ScyllaDB powers real-time AI with low latency, high throughput, and billion-scale data.
Learn More
This document provides additional information and context for the results displayed in this blog: AWS new I3en Meganode – Bigger Nodes for Bigger Data
We have recently tested ScyllaDB on the new AWS i3en.24xlarge meganodes. You can read more about the entire setup here. Aside from ingestion and basic reads, we have also conducted tests on other administrative operations like compaction, adding nodes and cleanups. In this follow up article we will detail the results of these operations.
For the ingestion phase, five clients write to five different tables without any rate limitation. Each one uses 5,000 threads, with the ScyllaDB shard aware driver. Client-side coalescing at 10ms is used to batch inserts, since this is a throughput oriented ingestion. Cassandra stress command line for the clients:
#!/usr/bin/bash
ks="ks$(< idx)"
N=9500000000
JVM_OPTS='
Dcom.datastax.driver.FLUSHER_SCHEDULE_PERIOD_NS=10000000' cassandra-stress write cl=quorum \
n=$N no-warmup \
-col n=FIXED\(1\) size=FIXED\(1024\) \
-rate "threads=5000" \
-mode cql3 native maxPending=32000 \
-log file=run.log \
-schema keyspace=$ks \
-node 10.1.33.200 \
-pop seq=1..$NThe results of the ingestion were already shown in the main article, but are repeated here for simplicity. We can see that to ingest the entire dataset of 45TB with 1kB payloads, ScyllaDB took around 10h, with a total average of 1.28 Million inserts per second.
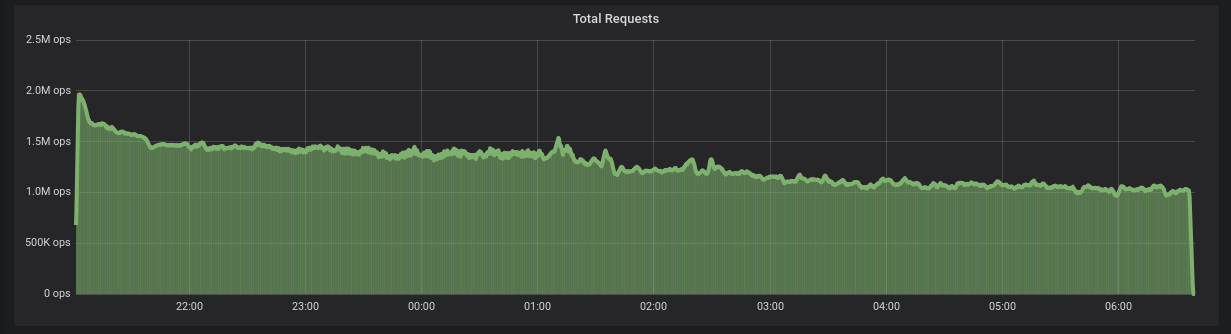
Figure 1: 1.2 Million requests per second on average for ingestion, ScyllaDB completes the ingestion in around 10 hours.
Once the insertion ends, we wait until all automatic compactions end. From the idle state, we invoke a major compaction. Note that in ScyllaDB, calling a major compaction on a many-table system will effectively serialize the tables, in no particular order. The Figure below shows the compaction bandwidth during the process, and right after that, disk utilization. Total time to compact 45TB of data: around 5h.
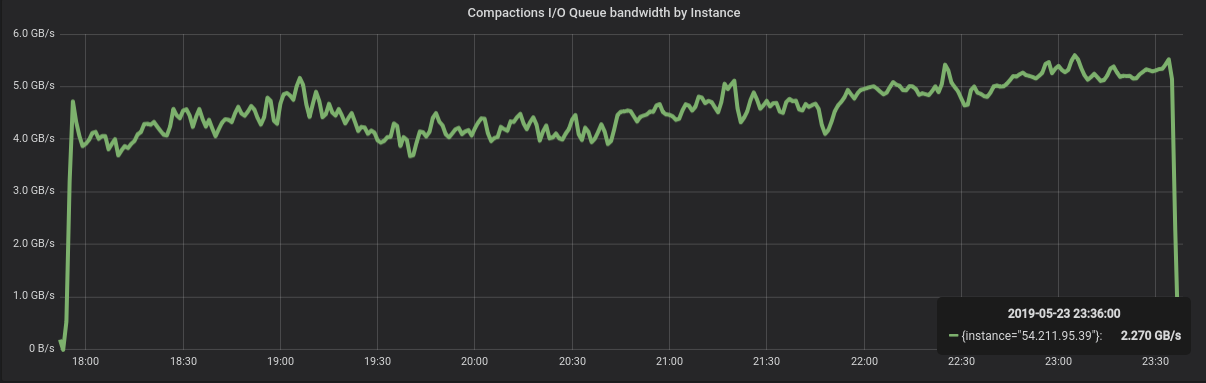
Figure 2: Compaction of the entire 45TB dataset takes 5h.
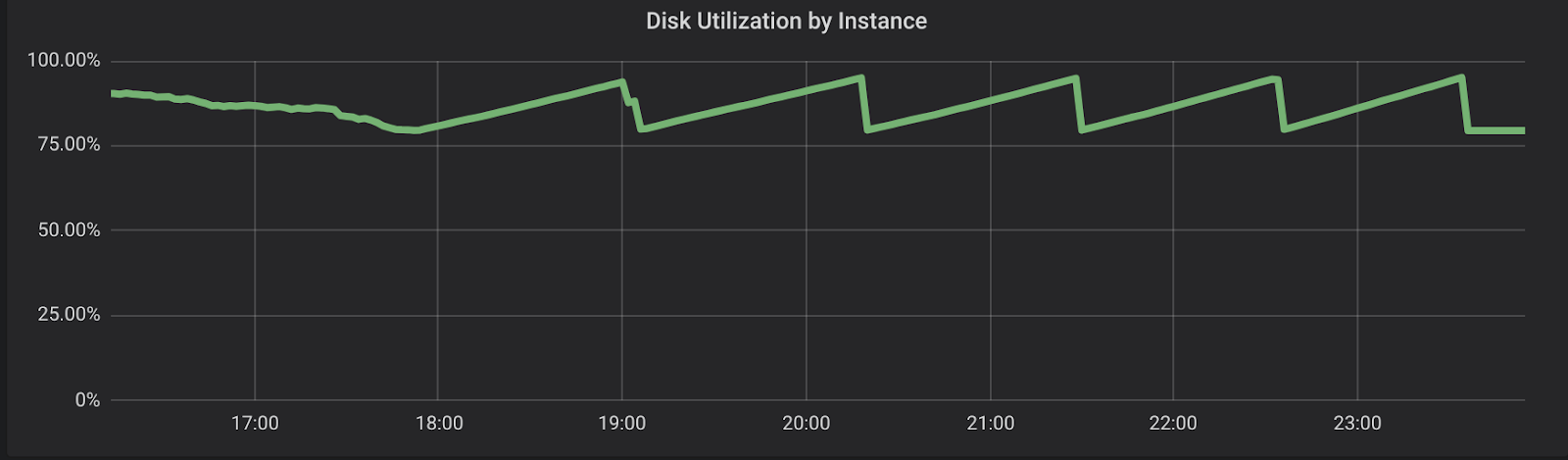
Figure 3: During compactions, disk utilization varies between 80% – the baseline, and 95%. Since we’re not expiring any data and there are no duplicates, the total amount of data doesn’t change.
The next step is to add a new node to the cluster. Once done, this process will split the existing data among both nodes in the cluster, with ~22TB each. This is way more efficient than ingestion, since the database can send large chunks of data at once, unlike the client ingestion front door that sends 1kB per request. The new node is added to the cluster in ~4h.
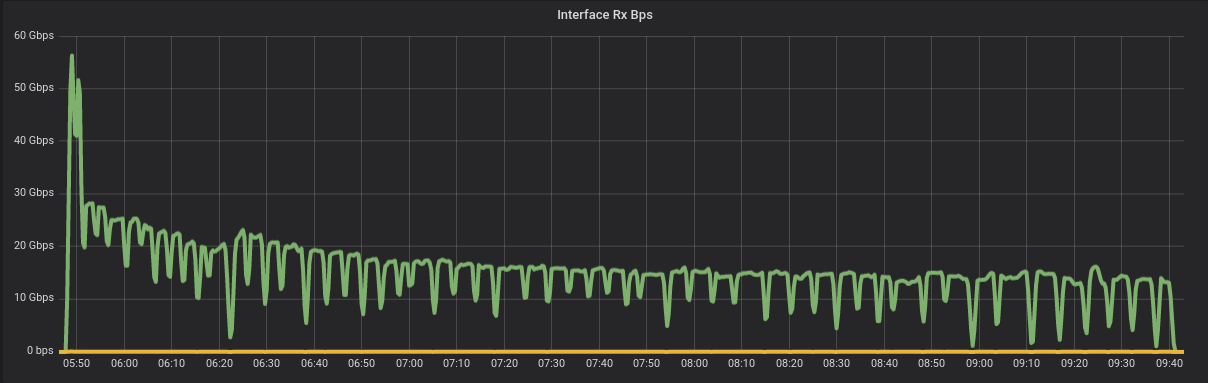
Figure 4: Adding a new node to the Cluster is more efficient than ingesting, since ScyllaDB can transfer large amounts of data at once – not 1kB at a time. Adding a node in this cluster takes around 4h.
Once the bootstrap finishes, the new node will have 22.5TB of data. The old node, however, will be responsible for 22.5TB of data but will still hold the entire 45TB dataset. To get rid of unowned data and reduce its storage usage, the operator has to call “nodetool cleanup”.
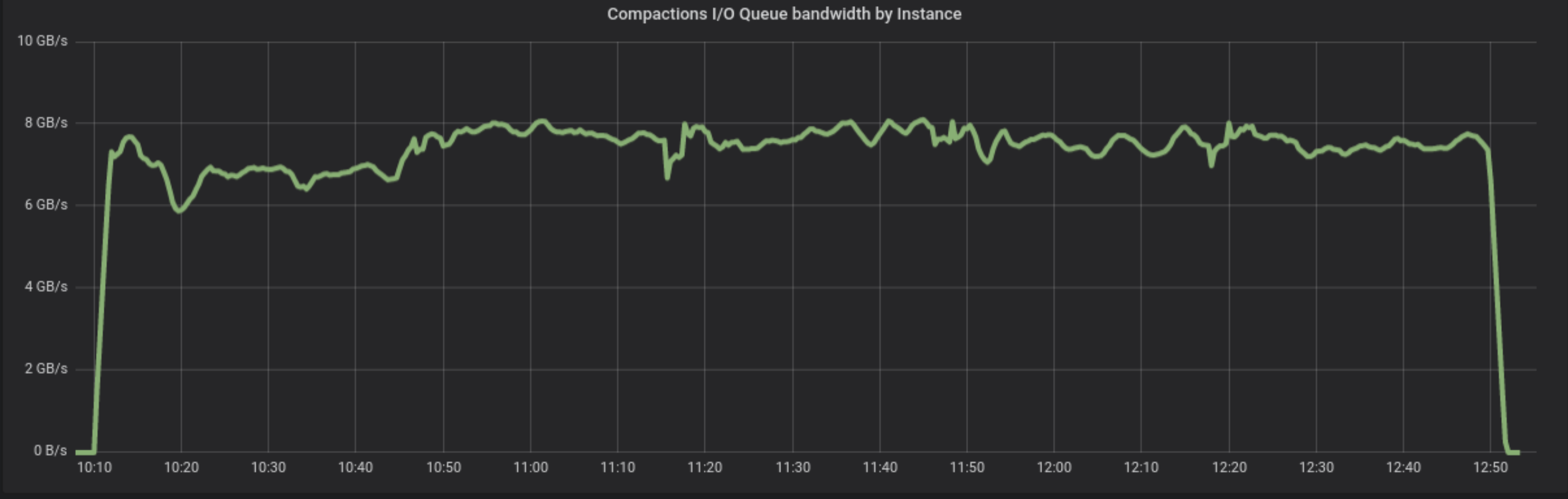
Figure 5: nodetool cleanup gets rid of half of the data in the node. It takes around 2h to complete, reducing the size of the node from 45TB to 22.5TB.



