
A New Way to Achieve Isolation
Modern software is often comprised of many independent pieces working in tandem for a common goal. That’s obviously true for microservices, which are built from the ground up with the communication paradigm in mind, but it can also be just as true for things that look more like a monolith, like databases.
For infrastructure software like databases, there is usually a piece of software that is more important than others— the server itself, but that is often accompanied by other small, focused applications like agents, backup tools, etc.
But once we have many entities running in the same system, how to make sure they are properly isolated? The common answer these days seems to be just use docker. But that comes with two main drawbacks:
- Docker and other container technologies ship an entire version of the Operating System image, which is often an overkill
- Docker and other container technologies force communication between isolated entities through a network abstraction— albeit virtual, which may not always be suitable and can create a security risk

Figure 1: How docker was born
In this article we’ll explore another way, recently adopted by ScyllaDB, to achieve isolation between internal tasks of a complex database server, namely – systemd slices.
What are systemd slices?
If we want to achieve a result like docker, without paying the full complexity price of docker, it pays to ask ourselves “what is docker made of?”
Docker — and other Linux container technologies, rely on two pieces of infrastructure exposed by the kernel: namespaces and cgroups. Linux namespaces are not relevant to our investigation, but for completeness, they allow a process to establish a virtual view of particular resources in the system. For instance: by using the network namespace, a process would not be exposed to the actual network devices, but would view virtualized devices instead, that only exist in that private namespace. Other examples of namespaces are the process namespace, user namespace, etc.
Cgroups are the Linux way of organizing groups of processes: roughly speaking a cgroup is to a process what a process is to a thread: one can have many threads belonging to the same process, and in the same way one can join many processes inside the same cgroup.
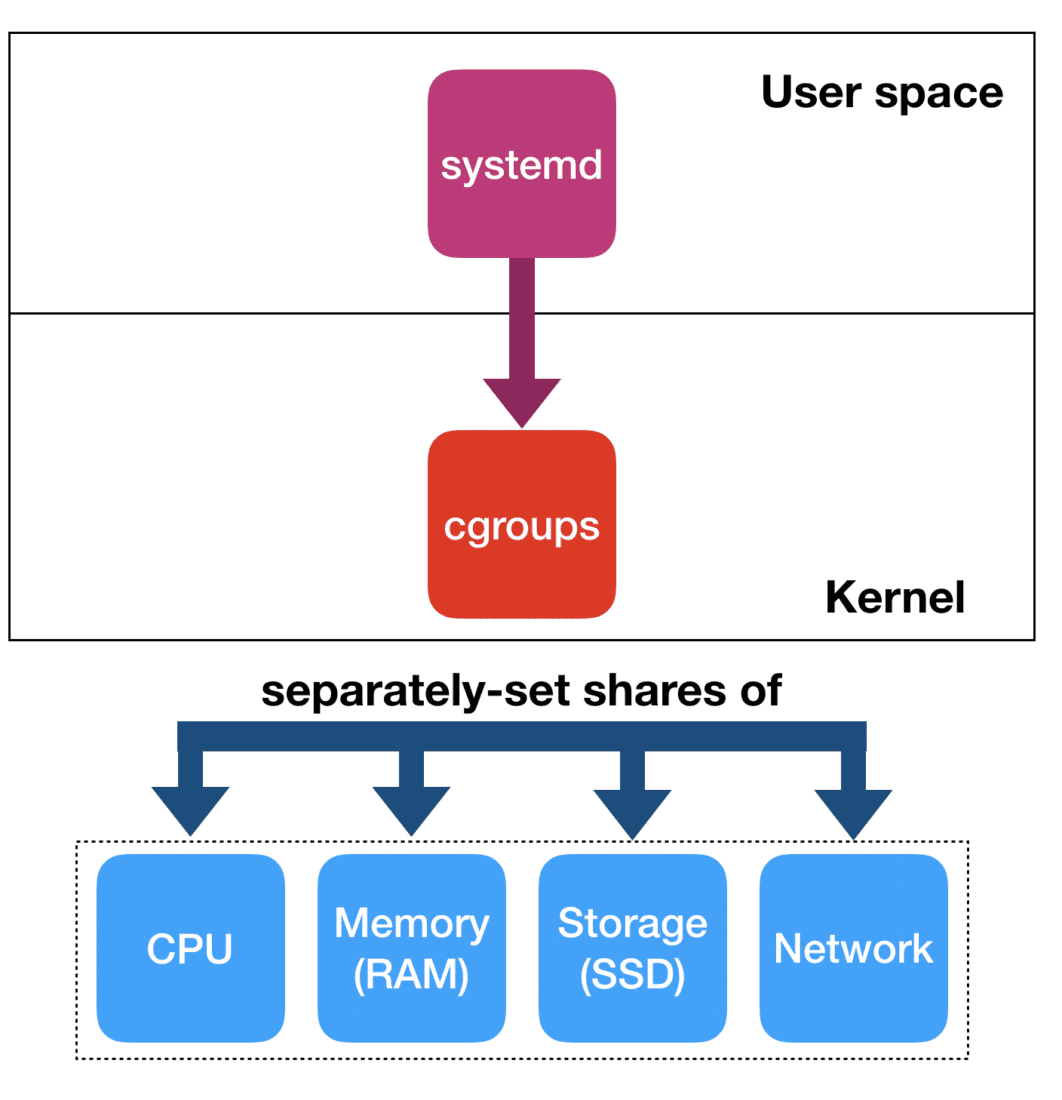
By now, cgroups are nothing new: systemd uses cgroups heavily, and makes sure that every service that comprises the system is organized in its own cgroup. That allows systemd to better organize those services and more safely deal with operations like starting and stopping a service.
But how does that relate to resources? Cgroups, on their own, don’t provide any isolation. However, to a particular cgroup one can attach one or more controllers. The controllers are hierarchical entities that control which share of a resource the processes in the cgroups attached to those controllers can consume. Examples of controllers are the CPU controller, the memory controller, blkio controller, etc.
Systemd relies on controllers for its basic functions. For instance, when many users log in, systemd will do its best— through controllers — to make sure that no single user can monopolize the resources of the system. Less widely known, however, that the same functionality is exposed to any service that registers itself with systemd through slices. Slices allow one to create a hierarchical structure in which relative shares of resources are defined for the entities that belong to those slices. Nothing more than the raw power of cgroup controllers gets exposed.
Applying that to the ScyllaDB NoSQL database
Why would a database need something like that? Unlike microservices, databases are long-lived pieces of infrastructure that usually deal with a large number of connections and thrive on proximity to the hardware infrastructure. While that is true for most databases, it is especially true for ScyllaDB, that relies on a modern shard-per-core architecture, heavily relying on kernel bypass and other hardware optimization techniques to squeeze every drop of the hardware resources available.
ScyllaDB will carefully pre-allocate memory, bind particular threads to particular CPUs, and usually assume that it owns the entire hardware where it is running for best performance. However, rarely the ScyllaDB server runs alone: in a real life deployment there are other entities that may run alongside it, like:
- scylla-jmx, a compatibility layer that exposes the ScyllaDB RESTful control plane as Java Management Extensions (JMX), for compatibility with Cassandra tools,
- node_exporter, a prometheus-based metrics agent,
- other ad-hoc agents such as backup-tools,
- arbitrary commands and processes started by the administrator.
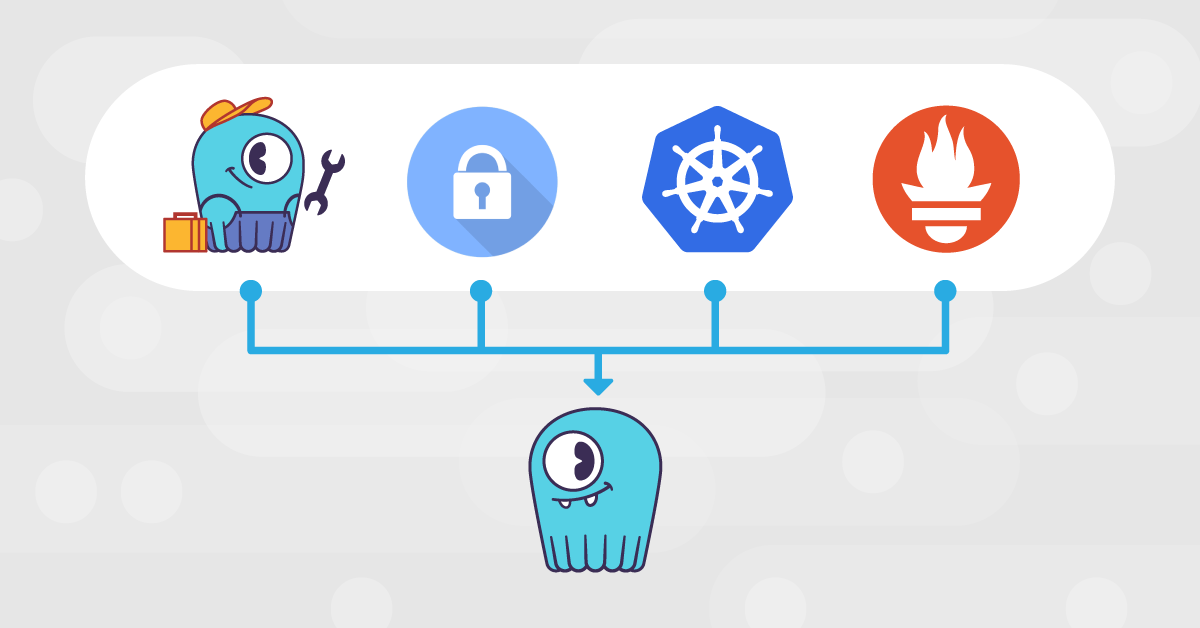
A common display of how such arrangement may play out is depicted in Figure 2, where a ScyllaDB database runs in a node that also runs a backup agent periodically copying files to a remote destination, a security agent imposed by their IT admin, a Kubernetes sidecar and a Prometheus agent collecting metrics about the operating system’s health.
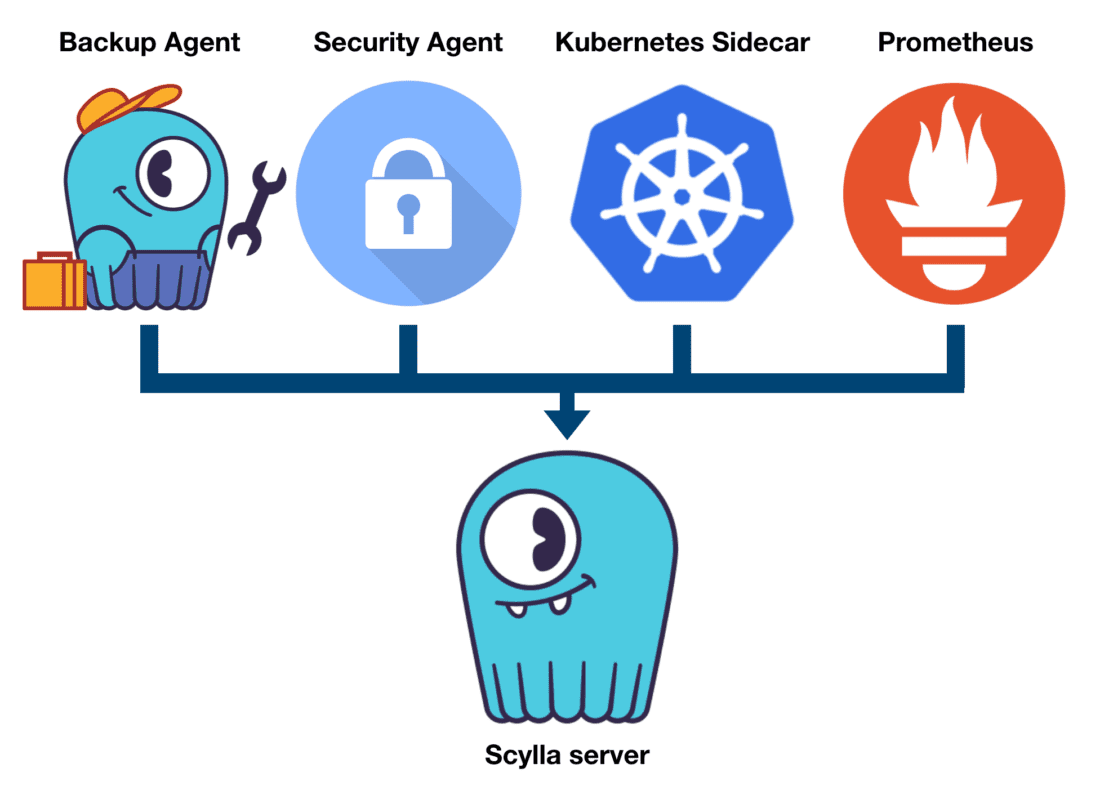
Figure 2: An example of the ScyllaDB server and auxiliary applications running in a node.
Usually those auxiliary services are lightweight and provided by ScyllaDB itself, so their memory and general resource usage are already accounted for. But in situations in which either the hardware resources are not as plentiful, or other user provided utilities are used, auxiliary services can use too many resources and create performance issues in the database.
To demonstrate that, we ran a benchmark in a machine with 64 vCPUs where we read random keys from the database for 15 minutes and expect to fetch them mostly from the cache— which stresses the CPU in isolation. First, the database was running alone in the machine (the Baseline), and in a second run we have fired up 16 CPU hogs of the form:
/bin/sh -c "while true; do true; done" &While running the command true is not really a common practice (we certainly hope), this could represent other software like some reporting or backup tool that does intense computations for a brief period of time.
How does that affect our throughput and latency?
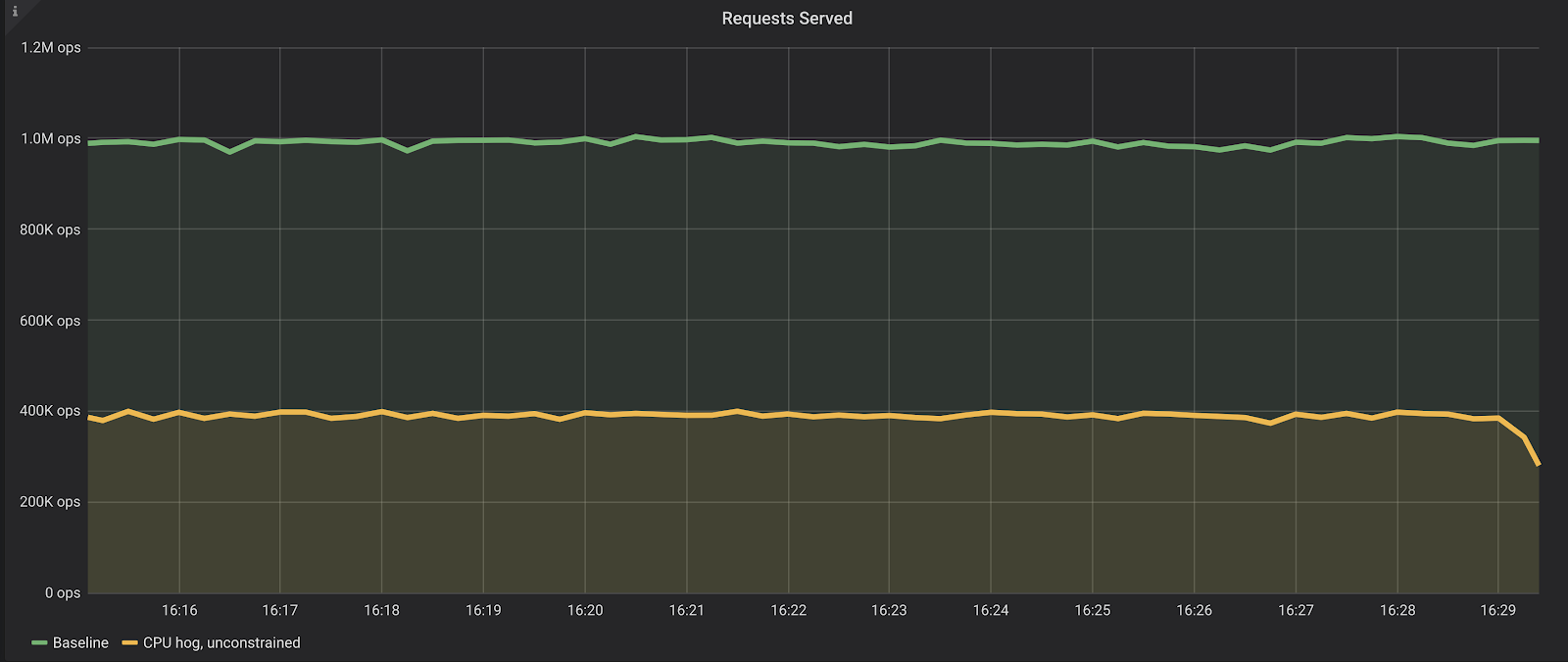
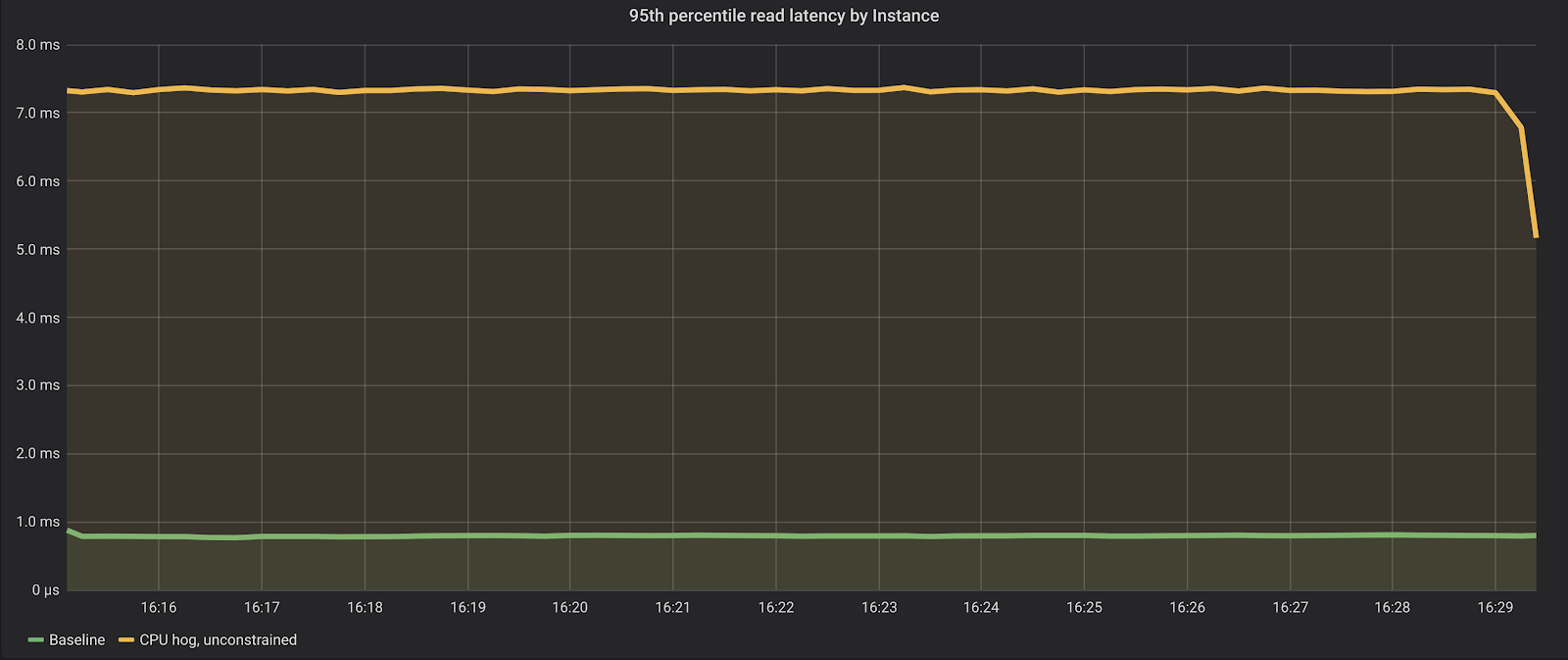
As we can see, from roughly 1 million reads per second with a lower than 1 millisecond p95 (server-side latencies), the benchmark is now only able to sustain 400 thousand reads per second, with a much higher p95, over 7 milliseconds.
That’s certainly bad news to any application connected to this database.
Systemd slices in practice
Systemd slices work in a hierarchical structure. Each slice can have a name, with parts of the hierarchy separated by the “-” character. In our example, we created two slices: scylla-server and scylla-helper. That means a top-level entity called “scylla” will be created, and every relative share assignment will then be done with respect to that.
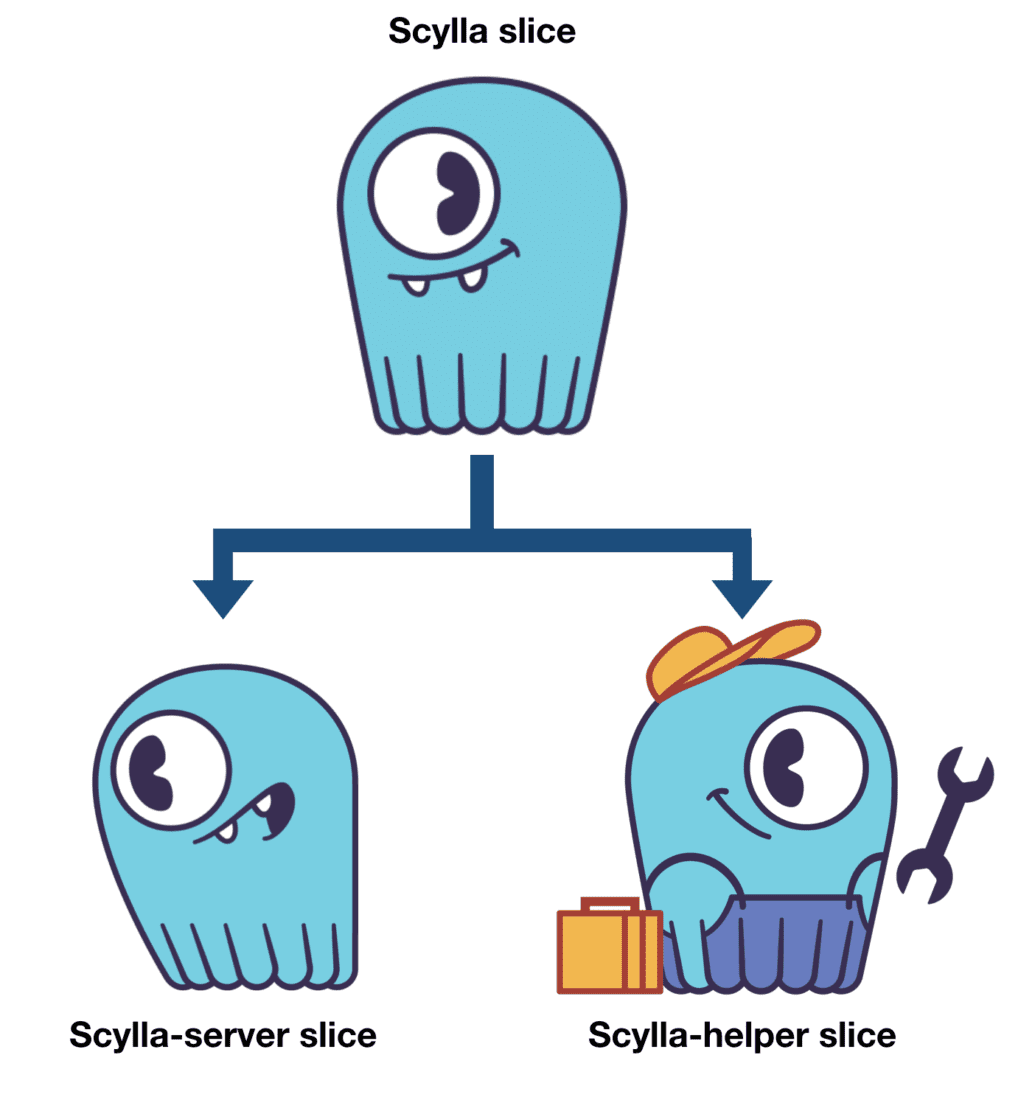
Figure 3: Systemd slices hierarchy: there is a “scylla” slice that sits at the top level, and all shares definition will be applied with respect to that. The database processes will be inside “scylla-server”, and all agents and helper processes will be inside “scylla-helper.”
We then define the following slices:
ScyllaDB-helper:
[Unit]
Description=Slice used to run companion programs to ScyllaDB. Memory, CPU and IO restricted
Before=slices.target
[Slice]
MemoryAccounting=true
IOAccounting=true
CPUAccounting=true
CPUWeight=10
IOWeight=10
MemoryHigh=4%
MemoryLimit=5%
CPUShares=10
BlockIOWeight=10ScyllaDB-server:
[Unit]
Description=Slice used to run ScyllaDB. Maximum priority for IO and CPU
Before=slices.target
[Slice]
MemoryAccounting=true
IOAccounting=true
CPUAccounting=true
MemorySwapMax=1
CPUShares=1000
CPUWeight=1000We will not get into details about what each of those mean, since the SystemD documentation is quite extensive. But let’s compare, for instance, the “CPUWeight” parameter: By using 1000 for the server and 10 for the helper slice, we are informing Systemd that we believe the server is 100 times more important if there is CPU contention. If the database is not fully loaded, the helper slice will be able to use all remaining CPU. But when contention happens, the server will get roughly 100 times more CPU time.
With the slices defined, we then add a Slice directive to the service’s unit files. For instance, the scylla-server.service unit file now has this:
[Service]
...
Slice=scylla-server.sliceSo what is the result of repeating the same benchmark, with the same heavy CPU user, but now constraining it to the scylla-helper slice, while the server is placed into the scylla-server slice?
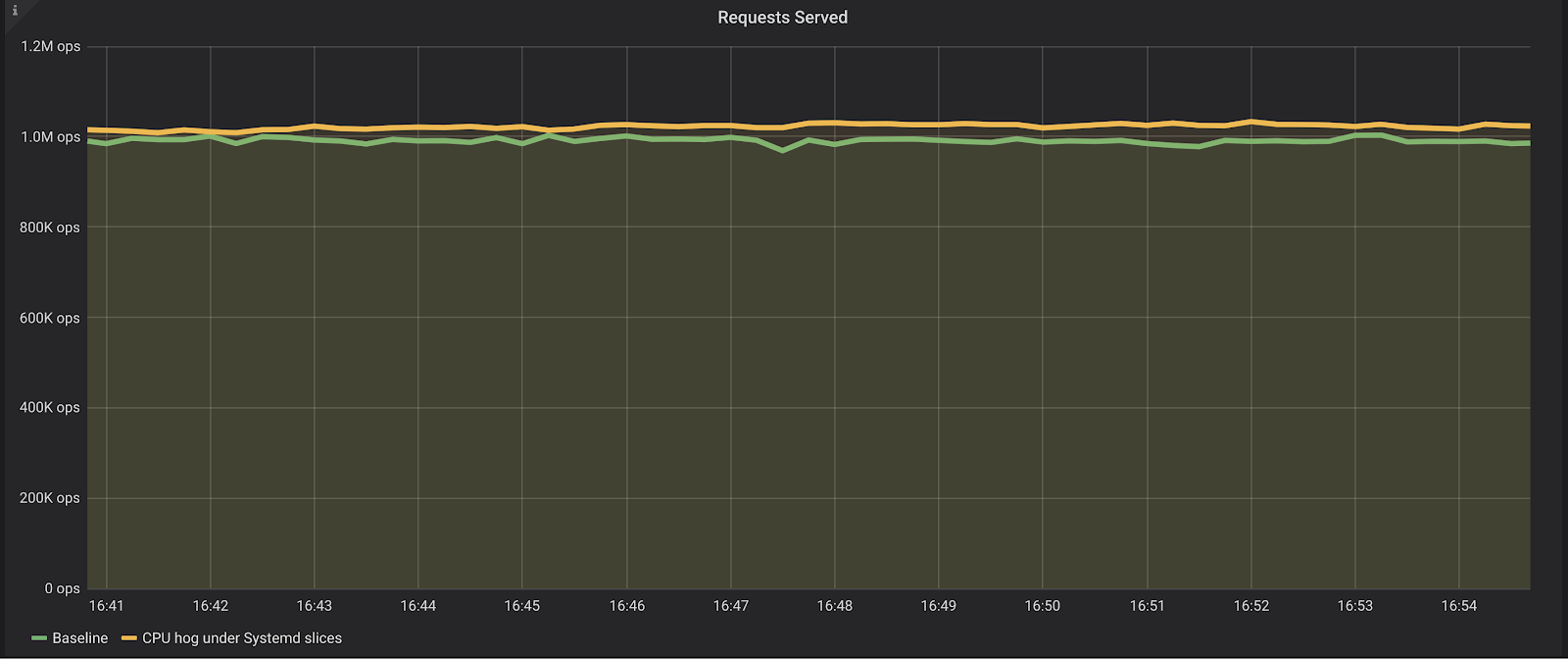
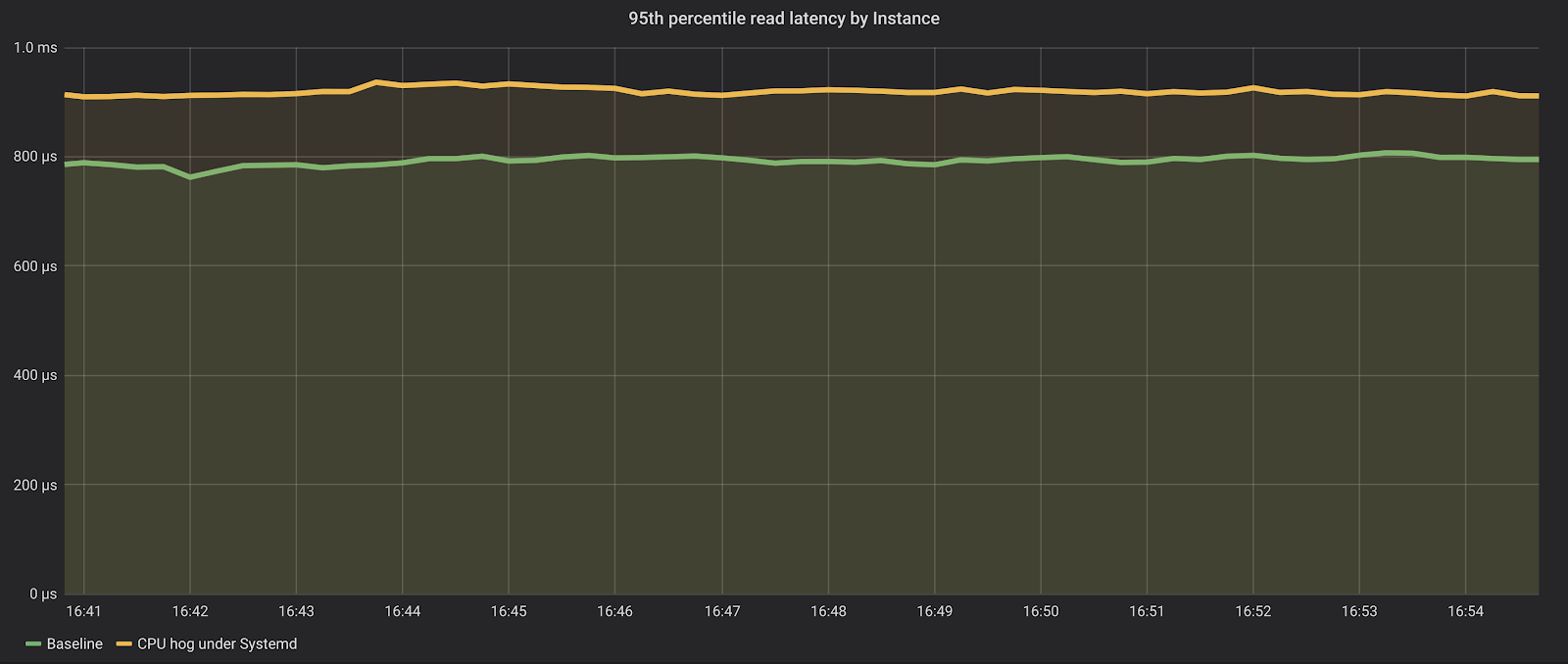
As we can see, the impact on the database is now much lower. The database is still able to sustain about the same amount of requests (around a million reads per second), and the latencies on the p95 are just a bit higher, but still under one millisecond.
We have successfully leveraged the systemd slices infrastructure to protect the central piece of the database infrastructure— the database server— from its auxiliary agents using too much resources. And while our example focused on CPU utilization, Systemd slices can also control memory usage, swap preference, I/O, etc.
Bonus content – ad hoc commands
Systemd slices are a powerful way to protect services that are managed by systemd from each other. But what if I just want to run some command, and am too worried that it may use up precious resources from the main service?
Thankfully, systemd provides a way to run ad-hoc commands inside an existing slice. So the cautious admin can use that too:
sudo systemd-run --uid=$(id -u scylla) --gid=$(id -g scylla) -t --slice=scylla-helper.slice /path/to/my/toolAnd voila, resource protection achieved.
Conclusion
Systemd slices exposes the cgroups interface — which underpins the isolation infrastructure used by Docker and other Linux container technologies — in an elegant and powerful way. Services managed by Systemd, like databases, can use this infrastructure to isolate their main components from other auxiliary helper tools that may use too much resources.
We have demonstrated how ScyllaDB is successfully using Systemd slices to protect its main server processes from other tools like translation layers and backup agents. This level of isolation is native to systemd and can be leveraged without the need to artificially wrap the solution in heavy container technologies like docker.