ScyllaDB powers real-time AI with low latency, high throughput, and billion-scale data.
Learn More



TL;DR: Apache Cassandra is an open source, distributed NoSQL database designed for massive scalability and high availability across multiple datacenters. Originally built at Facebook, it is now managed by the Apache Software Foundation and used by thousands of organizations worldwide.
Cassandra is an open source NoSQL column store database. Begun as an internal project at Facebook to meet the company’s needs for massive scaling, the code was made open source in 2008. The current development project is managed by the Apache Software Foundation (ASF), and is formally known as Apache Cassandra™.
Cassandra Database Design Principles
Cassandra was designed to support high throughput and be horizontally scalable, “Cassandra aims to run on top of an infrastructure of hundreds of nodes… designed to run on cheap commodity hardware and handle high write throughput while not sacrificing read efficiency.” Furthermore, the Cassandra whitepaper identified the need for global data distribution: “Since users are served from data centers that are geographically distributed, being able to replicate data across data centers was key to keep search latencies down.”
Part of its design assumptions included handling failure. Failure was not just a stochastic possibility, it was a constant issue stemming from continuous growth: “Dealing with failures in an infrastructure comprised of thousands of components is our standard mode of operation… As such, the software systems need to be constructed in a manner that treats failures as a norm rather than an exception.”
Another key Cassandra design principle was to be able to auto-partition the data to scale incrementally. The system would be able to add new nodes and rebalance data across the entire cluster. (As opposed to the other then-common practice of manually partitioning, or sharding, data.)
In order to make the system highly available, and to ensure data remained durable, Cassandra implemented automated peer-to-peer replication. With multiple copies of the same data stored across nodes (data duplication), the loss of a few nodes would mean that data would still survive. Also, being peer-to-peer meant that no one node could be knocked offline to make the system unavailable. Each transaction used a different coordinator node, so there was no single point of failure.
Clusters could be defined as “rack aware” or “datacenter aware” so that data replicas could be distributed in a way that it could even survive physical outages of underlying infrastructure.
Additional Cassandra scalability features that were built in from the start included how to manage membership of nodes in the cluster, how to bootstrap nodes, and how to autoscale clusters up or down.
Cassandra Data Storage Format
A key Cassandra feature also involved how it stored data. Rather than constantly altering large monolithic, mutable (alterable) data files, the system relied upon writing files to disk in an immutable (unalterable) state. If data changed for a particular entry in the database, the change would be written to a new immutable file instead. Automatic system processes triggered by periodic, size or modification rate of the files, would gather a number of these immutable files together (each of which may have redundant or obsolete data) and write out a new single composite table file of the most current data — a process known as compaction. The format of these immutable data files are known as a Sorted Strings Tables, or SSTables.
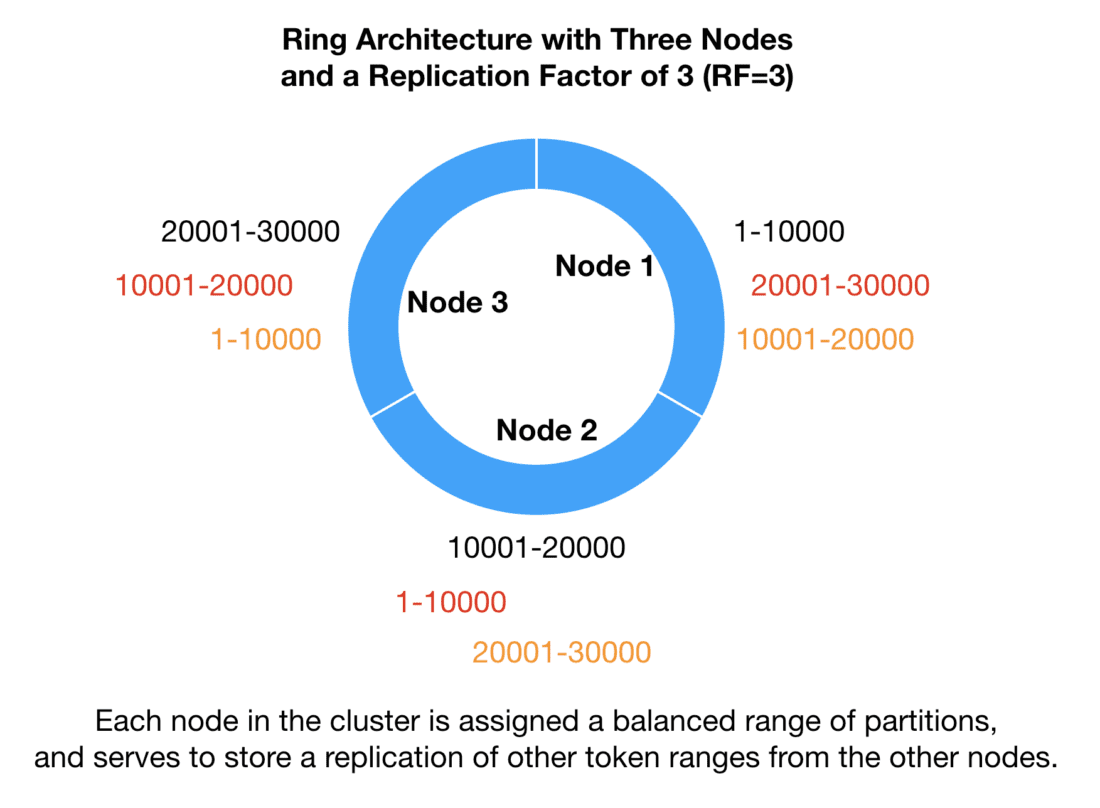
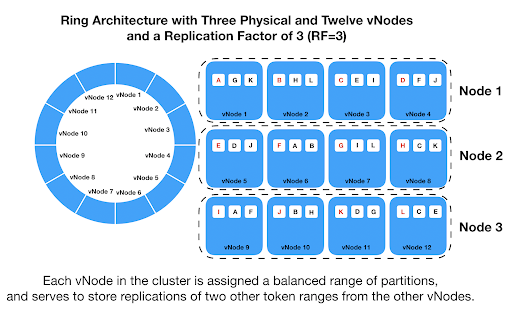
Since Cassandra spreads out data across multiple nodes, and multiple SSTable files per node, the system would need to understand where a particular record could be found. To do so, it used a theoretical ring architecture to distribute ranges of data across nodes. And, within a node, it used Bloom filters to determine which SSTable in particular held the specific data being queried.

Learn Cassandra data modeling stratgies from Discord’s Bo Ingram in this free on-demand masterclass
Cassandra Query Language (CQL)
Data access in Cassandra also required an API. The original API consisted of only three methods: insert, get and delete. Over time, these basic queries were expanded upon. The resultant API was, in time, called Cassandra Query Language (CQL). CQL appears in many ways like the ANSI Structured Query Language (SQL) used for Relational Database Management Systems (RDBMS), but CQL lacks several SQL’s specific features, such as being able to do JOINs across multiple tables. There are some commands that would be equally valid across CQL and SQL. On the other hand, there are dissimilar capabilities between the two query languages. Thus, even though CQL and SQL bear a great deal of similarity, Cassandra is formally classified as a NoSQL database.
There is also an older query interface for Cassandra known as Apache Thrift which was deprecated with the release of Cassandra 4.0.

Masterclass: Data Modeling for NoSQL Databases
Looking for extensive training on about data modeling for NoSQL Databases? Our expertsoffer a 3-hour masterclass that assists practitioners wanting to migrate from SQL to NoSQL or advance their understanding of NoSQL data modeling. This free, self-paced class covers techniques and best practices on NoSQL data modeling that will help you steer clear of mistakes that could inconvenience any engineering team.

Apache Cassandra vs DynamoDB
Apache Cassandra vs DynamoDB is one of the most common database comparisons teams face when evaluating distributed NoSQL options. Both share a common lineage — Amazon’s Dynamo paper directly inspired Cassandra’s ring architecture and replication model — but they represent fundamentally different approaches to running a distributed database. The core difference between Cassandra and DynamoDB is operational control vs. managed convenience: Cassandra is open source and runs on infrastructure you own or provision, giving operators direct control over data placement, tuning, compaction strategies, and hardware. DynamoDB is a fully managed, proprietary AWS service where Amazon controls the underlying infrastructure entirely.
The DynamoDB vs Cassandra cost model reflects this architectural split. DynamoDB charges for provisioned Read Capacity Units (RCUs) and Write Capacity Units (WCUs) whether or not they are fully consumed, with additional costs for strongly consistent reads, Global Tables replication, secondary indexes, and on-demand pricing premiums. Cassandra’s cost is the infrastructure you run it on. For write-heavy workloads at scale, Cassandra’s infrastructure-based model is typically more cost-predictable, and teams retain the ability to optimize partition design and compaction for their specific workload. Cassandra vs DynamoDB performance comparisons favor Cassandra for sustained high-throughput write workloads; DynamoDB’s serverless model is more operationally efficient for smaller, variable, or unpredictable workloads where engineering capacity to run a cluster is limited.
| Amazon DynamoDB | Apache Cassandra | |
|---|---|---|
| Deployment | Fully managed AWS service. No servers to provision, patch, or operate. | Self-managed on VMs, bare metal, or Kubernetes. Managed options via DataStax Astra, Amazon Keyspaces, and others. |
| Data model | Key-value and document. Partition key required; sort key optional. Schema-less except for primary key definition. | Wide-column. Rows addressed by partition key and clustering columns. CQL schema enforced per table. |
| Query language | Proprietary API (GetItem, Query, Scan) plus PartiQL. Queries must use the primary key or a GSI. | Cassandra Query Language (CQL), SQL-like syntax. Queries constrained to partition key and clustering columns. |
| Consistency | Eventually consistent reads by default; strongly consistent reads available per request at twice the RCU cost. Strongly consistent reads not supported on GSIs. | Tunable per operation: ONE, QUORUM, LOCAL_QUORUM, ALL, and others. Applies to both reads and writes independently. |
| Transactions | ACID transactions via TransactWriteItems and TransactGetItems across up to 100 items in one or more tables. | Lightweight transactions (LWT) via Paxos for conditional writes on a single partition. Multi-row ACID transactions targeted for Cassandra 6.0, currently in alpha |
| Secondary indexes | Local secondary indexes (defined at table creation) and global secondary indexes (added any time). GSI reads are eventually consistent. Multi-attribute composite GSI keys added Nov 2025. | Secondary indexes are local per node; querying one requires a scatter-gather read across all nodes. Most production teams avoid them and denormalize into separate tables instead. |
| Partition limits | Hard limit of 3,000 RCUs and 1,000 WCUs per second per partition, regardless of overall table capacity. | No enforced per-partition throughput limit. Hot keys cause load imbalance but result in latency degradation rather than hard throttling. |
| Item / row size | 400 KB maximum per item. | No hard row size limit. Recommended partition size is under 100 MB. |
| Scaling | Automatic. On-demand mode scales to any traffic level; provisioned mode with auto-scaling also available. | Horizontal scaling by adding nodes. Linear scale-out by design; operators manage rebalancing and ring topology. |
| Multi-region | Global tables: managed active-active replication. Multi-Region strong consistency (zero RPO) went GA Jun 2025. Cross-account replication added Feb 2026. | Built-in multi-datacenter replication via NetworkTopologyStrategy. Fully operator-configured. |
| License | Proprietary AWS service. | Open source, Apache 2.0. |
| Pricing model | Per-request (on-demand) or provisioned capacity. Separate charges for storage, streams, global tables, backups, and DAX. | Infrastructure cost only. No per-request charges. |
When to Use Cassandra vs DynamoDB
When to use Cassandra vs DynamoDB depends primarily on workload predictability, infrastructure strategy, and data model requirements. Cassandra is the better fit for teams that need fine-grained control over consistency, data placement across regions, and compaction behavior — especially for globally distributed, write-heavy workloads where tuning the cluster directly unlocks performance gains. DynamoDB is the better fit for teams with variable or unpredictable traffic, organizations fully committed to the AWS ecosystem, or teams without the operational bandwidth to run and tune a distributed database cluster.
For teams considering a Cassandra to DynamoDB migration, the data models are not directly compatible. Cassandra uses CQL (Cassandra Query Language), which closely resembles SQL and supports flexible primary key design, range scans, and secondary indexes. DynamoDB uses its own API with a partition key and sort key model that requires remodeling every table and rewriting all queries. A Cassandra to DynamoDB migration is a full application rewrite, not a lift-and-shift. For many teams, the long-term operational savings of moving to a managed service do not offset the upfront migration cost. A Cassandra-compatible alternative — such as ScyllaDB, which uses the same CQL interface and SSTable format — provides a lower-friction migration path with significant performance improvements and a managed cloud option. ScyllaDB also offers a DynamoDB-compatible API, which provides a no-friction migration path for DynamoDB applications.
Cassandra vs Aerospike
Cassandra vs Aerospike is a comparison between two distributed databases with different architectural bets. Apache Cassandra is a wide-column store built on the LSM-tree model, optimized for high write throughput across commodity hardware at massive scale, with a flexible data model that supports wide rows, time series, and secondary indexes via CQL. Aerospike is a key-value store designed for sub-millisecond reads, using a hybrid memory architecture that stores indexes in RAM and data directly on SSDs through its own custom storage engine — bypassing the Linux page cache entirely. Apache Cassandra vs Aerospike comparisons favor Aerospike for pure point-read latency on key-value workloads; Cassandra’s broader data model and open-source ecosystem make it more versatile for operational workloads with complex access patterns.
The most significant architectural difference in the Cassandra vs Aerospike comparison is the runtime: Cassandra runs in the JVM and is subject to garbage collection pauses that affect tail latency under load. Aerospike is written in C and as such avoids JVM GC pauses entirely. For use cases like real-time bidding, ad targeting, and session stores — where single-digit millisecond P99 reads are a hard requirement — Aerospike’s architecture has a structural advantage. Cassandra’s broad CQL compatibility, wide ecosystem of integrations, and proven deployments at petabyte scale make it the stronger choice for teams that need more than a pure key-value lookup pattern.
| Apache Cassandra | Aerospike | |
|---|---|---|
| Deployment | Self-managed on VMs, bare metal, or Kubernetes. Managed options via DataStax Astra, Amazon Keyspaces, and others. | Self-managed (any cloud, on-prem, or bare metal), Aerospike Cloud Managed Service (Aerospike SREs operate within your cloud account), or Aerospike Cloud (fully managed DBaaS). |
| Architecture | Masterless peer-to-peer ring. Data distributed via consistent hashing across nodes. Written in Java; storage uses LSM-tree-based SSTables. | Masterless shared-nothing design. Written in C. Hybrid Memory Architecture: primary indexes kept in DRAM, data stored on NVMe SSDs. All-in-memory mode also supported. |
| Data model | Wide-column. Rows addressed by partition key and clustering columns. CQL schema enforced per table. | Multi-model: key-value, document (JSON), graph, and vector search. Flex-schema; bins (columns) need not be predefined. |
| Query language | Cassandra Query Language (CQL), SQL-like syntax. Queries constrained to partition key and clustering columns. | Proprietary API (get, put, delete, batch operations). Supports secondary index queries and scan operations. No SQL-compatible query layer. |
| Consistency | Tunable per operation: ONE, QUORUM, LOCAL_QUORUM, ALL, and others. Applies to both reads and writes independently. | Two configurable modes per namespace: AP (eventual consistency) and CP (strong consistency, linearizable reads). CP mode is Enterprise Edition only. Jepsen-tested since Database 4.0 (2018). |
| Transactions | Lightweight transactions (LWT) via Paxos for conditional writes on a single partition. Multi-partition ACID transactions via the Accord protocol are targeted for Cassandra 6.0, currently in alpha. | Distributed ACID transactions with strict serializability added in Database 8.0 (January 2025), within a single namespace. Requires Enterprise Edition. Scans and queries cannot participate in transactions. |
| Secondary indexes | Secondary indexes are local per node; querying one requires a scatter-gather read across all nodes. Most production teams avoid them and denormalize into separate tables instead. | Secondary indexes stored in DRAM. Expression indexes (Database 8.1, August 2025) allow indexes on computed values. Secondary index queries may return stale results during data migration in CP mode. |
| Scaling | Horizontal scaling by adding nodes. Linear scale-out by design; operators manage rebalancing and ring topology. | Horizontal scaling by adding nodes; the distribution layer automates rebalancing. Linear scale-out by design. |
| Multi-region | Built-in multi-datacenter replication via NetworkTopologyStrategy. Fully operator-configured. | Cross Datacenter Replication (XDR): active-passive and active-active topologies. Enterprise Edition only. Multi-namespace mapping added in Database 8.1 (August 2025). |
| License | Open source, Apache 2.0. | Community Edition is open source (AGPLv3), capped at 8 nodes and 5TB. Enterprise Edition is closed source, commercial. |
| Pricing model | Infrastructure cost only. No per-request or per-node license charges. | Enterprise licensing based on unique production data volume. Aerospike Cloud priced by cluster size and data volume. Exact pricing requires sales engagement. |
Cassandra vs Aerospike Performance
Cassandra vs Aerospike performance comparisons consistently show Aerospike with lower P99 read latency for point-lookup workloads on key-value data. Aerospike’s custom SSD storage engine bypasses the Linux page cache and is free from JVM garbage collection as a latency source, giving it a structural advantage in tail latency for pure read workloads. In write-heavy scenarios, the Cassandra vs Aerospike performance comparison narrows: Cassandra’s LSM-tree write path appends data sequentially without read-modify-write cycles, delivering competitive write throughput on commodity SSDs. Aerospike’s in-place update model can introduce write amplification at high update rates.
For teams evaluating Cassandra and Aerospike on performance, the right choice depends on workload shape. Aerospike outperforms Cassandra on sub-millisecond key lookups at high concurrency. Cassandra outperforms Aerospike when workloads involve wide rows, range queries, or rich data models that Aerospike’s key-value architecture does not natively support. Teams that need Cassandra’s data model with lower latency than Cassandra delivers increasingly evaluate ScyllaDB: it is API-compatible with Cassandra, written in C++ without a JVM, and with a close to the hardware design that maximizes performance — combining Cassandra’s data model flexibility with performance characteristics closer to Aerospike’s on read-heavy workloads.
Beyond performance, here is an independent benchmark on Cassandra vs Aerospike resilience.
What is tunable consistency in Apache Cassandra?
Apache Cassandra allows developers to set the consistency level per query — from eventual consistency (ONE) to strong consistency (QUORUM or ALL). This lets teams trade off between latency and data accuracy based on the needs of each use case.
What programming languages and drivers does Apache Cassandra support?
Apache Cassandra has official drivers for Java, Python, Node.js, C#, C++, Go, and Ruby, maintained by the Apache Cassandra project and DataStax. Third-party drivers and integrations are also available for most major languages and frameworks.
Can I change the replication factor of a Cassandra keyspace on a live cluster?
Yes. You can alter the replication factor of a keyspace on a live Apache Cassandra cluster using an ALTER KEYSPACE statement, followed by running a repair to ensure data is correctly redistributed across the new replica set.
What is the difference between Apache Cassandra and ScyllaDB?
ScyllaDB is a drop-in Apache Cassandra alternative rewritten in C++ instead of Java, eliminating JVM overhead and garbage collection pauses. ScyllaDB is API-compatible with Apache Cassandra — the same CQL drivers and tooling work without modification — but delivers significantly higher throughput and lower latency on the same hardware.