Every infrastructure-oriented workload (like a database), will use a mixture of CPU, memory, and storage to perform its tasks. However, different workloads will need different ratios between those components for optimal performance. For instance: a real time engine that needs to serve millions of query per second over a not-so-high volume of data will excel with more CPUs and won’t need as much storage space. A time series application, in contrast, may need to store a lot of data but query less frequently and will need more storage space and less CPU power.
Traditionally, AWS has elegantly approached this problem by providing different instance families. But up until recently, only one of these families, the I3 family, had fast enough storage for modern databases. With NVMes capable of reading 15GiB/s, the I3 family is a great choice for modern databases but still has a fairly low disk-to-CPU ratio. What that meant is that use cases where the cost determinant was disk storage were stuck with having to run many I3 instances where the CPUs would be underutilized.
This changes with AWS’ new announcement of the I3en family of instances. With up to 60TB of attached local NVMe fast storage, workloads for which storage capacity is the determining factor will become significantly cheaper. Users now have added flexibility on how to run their workloads.
| Storage size per core | price per core | price per TB of data | |
| i3.16xlarge | 480GB | $ 880.50 / year | $ 1,857.96 / year |
| i3.metal | 426GB | $ 773.78 / year | $ 1,857.06 / year |
| i3en.24xlarge | 1.2TB | $ 1,258.43 / year | $ 1,006.75 / year |
Table 1: The economics for the largest instances in the I3 and I3en family of instances. Prices are for 1-year reservations according to AWS for the us-east region. Workloads for which the limiting factor is the CPU power will be cheaper on I3, whereas workloads for which the limiting factor is storage capacity will be cheaper on I3en.
When looking at those specs, however, the question remains: How do those instances perform in practice, and can current software even take advantage of all of it? In this article, we will explore the largest of the I3en instances, i3en.24xlarge, performing basic tests to see how it performs in practice. We will then demonstrate using these instances to run ScyllaDB and gauge whether or not it is capable of using the resources provided by I3en instances efficiently.

How big is the i3en.24xlarge node? Sorta like this. (Note: The Rock, standing to the left, is 6’5″ tall; 200 cm. He is pictured here next to Sun Ming Ming, who stands 7’9″; 236cm.)
The CPUs
The I3en family is a class of instances clearly targeted at storage-intensive workloads, but CPUs are still needed to process that data. The largest of the I3en, i3en.24xlarge, ships with 48 cores of the Xeon Platinum 8175M, clocking at 2.50GHz. They are slightly faster than their I3 counterparts, and the more modern core and cache help as well. The largest of the I3, i3.metal, uses 36 Xeon E5-2686 v4 cores, with 2.30GHz clock speeds. Don’t let the increase in the amount of cores fool you: The i3en.24xlarge has 50% more cores per instance, but 400% more storage per instance: it is still an instance focusing on high storage capacity workloads.
The fact that the clock speeds are also faster is welcome news, and means that the cpu/storage gap is smaller than it seems from the surface. Another welcome addition to the I3en family is that it uses the Nitro KVM-based hypervisor, which is expected to provide much better performance than the legacy Xen hypervisor, especially for heavy I/O-driven workloads. As a matter of fact, with a modern KVM-based hypervisor the I3en family doesn’t seem to have a metal offering like the standard i3.
To demonstrate how it translates into performance in practice, we have used the stress-ng benchmark. What we can see in the results of the benchmark (Table 2), is that although the i3en.24xlarge has proportionally fewer CPUs per TB of data, the gap is to some extent bridged by the fact that each CPU is faster. The i3en.24xlarge CPUs performs better in all benchmarks we tested with the exception of two: The matrix benchmark, where both CPUs are almost equal, and the memcpy benchmark where the i3.16xlarge has an advantage.
| Benchmark | i3.16xlarge (ops) | i3en.24xlarge (ops) | difference |
| cache | 1.59 | 2.25 | 41.51% |
| cpu | 221.21 | 302.40 | 36.70% |
| dentry | 23,578.10 | 29,544.91 | 25.31% |
| icache | 399.97 | 449.88 | 12.48% |
| matrix | 4,219.04 | 4,133.63 | -2.02% |
| memcpy | 567.87 | 381.34 | -32.85% |
| qsort | 8.82 | 10.63 | 20.52% |
| timer | 119,784.59 | 136,156.85 | 13.67% |
| tsc | 847,677.39 | 983,544.69 | 16.03% |
Table 2: Result of running the following command in both the i3.16xlarge and i3.24xlarge: stress-ng --metrics-brief --cache 1 --icache 1 --matrix 1 --cpu 1 --tsc 1 --memcpy 1 --qsort 1 --dentry 1 --timer 1 -t 1m. Although the i3.24xlarge has proportionally fewer CPUs per TB of data, each CPU is individually faster, which helps bridge the gap.
These results are not surprising. The matrix benchmark is expected to stress the floating point SSE instruction set more than other parts of the CPU, and we don’t expect significant differences in this area between those two CPUs. The small difference is within a reasonable error margin and matches our expectations. The difference in the memcpy benchmark is much wider, a bit above 30%. But looking at the specs for the I3en and I3 CPUs respectively, we can see that the I3 CPUs have 45MB of L3 cache against only 33MB for the I3en. This is a 36% decrease in the L3 size, which is a reasonable explanation for the lower performance of the memcpy benchmark. Note that, in practice, the decrease in L3 size is counterbalanced by an increase in L2 size, so this will hurt some workloads and benefit others.
The network: Look Ma, 100gbps!
The network is yet another great surprise that comes with the I3en family of instances. For the largest one in the family, the i3en.24xlarge, AWS advertises a truly impressive 100Gbps networking link. But is it for real? For this test, we have spun two i3en.24xlarge instances and used the iperf utility to study the link between them. Running iperf for 10 minutes, we can see that the link speed is very close to the advertised 100Gbps and extremely consistent:
$ iperf -c ip-10-1-87-25 -P 96 -t 600
[SUM] 0.0-600.0 sec 6.49 TBytes 95.1 Gbits/sec

Figure 1: Network throughput on the i3en.24xlarge with a 100gbps network interface card (NIC) is over 95 gbps, close to its advertised maximum.
Throughput, however, is easy since modern hardware tends to be pretty good in batching things. But for many latency-sensitive use cases it is common for the workload to avoid batching, which generates a lot of small packets at a high frequency. Dealing with interrupts at a high rate is more challenging than cruising large buffer, and those systems will be usually bottlenecked on the rate the system can process the incoming packets.
To test our limits with small packets, we have disabled offloading features in the NIC (GSO, GRO, etc), and used small UDP packets to make sure we had more control on the packet sizes and (lack of) coalescing. The i3en.24xlarge instance was able to send north of 5 million packets per second, which is more than enough for the most demanding latency based workloads.
iperf -c ip-10-1-87-25 -P 96 -t 60 -l 16 -u -b 100G
[SUM] 0.0-60.3 sec 4.26 GBytes 607 Mbits/sec 15.625 ms 81116999/366966173 (22%)

Figure 2: Network performance with small packets, offloading disabled and using UDP packets shows performance still above 5 million packets per second, and over 600 mbps throughput.
The storage
It’s great to have a lot of storage but workloads will suffer if the storage is not fast enough. AWS advertises 2M IOPS and 16GB/s for reads out of these devices. We ran the fio benchmark to verify those numbers, and also determine the real figures for writes. The results, in comparison with the i3.16xlarge instance, are presented in Table 3 below.
| i3en.24xlarge | i3.16xlarge | i3.metal | |
| 1MB sequential write | 8.3 GB/s | 6.5 GB/s | 6.5 GB/s |
| 1MB sequential read | 16.6 GB/s | 15.6 GB/s | 15.4 GB/s |
| 4kB random write | 1.6M IOPS | 830k IOPS | 1.4M IOPS |
| 4kB random read | 2.0M IOPS | 1.2M IOPS | 3.1M IOPS |
Table 3: Results for the fio benchmark. The instance behave as advertised, and at 8GB/s write bandwidth it will also serve write workloads well. Benchmark was run as fio --name=n --ioengine=libaio --direct=1 --bs= --rw= --numjobs=32 --iodepth=128 --filename=/dev/md0 --group_reporting --runtime=30
As we can see, the i3en.24xlarge is superior to both the i3.metal and the i3.16xlarge in all aspects of storage speed, except for random read IOPS. The write bandwidth is 27% higher than both I3 for the i3en.24xlarge, which guarantees that filling the storage device it offers shouldn’t be a problem. For random reads, we can clearly see that in comparison with the virtualized instances the Nitro KVM-Based hypervisor provides huge speedups, with 66% faster random reads. This will be especially relevant for users running the smaller versions of I3en, but the storage device itself is still slower for random reads than the i3.metal.
A real application
We saw that the specs of the I3en instances are excellent, and the results in practice back up the advertised values. So how does a real data-intensive application works in practice? To figure this out, we have run tests in our ScyllaDB NoSQL database. The tests were initially run with a key-value schema with 1kB values spread in five tables. To each of the five tables we have inserted 90 billion keys, totalling around 45TB of data.
We start by inserting close to 2 million requests a second, but as more data is generated, the ScyllaDB automatic dynamic controllers adjust the compaction rate upwards, and over the next hours the ingestion rate is reduced to around 1.5 million requests per second (Figure 3). After a while, the rate drops more, approaching 1 million requests per second.
We can easily understand the reason for that by looking at the storage bandwidth during the ingestion. SSD devices need to allocate blocks internally, which means they get slower as they get fuller and there are fewer blocks available. The filesystem can enhance that process by telling the device which blocks it no longer uses by using the TRIM command, but even then some slowdown is expected. In Figure 4, we plot the disk bandwidth over time during the ingestion period and we see the effective bandwidth going down from 8GB/s to 5GB/s. This time thanks to the write rate ingestion controller, ScyllaDB once more automatically adapts to this situation and reduces the write rate on the client’s behalf.
This is still an impressive write bandwidth, showcasing the ability of i3en.24xlarge to deliver good performance while making the most out of the hardware it provides.
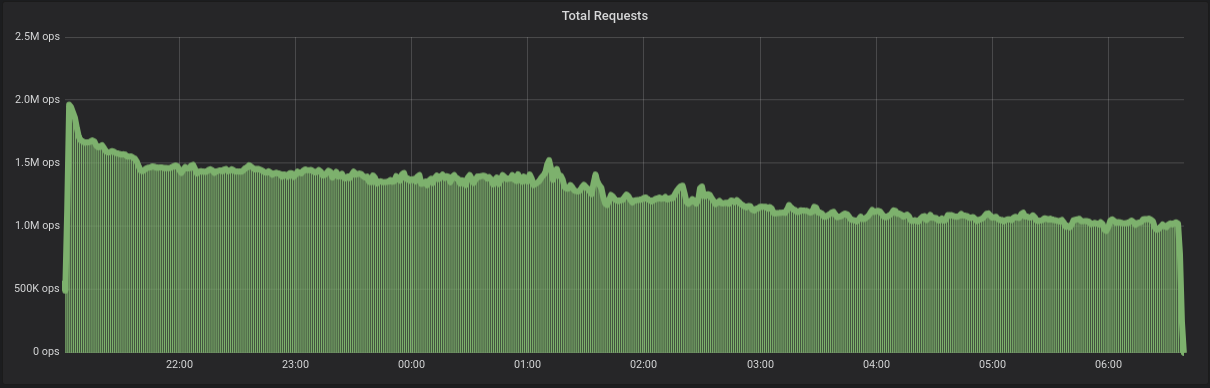
Figure 3: Ingestion rate for ScyllaDB running on the i3en.24xlarge. ScyllaDB starts ingesting around 2 million data points per second, and as the data size grows it automatically adjusts the rate between ingestion and compactions. The ingestion rate gets reduced to 1.5 million writes per second as the need for compaction increases, and then further down to 1 million writes per second as the storage array gets slower.
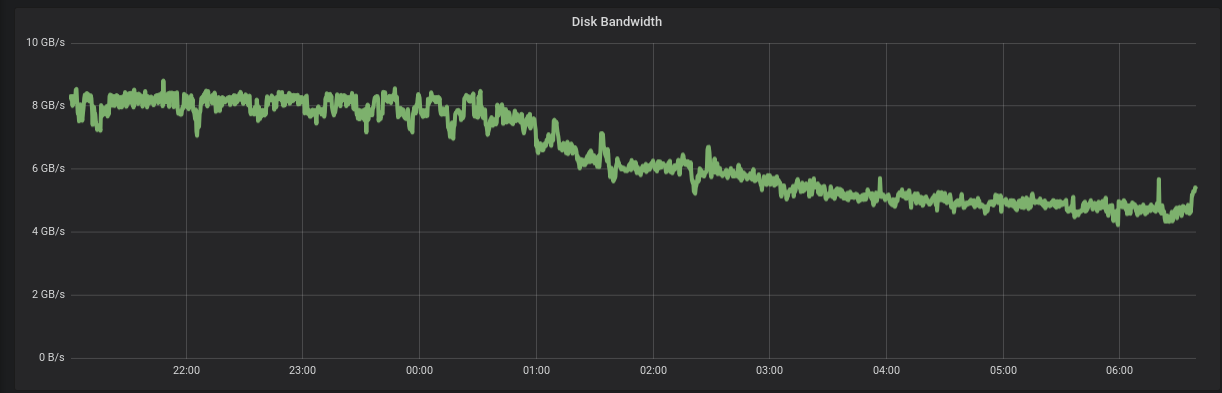
Figure 4: As with any SSD, the bandwidth is reduced as the device gets fuller. The i3en.24xlarge is no exception, but it is still able to provide 5GB/s of bandwidth even at a very high level of utilization, over 75%.
The next challenge is to read the data. For around one hour, we issue reads to random keys following a uniform distribution and select the parameters of the distribution so that the cache hit ratio is below 20% (mostly misses). This will allow us to show the performance of reads that are mostly coming from the storage in a latency-oriented situation.
As shown in Figure 6, the 99th percentile is still comfortably around 2 milliseconds during the entire duration of the run, getting even more stable as the cache warms up. This shows that the storage stack, including the Nitro Hypervisor can provide consistent, reliable and bounded latencies for demanding applications.
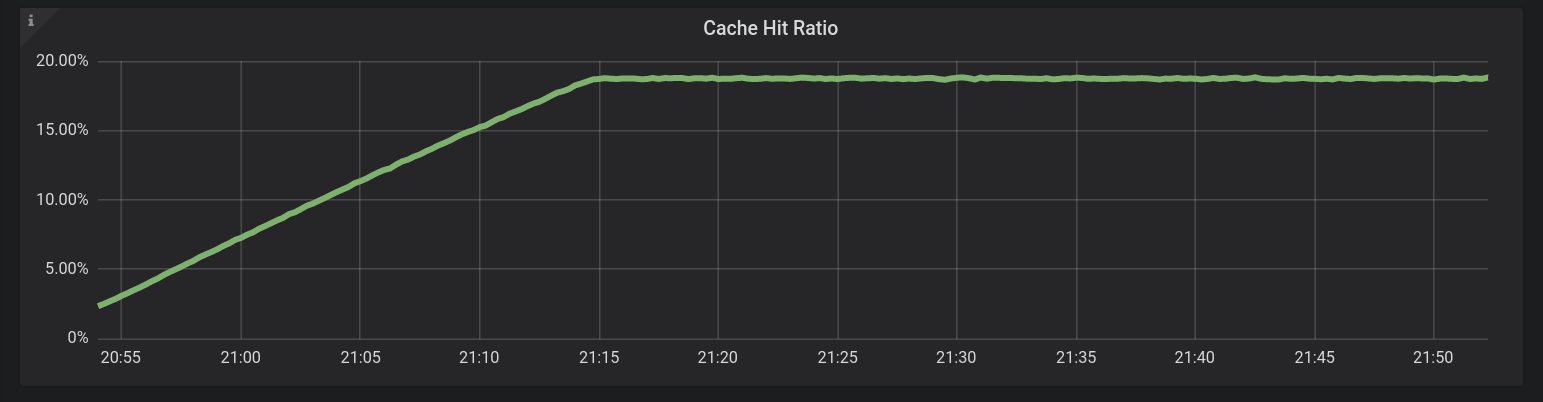
Figure 5: the cache warmup period for the database reads. We start from a cache-cold situation and issue reads until the cache reaches a steady state of ~20% hit rate. Most requests are still coming from the storage.
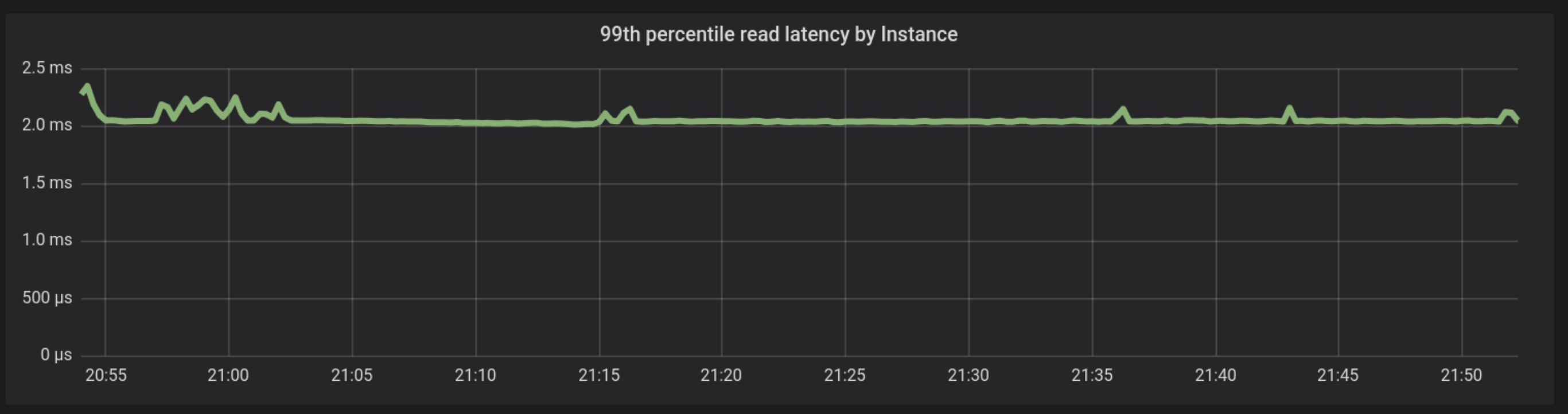
Figure 6: Random uniform reads. There is little difference in the reads between a situation where almost all requests come from the storage, and at the steady state where 80% of the requests come from the storage. Latencies are still consistent, reliable and bounded.
We have also tested other administrative operations in ScyllaDB like adding a node, cleaning up the database and compacting. You can read more about them here.
Conclusion
AWS has recently unveiled a new family of storage optimized instances, the I3en family. These instances are a game changer for AWS customers, as they offer the choice between a low price per core or a low price per terabyte of data.
We have demonstrated that although the I3en family packs more data per CPU, the CPUs themselves are faster, and together with a storage stack that can write at close to 8GB/s and read at around 16GB/s, the gap between processing and storing is greatly reduced. The new I3en family provides a much less expensive price per TB of data, while the I3 family is still cheaper for users that are not constrained by the amount of storage. This provides AWS users with extra flexibility and favorable economics when choosing storage optimized instances based on either disk read speed (i3.metal) or storage capacity (I3en)..
To put it all together, we have demonstrated the results of running an application that can scale up and use these resources efficiently, the ScyllaDB NoSQL database, operating on a 45TB dataset in a single node. ScyllaDB, the monstrously fast and scalable NoSQL database, was capable of ingesting between 1 and 2 million data points a second, with low and bounded read latencies at around 2 milliseconds for the 99th percentile. This shows that the I3en resources are put to good use.