ScyllaDB powers real-time AI with low latency, high throughput, and billion-scale data.
Learn More



Differences Between SQL vs NoSQL
SQL and NoSQL represent two of the most common types of databases. SQL stands for Structured Query Language and is used in most modern relational database management systems (RDBMS). NoSQL means either “no SQL” (it does not use any SQL for querying) or “not only SQL” (it uses both SQL and non-SQL querying methods). NoSQL is generally used in a non-relational database (in that it doesn’t support foreign keys and joins across tables). The differences between NoSQL vs SQL databases include how they are built, the structure and types of data they hold, and how the data is stored and queried.
Relational (SQL) databases use a rigid structure of tables with columns and rows. There is one entry per row and each column contains a specific piece of information. The highly organized data requires normalization, which reduces data redundancy and improves reliability. SQL is a highly-controlled standard, supported by the American National Standards Institute (ANSI) and the International Standards Organization (ISO).
Non-relational databases are often implemented as NoSQL systems. There is not one type of NoSQL database. There are many different schemas, from key-value stores, to document stores, graph databases, time series databases and wide-column stores. Some NoSQL systems also support “multi-model” schemas, meaning they can support more than one data schema internally.
Unlike the ANSI/ISO processes for the SQL standard, there is no industry standard around implementing NoSQL systems. The exact manner of supporting various NoSQL schemas is up to the various individual software developers. Implementations of NoSQL databases can be widely divergent and incompatible. For instance, even if two systems are both key-value databases, their APIs, data models, and storage methods may be highly divergent and mutually incompatible.
NoSQL systems don’t rely on, nor can they support, joined tables.
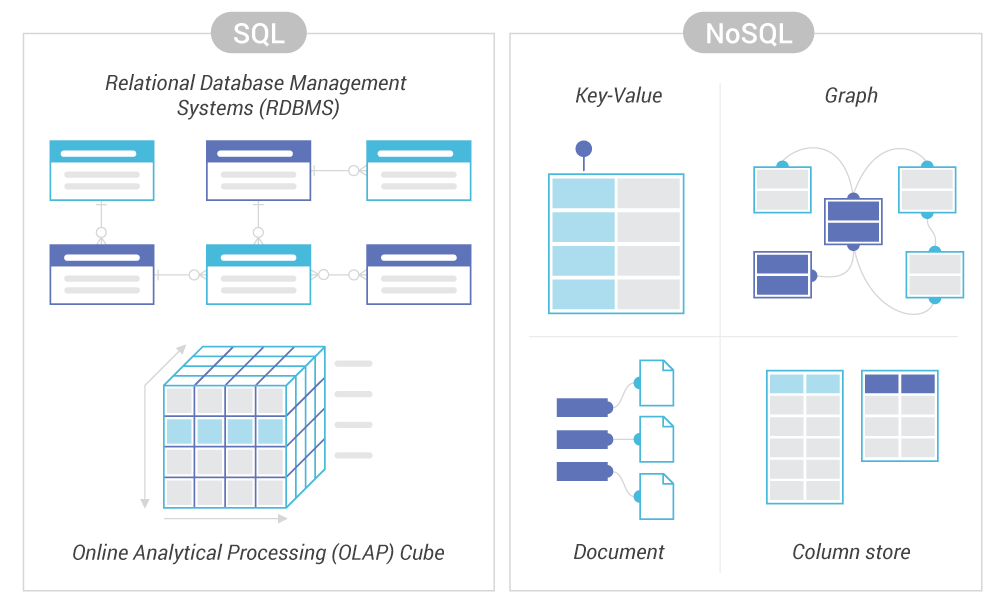
When to Use NoSQL vs SQL
NoSQL vs SQL performance comparison is based on attributes like consistency, availability and speed. The needs of an enterprise generally determine which type of database system to use.
A relational (SQL) database is ideal for handling data models that are well-understood, may not change often, require adherence to strict international standards, and for businesses that value data consistency over transaction speed.
A non-relational (NoSQL) database is ideal for companies facing changing data requirements, those that can adapt to rapidly-evolving vendor-driven standards and APIs, and those who need to deal with multiple types of data and high traffic volumes.
But there are always exceptions. Time series data models are well understood and so are key values, which are not traditional SQL models. Many NoSQL databases are consistent, though not ACID.

SQL and NoSQL Databases
Popular relational (SQL) databases include:
- IBM DB2
- Oracle Database
- Microsoft SQL Server
- MySQL
Popular non-relational (NoSQL) databases include:
- Apache Cassandra
- Apache HBase
- MongoDB
- Redis
- ScyllaDB
Common types of NoSQL databases include:
- Key-value store — Stores data with simple indexed keys and values. Examples include Oracle NoSQL database, Redis, Aerospike, Oracle Berkeley DB, Voldemort, Amazon DynamoDB and Infinity DB.
- Wide column store — Uses tables, rows and columns. But the format and naming of the columns can vary in different rows within the same table. Examples include Apache Cassandra, ScyllaDB, Datastax Enterprise, Apache HBase, Apache Kudu, Apache Parquet and MonetDB.
- Document database — A more complex and structured version of the key-value model, which gives each document its own retrieval key. Examples include Orient DB, MarkLogic, MongoDB, IBM Cloudant, Couchbase, and Apache CouchDB.
- Graph database — Presents interconnected data as a logical graph. Examples include Neo4j, JanusGraph, FlockDB and GraphDB.
Multi-model Databases
A major trend in modern databases is to support more than one data model. For example, systems that support both traditional SQL as well as one (or more) NoSQL schema. Other systems may support multiple NoSQL data models, but not SQL. The combinations are myriad.
For example Cassandra and ScyllaDB, though classified as wide column stores, also readily support key-value use cases. As well, through add-on packages such as JanusGraph, these three NoSQL systems can also support graph database schemas as well. In another example Amazon DynamoDB, though it has origins as a key-value store, also works as a document database.
Big Data Market Size: SQL vs NoSQL
A 2017 IDC report predicted worldwide revenues for operational SQL and NoSQL database management systems would increase from $27 billion in 2017 to $40.4 billion by 2022.
The market share of databases is shifting because of NoSQL database vs SQL database competition. As of 2016 SQL still represented 89 percent of the paid database market, according to Gartner. But so-called “mega-vendors” like Oracle and IBM lost two percent of the market in the past five years. And Gartner claims as much as a quarter of the SQL market consists of unpaid, open source databases like MySQL servers and PostgreSQL.
Meanwhile, the NoSQL market is expected to grow more than 20 percent annually to reach $3.4 billion by 2024, according to Market Research Media.
SQL vs CQL
Structured Query Language (SQL) is used in relational databases and other interfaces are used in non-relational databases. For example MongoDB, uses a JavaScript query API. NoSQL databases may have their own custom, proprietary interfaces, or they may share a common query method. For example, a number of NoSQL databases, including Apache Cassandra, ScyllaDB, DataStax Enterprise, and even cloud-native databases like Microsoft Azure Cosmos DB support the Cassandra Query Language (CQL).
While CQL and SQL share many similarities, a key difference between SQL and CQL is that CQL cannot perform joins against tables like SQL can. Query results are also presented differently. SQL returns data type values while CQL can return objects. CQL is also massively scalable, designed to query across a horizontally-distributed cluster of servers.
Other differences include:
SQL
- Used in relational databases (where tables can have joins between them).
- Manages structured data.
- Handles moderate volume and low velocity data from a few locations.
- Creates tables with and without a primary key.
- Adds columns on the right side of the table.
CQL
- Used in non-relational databases.
- Manages unstructured and semi-structured data.
- Handles very high volume and high velocity data from many locations.
- Creates the tables with only a primary key, which acts as a partition key.
- Adds columns in alphabetical order.
SQL and CQL have similarities, too. They both possess database sub-languages and use similar data manipulation statements to store and modify data. They share commands, including:
- “Create” for creating objects.
- “Alter” for changing structure.
- “Drop” for deleting objects.
- “Truncate” for removing records.
- “Rename” for renaming objects.
JSON in NoSQL and SQL
JSON (JavaScript Object Notation) is a format that encapsulates data, such as when it is transported from a server to a web application. It is most often employed in document-oriented databases.
JSON is a simple and lightweight format that is easy to read and write. With the rise of non-relational databases, web-based APIs and microservices, many developers prefer the JSON format. However, it can also be used to parse, store and export data across other databases, both SQL and NoSQL.
JSON lets programmers easily communicate sets of values, lists, and key-value mappings across systems. Data formats in JSON use the following forms:
- Object — unordered set of name/value pairs.
- Array — ordered collection of values.
- Value — a string, number, true/false/null, object or array.
- String — sequence of characters that follow an encoding standard.
- Number — Java numbers such as byte, short and long.
The simplicity of JSON is being embraced by application developers, who prefer JSON over the more complicated XML serialization format for transporting data. JSON also works well in agile environments because JSON allows for efficient usage of data.
This is creating demand for JSON features in both relational and non-relational databases.
Table Joins
A join connects tables based on matching columns in a SQL database. Joins create a relationship between the tables through a link known as foreign keys.
A SQL join combines data from multiple tables for the purpose of understanding the relationship between pieces of data. For example, seeing a customer’s order history. A join of the customer table and the orders table will establish the relationship between one customer and all their orders.
The types of join and join commands vary depending on which records a query retrieves. Join types can be used only after data is loaded into a relational database.
There are five types of table joins:
- Inner
- Left
- Right
- Full
- Cross
There is also a self-join when a table can join to itself. The following commands are used for join operations:
- Hash join
- Sort-merge join
- Nested loop join
Normalized vs Denormalized Data
The difference between normalized and denormalized data is the method used for storing and retrieving it.
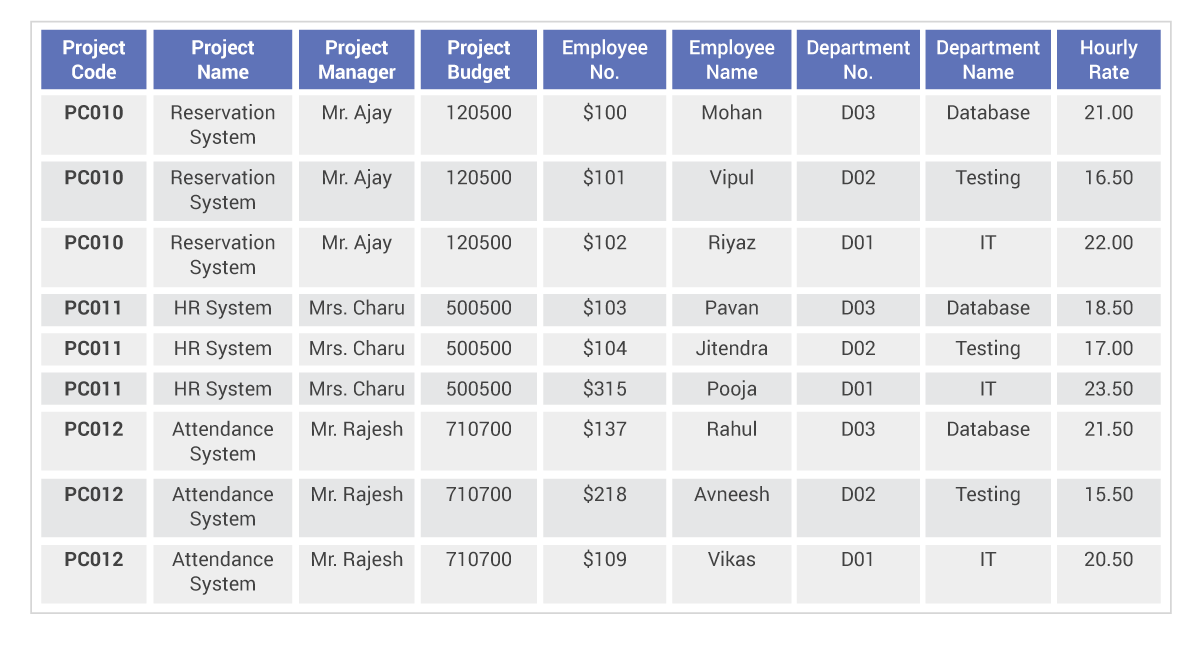
Denormalized data is combined in one table. This speeds up data retrieval because a query doesn’t have to search multiple tables to find information as it would in the normalized process. Everything is in one place, but data may be duplicated. The added speed comes at the expense of more data redundancy and less data integrity.
This is what a denormalized database looks like:
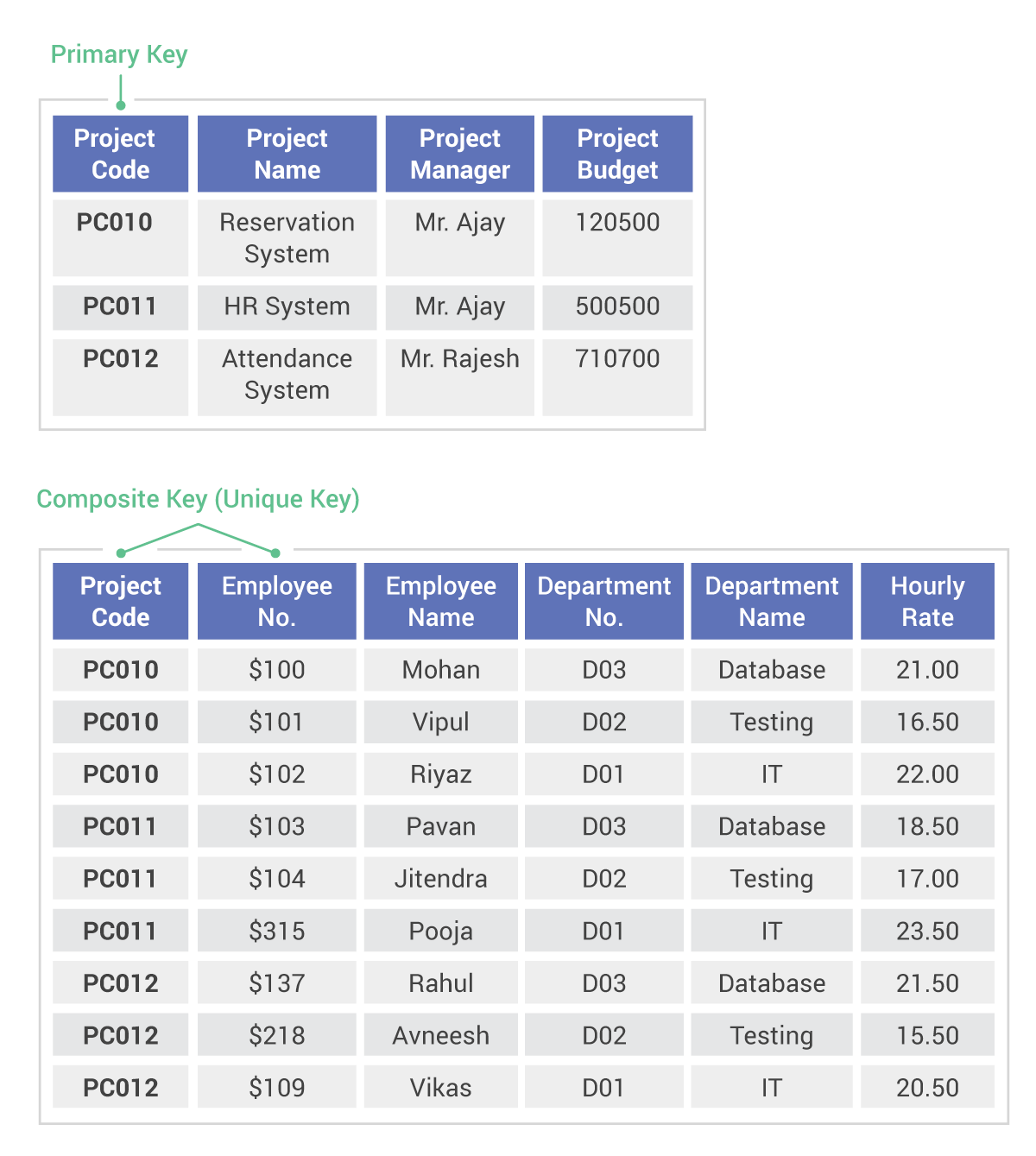
Normalized data is stored in multiple tables. One type of data is organized in one table. Related data is stored in another table. Then table JOINs are used to connect relationships between the tables. The benefits of normalized data include reduced redundancy, better consistency and greater data integrity. But the practice can produce slow results, especially when there are complex queries with a lot of data to process.
In a normalized database, there are no repeating fields or columns. The repeating fields are put into new database tables along with the key from the unnormalized database table.
This is what a normalized database table looks like:
Other differences include:
Normalized
- Used in OLTP SQL systems
- Emphasis on faster insert, delete and update
- Maintains data integrity
- Eliminates redundant data sets
- Increases number of tables and JOINS
- Optimizes disk space
Denormalized
- Used in OLAP SQL systems and many NoSQL systems
- Emphasis on faster search and analysis
- Difficult to retain data integrity
- Increases redundant data
- Reduces number of tables and can reduce or eliminate JOINS
- Wastes disk space because the same data is stored in different places
Databases don’t have to be exclusively normalized or denormalized. There is a hybrid option. If speed is a concern, a SQL database can be partially denormalized by removing a certain number of JOINS. If organization and redundancy is a concern, a portion of the data can be normalized in separate tables.
Some circumstances call for denormalization. For example, a denormalized data process is preferred for applications with large tables that run multiple-JOIN queries because creating the JOINS of a normalized database can be expensive and time consuming. Applications that store unstructured data like emails, images and videos are also better suited for denormalization.
Strong vs Eventual Consistency
Consistency refers to a database query returning the same data each time the same request is made. Strong consistency means the latest data is returned, but, due to internal consistency methods, it may result with higher latency or delay. With eventual consistency, results are less consistent early on, but they are provided much faster with low latency.
Early results of eventual consistency data queries may not have the most recent updates. This is because it takes time for updates to reach replicas across a database cluster.
In strong consistency, data is sent to every replica the moment a query is made. This causes delay because responses to any new requests must wait while the replicas are updated. When the data is consistent, the waiting requests are handled in the order they arrived and the cycle repeats.
SQL databases generally support strong consistency, which makes them useful for transactional data in the banking and finance industries.
CQL-compliant NoSQL databases have tunable consistency, which provides low latency and high write throughput best suited for analytical and time-series data.
Other NoSQL databases span the gamut. Some may support strong consistency and others eventual consistency.
CAP Theorem
The CAP theorem explains why a distributed database cannot guarantee both consistency and availability in the face of network partitions. The theorem says an application can guarantee only two of the following three features at the same time:
-
- Consistency — the same answer is given to all
- Availability — access continues, even during a partial system failure
- Partition tolerance — operations remain in tact, even if some nodes can’t communicate
A useful compromise is to allow for eventual consistency in favor of better scalability. Determining if your application data is a suitable candidate for eventual consistency is a business decision.
When an application gives up strong consistency — where every copy of the data in the system has to match before the transaction is considered complete — it instead becomes eventually consistent. This compromise is often made for the purpose of better scalability. The decision is based on business considerations: how important is each transaction? For situations where each write of data is vital then strong consistency is a requirement. For situations where the aggregate speed or scale of big data management is more important than the specific correctness of any one particular query result, then eventual consistency may make sense.
Cloud-native applications tend to choose the guarantees of availability and partition tolerance over strong consistency. This is because cloud-native applications usually prefer to keep up with scalability targets than to ensure database nodes are always in communication.
While there are three elements in the CAP theorem, the trade-off is mostly between two: availability and consistency. The third element, partition-tolerance, is often considered a requirement; there is no way you can design a network-based distributed system that can avoid a partitioned state, even if temporarily. Therefore partition-tolerance is a necessity for scalability and resiliency, especially when it comes to NoSQL databases.
ACID vs BASE
ACID and BASE are models of database design. The ACID model has four goals that stand for:
- Atomicity — If any part of a transaction isn’t executed successfully, the entire operation is rolled back.
- Consistency — Ensures that a database remains structurally sound with every transaction.
- Isolation — Transactions occur independently of each other and the access to data is moderated.
- Durability — All transaction results are permanently preserved in the database.
Relational databases and some NoSQL databases (those that support strong consistency) that meet these four goals are considered ACID-compliant. This means data is consistent after transactions are complete.
Other non-relational NoSQL databases, however, turn to the BASE model to achieve benefits like scale and resilience. BASE stands for:
- Basic Availability — Data is available most of the time, even during a failure that disrupts part of the database. Data is replicated and spread across many different storage systems.
- Soft-state — Replicas are not consistent all the time.
- Eventual consistency — Data will become consistent at some point in time, with no guarantee when.
BASE principles are less strict than ACID guarantees. BASE values availability over any other value because BASE users care most about scalability. Industries like banking that require data reliability and consistency depend on an ACID-compliant database.
Distribution and Scalability
Scaling up a relational SQL database often requires taking it offline so new hardware can be added to the servers. But the hardware would remain even when it came time to scale down.
Single node peer-to-peer architecture, however, allows for easy scalability. As new nodes are added to the database clusters, performance is increased. This scaleout architecture also adds more servers running replicas of the database. A simple click of the mouse can scale clusters up and down to meet demand.
B-Trees vs Log-Structured Merge Trees
B-tree data structures were created nearly 50 years ago to sort, search, insert and delete data in logarithmic time. The B-tree uses row-based storage that allows for low latency and high throughput. Many SQL databases use traditional B-tree architecture. A newer version of this data structure, known as a B+ tree, which puts all the data in leaf nodes, therefore supporting even greater fan-out. B+ trees also support ordered linked lists of data elements and data stored in RAM. B+ trees are used across many modern SQL and NoSQL systems.
Log-structured merge trees (also known as LSM trees) were created in the mid-1990s to meet the demand for larger datasets. The LSM tree has become the preferred way to manage fast-growing data because it is best suited for data with high write volume. LSM trees are commonly used in NoSQL databases.
LSM trees can write sequentially much faster than B-trees and even B+ trees. For this reason, B-trees are best for applications that don’t require high write throughput. LSM trees are designed for high write throughput, but they use more memory and CPU resources than B-trees. B+ trees may have better read performance than LSM trees.
Dense vs Sparse Data
Dense data refers to databases that require almost all fields of a database to be filled with data. Imagine a web form where most almost every element was a “required” field. In the database, there would be data for nearly every cell. .
Sparse data, on the other hand, refers to a database where there may be a very low percentage of fields where information is available. For example, imagine a list of all the jobs in the world. How many of those jobs have you personally held? If you could check two or even twelve or twenty jobs over your career, it would still leave most jobs blank for your record.
The benefit of sparse data is the ability to see large clusters of information that show clear answers in the midst of the empty cells. The uniqueness of sparse data makes it valuable for businesses that seek customer insights based on it.
The flood of dense data might flow faster, but it provides so much information that everything looks the same and it becomes impossible to see a meaningful trend.
For this reason, sparse data is better suited for NoSQL database solutions that put more value on analysis than speed.
How Does ScyllaDB Fit In?
ScyllaDB, the fastest NoSQL database, is a column-oriented NoSQL database that provides a dynamic schema for unstructured data. ScyllaDB lets users add more columns and data types after initial creation of the table.
ScyllaDB is an open source NoSQL database that uses the Cassandra Query Language (CQL), along with ScyllaDB-specific extensions to CQL. It is similar to Structured Query Language (SQL) common in relational database management systems (RDBMS) in that it describes data organized into tables, by columns and rows. CQL differs from relational databases in that, though ScyllaDB does support multiple tables, it does not support JOIN operations between its tables.
Instead of the B-tree format common in traditional RDBMS, ScyllaDB uses a log-structured merge tree (LSM tree) storage engine that is more efficient for storing sparse data. This column-oriented data structure enables creation and management of wide rows, which is why ScyllaDB can be classified as one of the graph databases or wide column stores.
ScyllaDB can be used in conjunction with other SQL or NoSQL databases and become part of broader data ecosystems through integration with open source platforms like Apache Kafka and Apache Spark. ScyllaDB Cloud is a fully managed NoSQL DBaaS offering that gives you access to fully managed ScyllaDB clusters with automatic backup, repairs, performance optimization, security hardening, 24*7 maintenance and support. All for a fraction of the cost of other DBaaS providers.