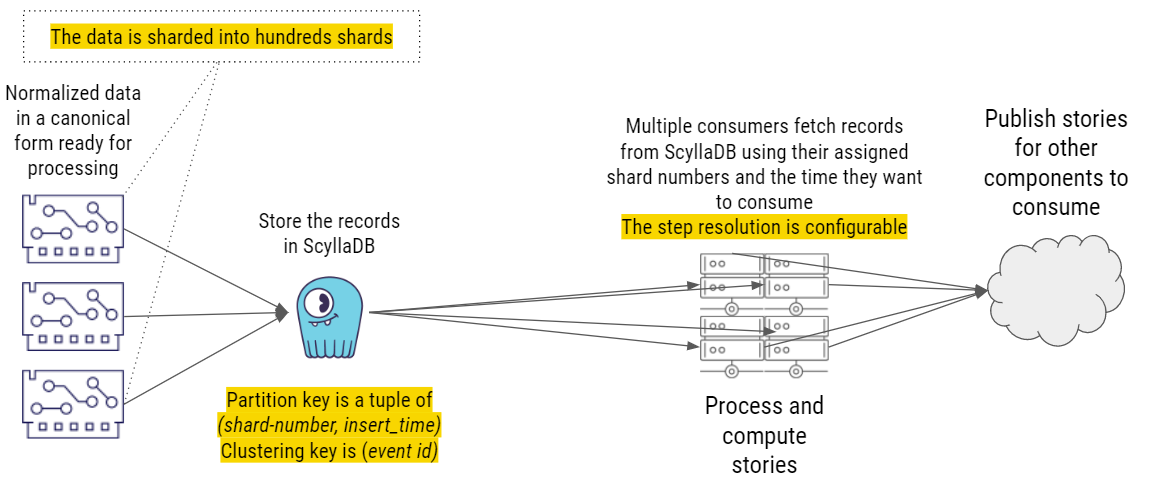
Implementation 4: NoSQL, No Message Queue
Like all the previous solutions, it starts with normalized data in canonical form ready for processing, then that data is split into hundreds of shards. However, now the records are sent to just one place: ScyllaDB. The partition key is shard-number, allowing different workers to work on different shards in parallel. insert_time is a timestamp with a certain resolution – say up to 1 second. The clustering key is event_id, and that’s used later to fetch dedicated events.
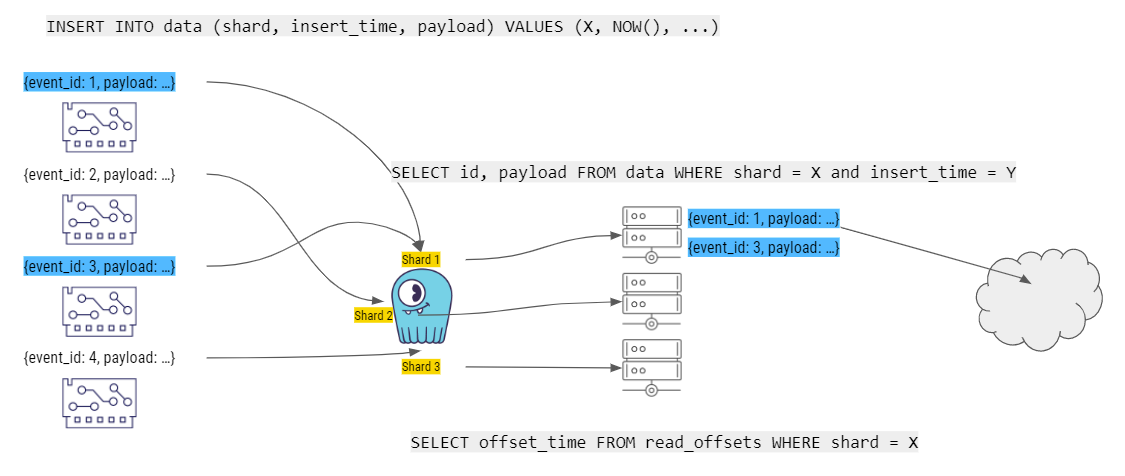
Belenky expanded, “We have our multiple consumers fetching records from ScyllaDB. They run a query that tells ScyllaDB, ‘Give me all the data that you have for this partition, for this shard, and with the given timestamp.’ ScyllaDB returns all the records to them, they compute the stories, and then they publish the stories for other parts or other components in the system to consume.”
Pros
- Since ScyllaDB was already deployed across their organization, they didn’t need to add any new technologies to their ecosystem
- High throughput when compared to the relational database approach
- Comparable performance to the Kafka solution
- No need to add or maintain Kafka deployments
Cons
- Their code became more complex
- Producers and consumers must have synchronized clocks (up to a certain resolution)
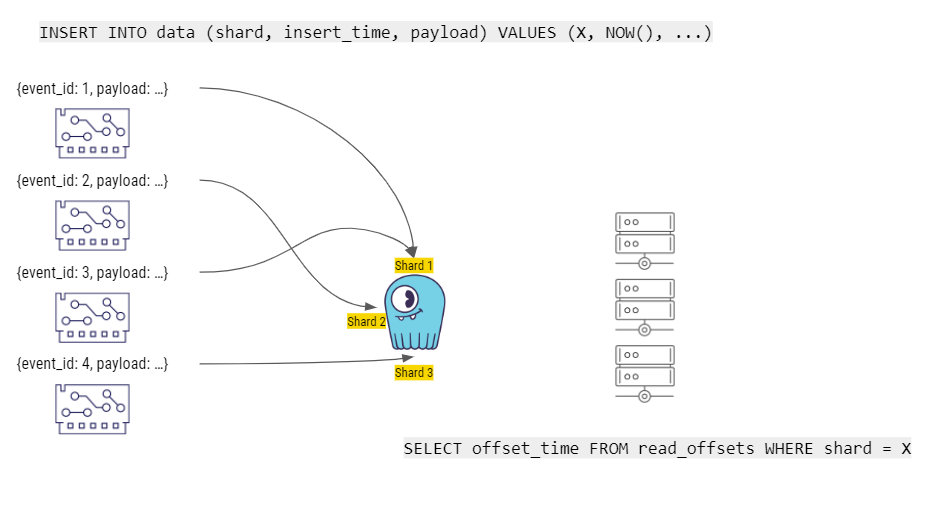
Finally, let’s take an even deeper dive into how this solution works. The right side of this diagram shows Palo Alto Networks’ internal “worker” components that build the stories. When the worker components start, they query ScyllaDB. There’s a special table, called read_offsets, which is where each worker component stores its last offset (the last time stamp that it reached with its reading). ScyllaDB then returns the last state that it had for each shard. For example, for shard 1, the read_offset is 1000. Shards 2 and 3 have different offsets.
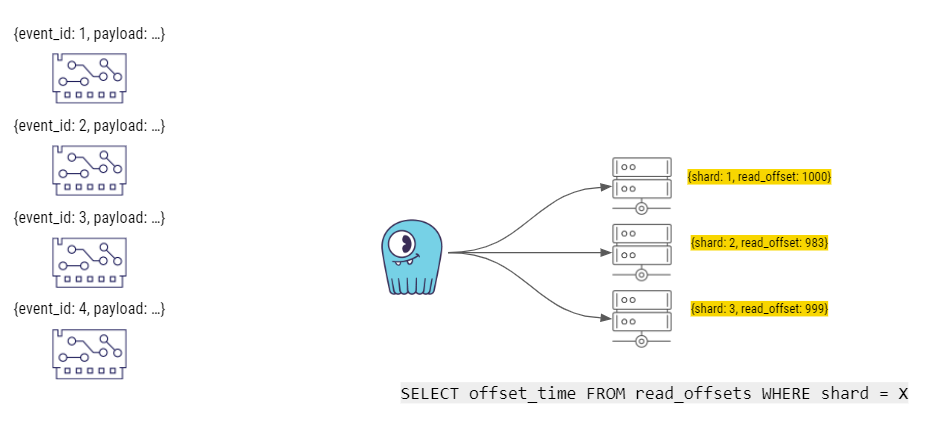
Then the event producers run a query that inserts data, including the event_id as well as the actual payload, into the appropriate shard on ScyllaDB.
Next, the workers (which are continuously running in an endless loop) take the data from ScyllaDB, compute stories, and make the stories available to consumers.
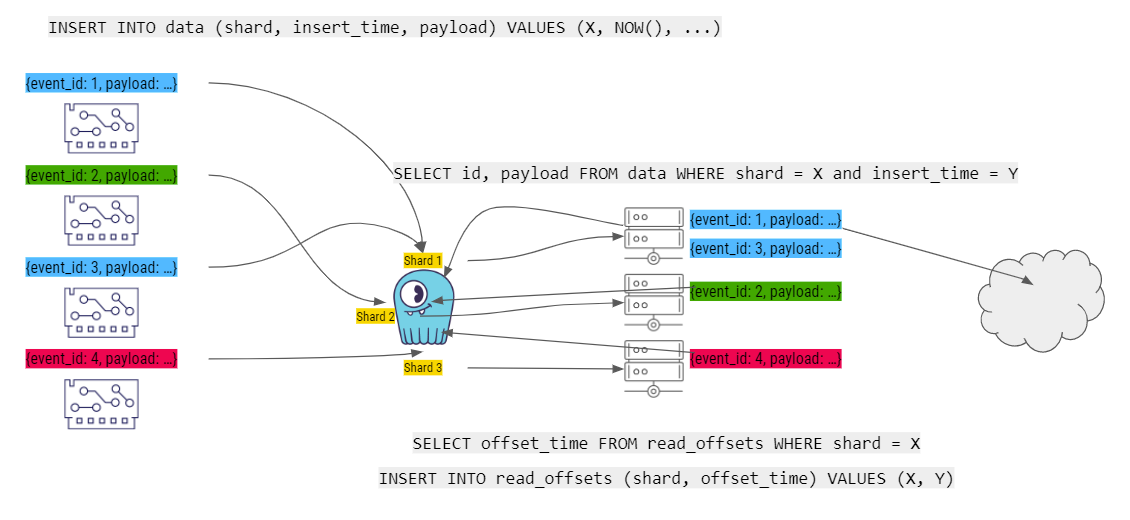
When each of the workers is done computing a story, it commits the last read_offset to ScyllaDB.
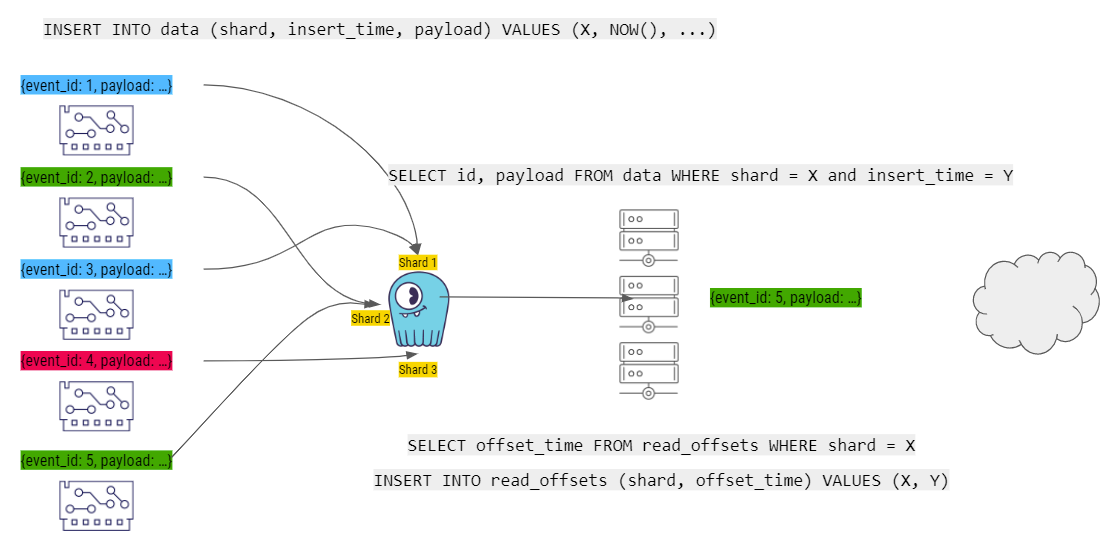
When the next event arrives, it’s added to a ScyllaDB shard and processed by the workers…then the cycle continues.
Final Results
What were their final results? Belenky summed up, “We’ve been able to reduce the operational cost by a lot, actually. We reduced the operational complexity because we didn’t add another system – we actually removed a system [Kafka] from our deployment. And we’ve been able to increase our performance, which translates to reduced operational costs.”
Want to Learn More?
ScyllaDB is the monstrously fast and scalable database for industry gamechangers. We’d love to chat with you if you want to learn more about how you can use ScyllaDB in your own organization. Contact us directly, or join the conversation with our Slack community.








