





Disney+ Hotstar, India’s most popular streaming service, accounts for 40% of the global Disney+ subscriber base. Disney+ Hotstar offers over 100,000 hours of content on demand, as well as livestreams of the world’s most-watched sporting events (Indian Premier League, with over 25 million concurrent viewers). IPL viewership has grown an order of magnitude over the past six years. And with Ms. Marvel, the first south Asian heritage superhero making her debut this month, Disney+ Hotstar’s rapid growth will certainly continue by reaching new audiences and demographics.
The “Continue Watching” feature is critical to the on-demand streaming experience for the 300 million-plus monthly active users. That’s what lets you pause a video on one device and instantly pick up where you left off on any device, anywhere in the world. It’s also what entices you to binge-watch your favorite series: complete one episode of a show and the next one just starts playing automatically.
However, it’s not easy to make things so simple. In fact, the underlying data infrastructure powering this feature had grown overly complicated. It was originally built on a combination of Redis and Elasticsearch, connected to an event processor for Kafka streaming data. Having multiple data stores meant maintaining multiple data models, making each change a huge burden. Moreover, data doubling every six months required constantly increasing the cluster size, resulting in yet more admin and soaring costs.
This blog shares an inside look into how the Disney+ Hotstar team led by Vamsi Subash Achanta (architect) and Balakrishnan Kaliyamoorthy (senior data engineer) simplified this data architecture for agility at scale.
TL;DR First, the team adopted a new data model, then they moved to a high-performance low-latency database-as-a-service (ScyllaDB Cloud). This enabled them to free up resources for the many other priorities and projects on the team’s plate. It also lowered latencies for both reads and writes to ensure the snappy user experience that today’s streaming users expect – even with a rapidly expanding content library and skyrocketing subscriber base.
Inside Disney+ Hotstar’s ‘Continue Watching’ Functionality
At Disney+ Hotstar, “Continue Watching” promotes an engaging, seamless viewing experience in a number of ways:
- If the user plays a video and then later pauses or stops it, the video is added to their “Continue Watching” tray.
- Whenever the user is ready to resume watching the video on any device, they can easily find it on the home page and pick up exactly where they left off.
- When the user completes one episode in a series, the next episode is added to their “Continue Watching” tray.
- If new episodes are added to a series that the user previously completed, the next new episode is added to their “Continue Watching” tray.
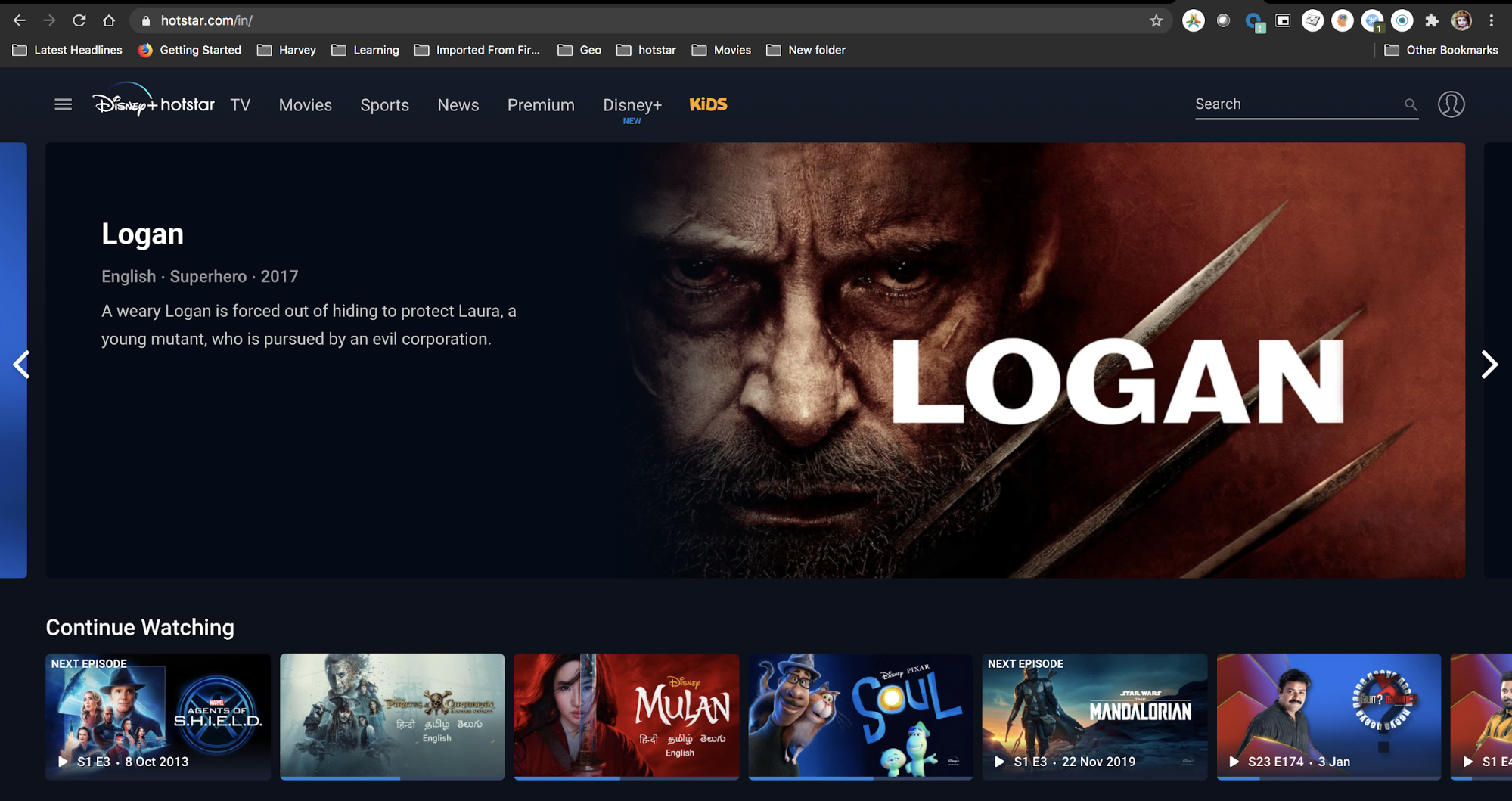
Figure 1: One example of Disney+ Hotstar’s “Continue Watching” functionality in action
Disney+ Hotstar users watch an average of 1 billion minutes of video every day. The company also processes nearly 100 to 200 gigabytes of data daily to ensure that the “Continue Watching” functionality is accurate for hundreds of millions of monthly users. Due to the volatile nature of user watching behavior, Disney+ Hotstar needed a database that could handle write-heavy workloads. They also needed a database that could scale appropriately during high traffic times, when the request volume increases by 10 to 20 times within a minute.
Figure 2 shows how the “Continue Watching” functionality was originally architected.
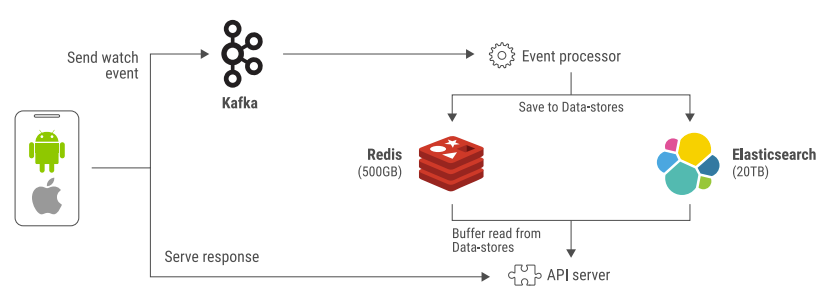
Figure 2: A look at the legacy architecture that Disney+ Hotstar decided to replace
First, the user’s client would send a “watch video” event to Kafka. From Kafka, the event would be processed and saved to both Redis and Elasticsearch. If a user opened the home page, the backend was called, and data was retrieved from Redis and Elasticsearch. Their Redis cluster held 500 GB of data, and the Elasticsearch cluster held 20 terabytes. Their key-value data ranged from 5 to 10 kilobytes per event. Once the data was saved, an API server read from the two databases and sent values back to the client whenever the user next logged in or resumed watching.
Redis provided acceptable latencies, but the increase in data size meant that they needed to horizontally scale their cluster. This increased their cost every three to four months. Elasticsearch latencies were on the higher end of 200 milliseconds. Moreover, the average cost of Elasticsearch was quite high considering the returns. They often experienced issues with node maintenance and manual effort was required to resolve the issues.
Here’s the data model behind that legacy data architecture:
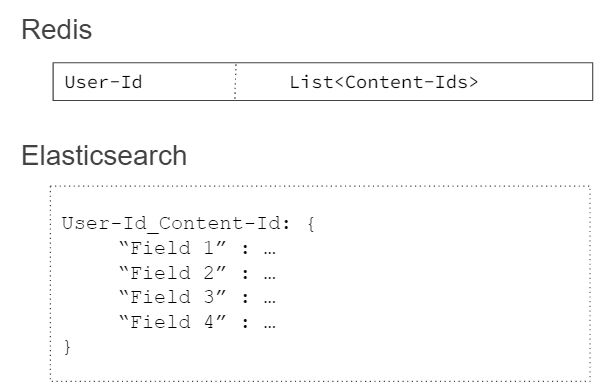
Not surprisingly, having two data stores led to some significant scaling challenges. They had multiple data stores with different data models for the same use case: one key-value and one document. With an influx of users joining Disney+ Hotstar daily, it was becoming increasingly difficult to manage all this data. Moreover, it became quite costly to maintain two data stores with different code bases and different query patterns at high scales. Every six months, they were almost doubling their data. This required an increase in clusters, which resulted in burdensome administration and spiraling costs.
Redesigning the NoSQL Data Model
The first step in addressing these challenges was designing a new data model: a NoSQL key-value data store. To simplify, they aimed for a data model with only two tables.

The User table is used to retrieve the entire “Continue Watching” tray for the given user, all at once. If a new video needs to be added to the user’s “Continue Watching” tray, it is appended to the list for the same User-Id key.
The User-Content table is used for modifying specific Content-Id data. For example, when the user resumes the video and then pauses it, the updated Timestamp is stored. When the video is fully watched, the entry can be directly queried and deleted. In this table, User-Id is the primary key and Content-Id is the secondary (clustering) key.
Selecting a New Database: The Move to ScyllaDB Cloud
The team considered a number of alternatives, from Apache Cassandra and Apache HBase to Amazon DynamoDB to ScyllaDB. Why did they ultimately choose ScyllaDB? A few important reasons:
- Performance: ScyllaDB’s deep architectural advancements deliver consistently low latencies for both reads and writes, ensuring a snappy user experience even when live events exceed 25 million concurrent viewers.
- Operational simplicity: ScyllaDB was built from the ground up to deliver self-optimizing capabilities that deliver a range of benefits, including the ability to run operational and analytics workloads against unified infrastructure, higher levels of utilization that prevent wasteful overprovisioning and significantly lower administrative overhead.
- Cost efficiency: ScyllaDB Cloud, a fully-managed database-as-a-service (NoSQL DBaaS), offers a much lower cost than the other options they considered.
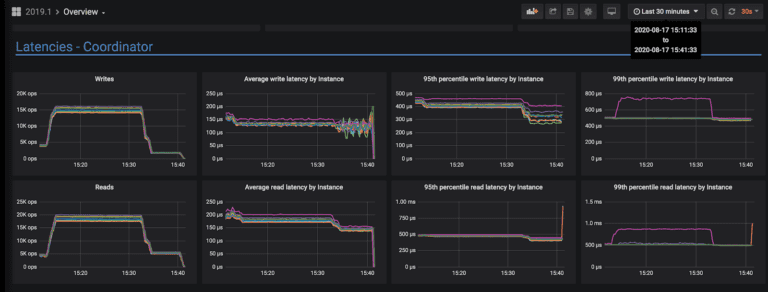 Figure 3: Performance monitoring results of ScyllaDB showing sub-millisecond p99 latencies and average read and write latencies in the range of 150 – 200 microseconds
Figure 3: Performance monitoring results of ScyllaDB showing sub-millisecond p99 latencies and average read and write latencies in the range of 150 – 200 microseconds
Migrating to ScyllaDB Cloud with Zero Downtime
From Redis and Elasticsearch to ScyllaDB Cloud
Disney+ Hotstar’s migration process began with Redis. The Redis to ScyllaDB migration was fairly straightforward because the data model was so similar. They captured a Redis snapshot in an RDB format file, which was then converted into comma-separated value (CSV) for uploading into ScyllaDB Cloud using cqlsh. A lesson learned from their experience: Watch for maximum useful concurrency of writes to avoid write timeouts.
Running with seven threads, they migrated 1 million records in 15 minutes. To speed up the process, they scaled up the number of threads and added more machines.
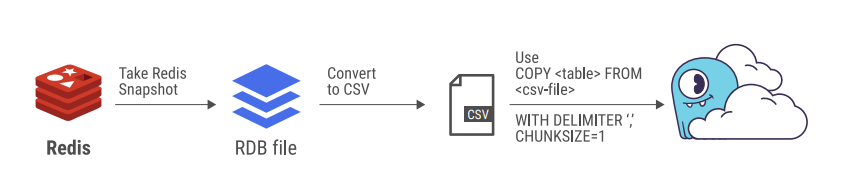
Figure 4: The Redis to ScyllaDB Cloud migration
A similar process was applied to the Elasticsearch migration. JSON documents were converted to CSV files, then CSV files were copied to ScyllaDB Cloud.
Once ScyllaDB Cloud had been loaded with the historical data from both Redis and Elasticsearch, it was kept in sync by:
- Modifying their processor application to ensure that all new writes were also made to ScyllaDB.
- Upgrading the API server so that all reads could be made from ScyllaDB as well.
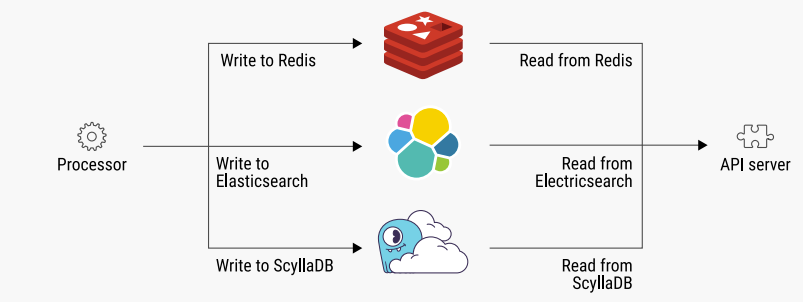
Figure 5: Moving from Redis and Elasticsearch to ScyllaDB Cloud
At that point, writes and reads could be completely cut out from the legacy Redis and Elasticsearch systems, leaving ScyllaDB to handle all ongoing traffic. This migration strategy completely avoided any downtime.

Figure 6: ScyllaDB Cloud now handles all ongoing traffic
ScyllaDB Open Source to ScyllaDB Cloud
The Disney+ Hotstar team had also done some work with ScyllaDB Open Source and needed to move that data into their managed ScyllaDB Cloud environment as well. There were two different processes they could use: SSTableloader or the ScyllaDB Spark Migrator.
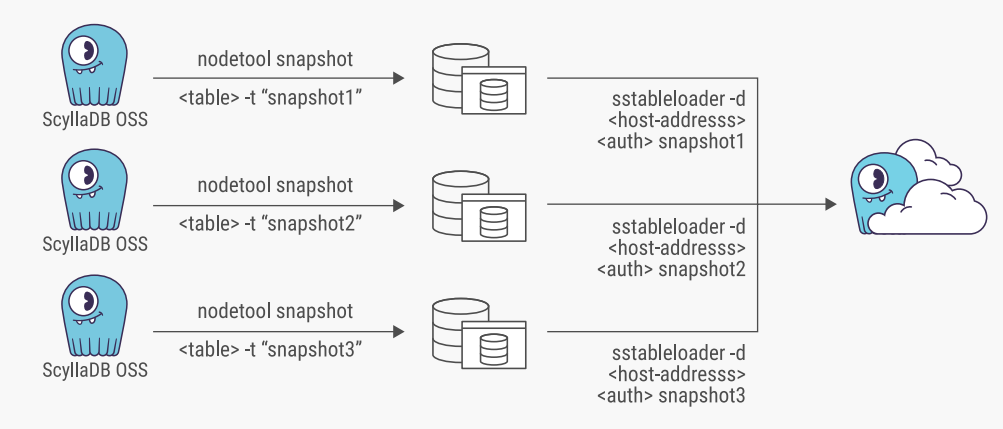
Figure 7: SSTableloader based migration from ScyllaDB open source to ScyllaDB Cloud
SSTableloader uses a nodetool snapshot of each server in a cluster, and then uploads the snapshots to the new database in ScyllaDB Cloud. This can be run in batches or all at once. The team noted that this migration process slowed down considerably when they had a secondary (composite) key. To avoid this slowdown, the team implemented the ScyllaDB Spark Migrator instead.
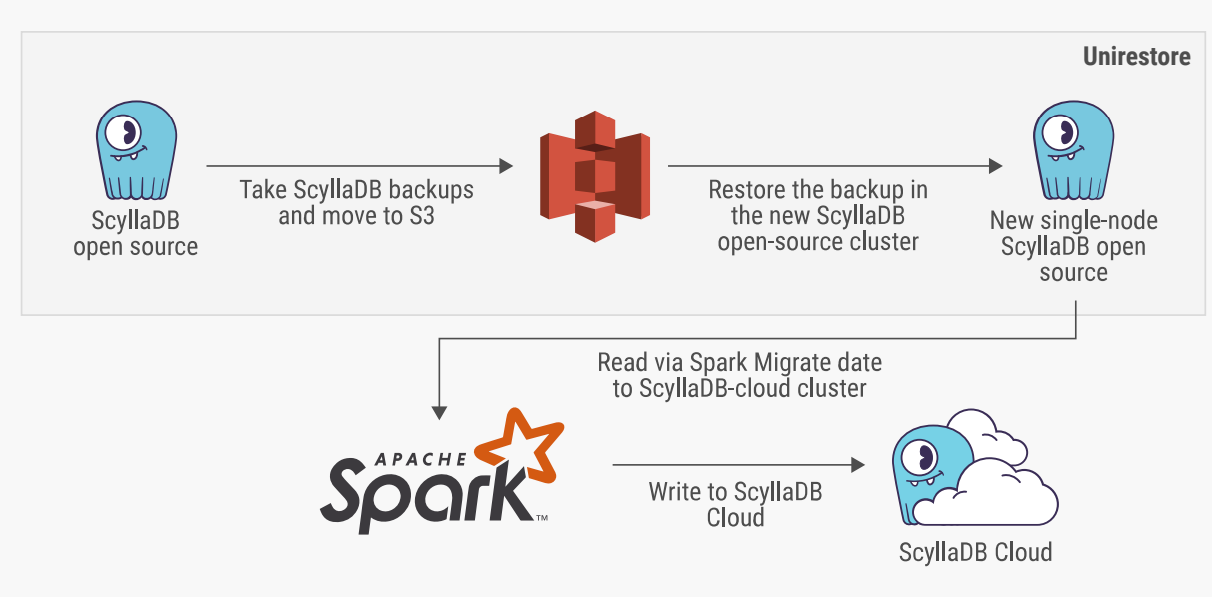
Figure 8: Migrating from ScyllaDB Open Source to ScyllaDB Cloud with the ScyllaDB Spark migrator
In this process, the data was first backed up to S3 storage, then put onto a single node ScyllaDB Open Source instance (a process known as unirestore). From there, it was pumped into ScyllaDB Cloud using the ScyllaDB Spark Migrator.
Serving the Fastest-Growing Segment of Disney+
The team is now achieving sub-millisecond p99 latencies, with average read and write latencies in the range of 150 to 200 microseconds. Moreover, with a database-as-a-service relieving them of administrative burdens like database backups, upgrades and repairs, they can focus on delivering exceptional experiences across the fastest-growing segment of Disney+ global subscribers. For example, they recently rearchitected the platform’s recommendation features to use ScyllaDB Cloud. Additional projects on the short-term horizon include migrating their watchlist functionality to ScyllaDB Cloud.


