




The rationale behind ScyllaDB’s new “tablets” replication architecture, which builds upon a multiyear project to implement and extend Raft
ScyllaDB 6.0 is the first release featuring ScyllaDB’s new tablet architecture. Tablets are designed to support flexible and dynamic data distribution across the cluster. Based on Raft, this new approach provides new levels of elasticity with near-instant bootstrap and the ability to add new nodes in parallel – even doubling an entire cluster at once. Since new nodes begin serving requests as soon as they join the cluster, users can spin up new nodes that start serving requests almost instantly. This means teams can quickly scale out in response to traffic spikes – satisfying latency SLAs without needing to overprovision “just in case.”
This blog post shares why we decided to take on this massive project and the goals that we set for ourselves. Part 2 (publishing tomorrow) will focus on the technical requirements and implementation.
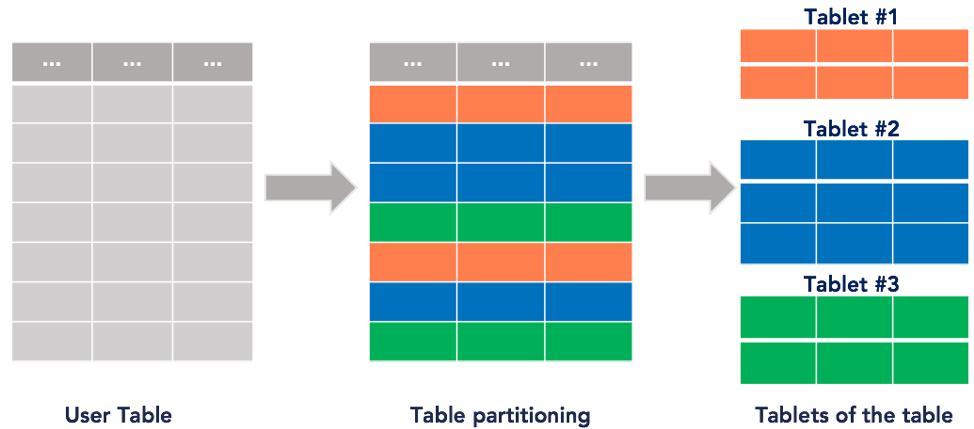
Tablets Background
First off, let’s be clear. ScyllaDB didn’t invent the idea of using tablets for data distribution. Previous tablets implementations can be seen across Google Bigtable, Google Spanner, and YugabyteDB.
The 2006 Google Bigtable paper introduced the concept of splitting table rows into dynamic sections called tablets. Bigtable nodes don’t actually store data; they store pointers to tablets that are stored on Colossus (Google’s internal, highly durable file system). Data can be rebalanced across nodes by changing metadata vs actually copying data – so it’s much faster to dynamically redistribute data to balance the load. For the same reason, node failure has a minimal impact and node recovery is fast. Bigtable automatically splits busier or larger tablets in half and merges less-accessed/smaller tablets together – redistributing them between nodes as needed for load balancing and efficient resource utilization. The Bigtable tablets implementation uses Paxos. Tablets are also discussed in the 2012 Google Spanner paper (in section 2.1) and implemented in Spanner. Paxos is used here as well.

Spanserver software stack – image from the Google Spanner paper
Another implementation of tablets can be found in DocDB, which serves as YugabyteDB’s underlying document storage engine. Here, data is distributed by splitting the table rows and index entries into tablets according to the selected sharding method (range or hash) or auto-splitting. The Yugabyte implementation uses Raft. Each tablet has its own Raft group, with its own LSM-Tree datastore (including a memtable, in RAM, and many SSTable files on disk).
YugabyteDB hash-based data partitioning – image from the YugabyteDB blog

YugabyteDB range-based data partitioning – image from the YugabyteDB blog
Why Did ScyllaDB Consider Tablets?
Why did ScyllaDB consider a major move to tablets-based data distribution? Basically, several elements of our original design eventually became limiting as infrastructure and the shape of data evolved – and the sheer volume of data and size of deployments spiked. More specifically:
- Node storage: ScyllaDB streaming started off quite fast back in 2015, but storage volumes grew faster. The shapes of nodes changed: nodes got more storage per vCPU. For example, compare AWS i4i nodes to i3en ones, which have about twice the amount of storage per vCPU. As a result, each vCPU needs to stream more data. The immediate effect is that streaming takes longer.
- Schema shapes: The rate of streaming depends on the shape of the schema. If you have relatively large cells, then streaming is not all that CPU-intensive. However, if you have tiny cells (e.g., numerical data common with time-series data), then ScyllaDB will spend CPU time parsing and serializing – and then deserializing and writing – each cell.
- Eventually consistent leaderless architecture: ScyllaDB’s eventually consistent leaderless architecture, without the notion of a primary node, meant that the database operator (you) had to bear the burden of coordinating operations. Everything had to be serialized because the nodes couldn’t reliably communicate about what you were doing. That meant that you could not run bootstraps and decommissions in parallel.
- Static token-based distribution: Static data distribution is another design aspect that eventually became limiting. Once a node was added, it was assigned a range of tokens and those token assignments couldn’t change between the point when the node was added and when it was removed. As a result, data couldn’t be moved dynamically.
This architecture – rooted in the Cassandra design – served us well for a while. However, the more we started working with larger deployments and workloads that required faster scaling, it became increasingly clear that it was time for something new. So we launched a multiyear project to implement tablets-based data distribution in ScyllaDB.
Our Goals for the ScyllaDB Tablets ImplementationProject
Our tablets project targeted several goals stemming from the above limitations:
- Fast bootstrap/decommission: The top project goal was to improve the bootstrap and decommission speed. Bootstrapping large nodes in a busy cluster could take many hours, sometimes a day in massive deployments. Bootstrapping is often done at critical times: when you’re running out of space or CPU capacity, or you’re trying to support an expected workload increase. Understandably, users in such situations want this bootstrapping to complete as fast as feasible.
- Incremental bootstrap: Previously, the bootstrapped node couldn’t start serving read requests until all of the data was streamed. That means you’re still starved for CPU and potentially IO until the end of that bootstrapping process. With incremental bootstrap, a node can start shouldering the load – little by little – as soon as it’s added to the cluster. That brings immediate relief.
- Parallel bootstrap: Previously, you could only add one node at a time. And given how long it took to add a node, increasing cluster size took hours, sometimes days in our larger deployments. With parallel bootstrap, you can add multiple nodes in parallel if you urgently need fast relief.
- Decouple topology operations: Another goal was to decouple changes to the cluster. Before, we had to serialize every operation. A node failure while bootstrapping or decommissioning nodes would force you to restart everything from scratch. With topology operations decoupled, you can remove a dead node while bootstrapping two new nodes. You don’t have to schedule everything and have it all waiting on some potentially slow operation to complete.
- Improve support for many small tables: ScyllaDB was historically optimized for a small number of large tables. However, our users have also been using it for workloads with a large number of small tables – so we wanted to equalize the performance for all kinds of workloads.
Tablets in Action
To see how tablets achieves those goals, let’s look at the following scenario:
- Preload a three-node cluster with 650 GB per replica
- Run a moderate mixed read/write workload
- Bootstrap three nodes to add more storage and CPU
- Decommission three nodes
We ran this with the Scylla-cluster-tests (open-source) test harness that we use for our weekly regression tests.
With tablets, the new nodes start gradually relieving the workload as soon as they’re bootstrapped and existing nodes start shedding the load incrementally. This offers fast relief for performance issues. In the write scenario here, bootstrapping was roughly 4X faster. We’ve tested other scenarios where bootstrapping was up to 30X faster.
Next Up: Implementation
The follow-up blog looks at how we implemented tablets. Specifically:
- Indirection and abstraction
- Independent tablet units
- A Raft-based load balancer
- Tablet-aware drivers
Finally, we wrap it up with a more extensive demo that shows the impact of tablets from the perspective of coordinator requests, CPU load, and disk bandwidth across operations.

