
The past decade saw the rise of fully distributed databases. Not just local clustering to enable basic load balancing and provide high availability — with attributes such as rack awareness within a datacenter. These are truly distributed systems that could be spanned across the globe, designed to work within public clouds — across availability zones, regions, and, with orchestration technologies, even across multiple cloud providers and on-premises hybrid cloud deployments.
Likewise, this past decade has seen a plethora of new database systems designed specifically for distributed database deployments, and others that had distributed architectural components added to their original designs.
MORE “DISTRIBUTED DATABASE ESSENTIALS” RESOURCES
DB-Engines.com Top 100 Databases
For everyone who has never visited this site, I wanted to draw your attention to DB-engines.com. It’s the “Billboard Charts” of databases. It keeps a rough popularity index of all the databases you can imagine, weighted using an algorithm that tracks things like the number of mentions on websites and the Google trends of searches, to discussions on Stack Overflow or mention in Tweets, to jobs postings asking for these as technical skills, to the number of profiles that mention these technologies by name in their LinkedIn profile.
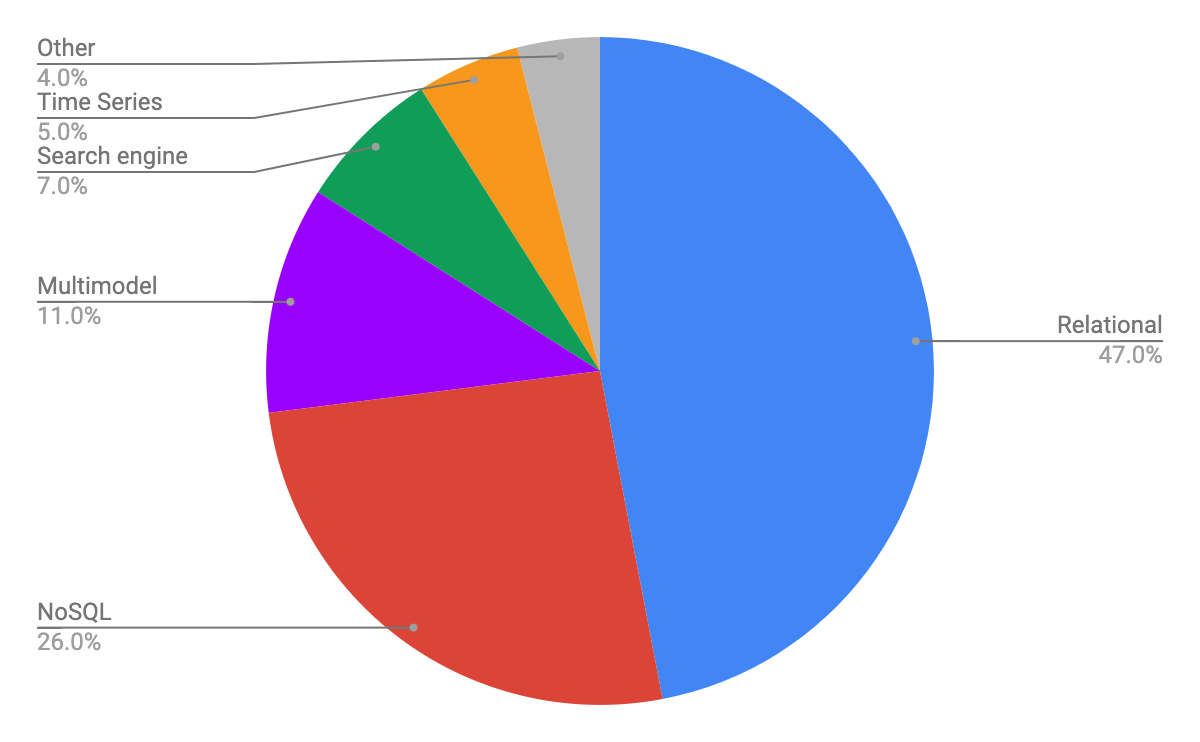
Top 100 Databases on DB-Engines.com as of May 2022
While there are hundreds of different databases that it tracks — 394 in total as of May 2022 — let’s narrow down to just looking at the top 100 listings. It reveals a great deal about the current state of the market.
Relational Database Management Systems (RDBMS), traditional SQL systems, remain the biggest category: 47% of the listings.
Another 25% are NoSQL systems spanning a number of different types: document databases like MongoDB, key-value systems like Redis, wide column databases like ScyllaDB, and graph databases like Neo4j.
There’s also a fair-sized block (11%) of databases listed as “multi-model.” These include hybrids that support both SQL and NoSQL in the same system — such as Microsoft Cosmos DB or ArangoDB — or databases that support more than one type of NoSQL data model, such as DynamoDB, which lists itself as both a NoSQL key-value system and a document store.
Lastly, there’s a few slices of the pie comprised of miscellaneous special-purpose databases from search engines to time series databases, and others those that don’t easily fall into simple “SQL vs. NoSQL” delineations.
But are all of these top databases “distributed” databases? What does that term even mean?
What Defines a Distributed Database?
SQL is formally standardized as per ANSI/ISO/IEC 9075:2016. It hasn’t changed in six years. But what has changed over that time is how people have architected distributed RDBMS systems compliant with SQL. Those continue to evolve. Distributed SQL such as PostgreSQL. Or “NewSQL” systems such as CockroachDB.
Conversely there’s no ANSI or ISO or IETF or W3C definition of what a “NoSQL database” is. Each is proprietary, or at best uses some de facto standard, such as the Cassandra Query Language (CQL) for wide column NoSQL databases, or, say, the Gremlin/Tinkerpop query methods for graph databases.
Yet these are just query protocols. They don’t define how the data gets distributed across these databases. That’s an architectural issue query languages don’t and won’t address.
So whether SQL or NoSQL (Relational vs Non-Relational), there’s no standard or protocol or consensus on what a “distributed database” is.
Thus I took some time to write up my own definition. I’ll freely admit this is more of a layman’s pragmatic view than a computer science professor’s.

In brief, you have to decide how you define a cluster, and distribute data across it.
Next, you have to determine what the roles of each of the nodes of the cluster are. Is every node a peer, or are some nodes in a more superior leader position and others are more followers.
And then, based on these roles, how do you deal with failover?
Lastly, you have to figure out based on this how you replicate and shard your data as evenly and easily as possible.
And this isn’t attempting to be exhaustive. You can add your own specific criteria.
The Short List: Distributed Database Systems of Interest
So with all this in mind, let’s go into our Top 100 and find five examples to see how they compare when measured against those attributes. I’ve chosen two SQL systems and three NoSQL systems.
| SQL + NewSQL | NoSQL |
| PostgreSQL | MongoDB |
| CockroachDB | Redis |
| ScyllaDB (Cassandra) |
Postgres and CockroachDB represent the best of distributed SQL. CockroachDB is referred to as “NewSQL” — designed specifically for this world of distributed databases. (If you are specifically interested in CockroachDB, check out this article where we go into a deeper comparison.)
MongoDB, Redis and ScyllaDB are my choices for distributed NoSQL. The first as an example of a document database. The second as a key-value store, and ScyllaDB as a wide-column database — also called a “key-key-value” database.
Also note that, for the most part, what is true for ScyllaDB is, in many cases, also true of Apache Cassandra and other Cassandra-compatible systems.
I apologize to all those whose favorite systems weren’t selected. But I hope if you have another system in mind you compare what we say for these systems to others you have in mind.
For now, I will presume you already have professional experience, and you’re somewhat familiar with the differences of SQL vs. NoSQL. If not, check out our primer on SQL vs NoSQL. Basically, if you need a table JOIN, stick with SQL and an RDBMS. If you can denormalize your data, then maybe NoSQL might be a good fit. We’re not going to argue whether one or the other is “better” as a data structure or query language. We are here to see if any of these are better as a distributed database.
Multi-Datacenter Clustering
Let’s see how our options compare in terms of clustering. Now, all of them are capable of clustering and even multi-datacenter operations. But in the cases of PostgreSQL, MongoDB, and Redis — these designs predate multi-datacenter design as an architectural requirement. They were designed in the world of single datacenter local clustering to begin with.

Postgres, first released in 1986, totally predates the concepts of cloud computing. But over time it evolved to allow for these advances and capabilities to be bolted on to its design.
CockroachDB, part of the NewSQL revolution, was designed from the ground up with global distribution in mind.
MongoDB, released at the dawn of the public cloud, was initially designed with a single datacenter cluster in mind, but now has added support for quite a lot of different topologies. And with MongoDB Atlas, you can deploy to multiple regions pretty easily.
Redis, because of its low-latency design assumptions, is generally deployed on a single datacenter. But it has enterprise features that allow for multi-datacenter deployments.
ScyllaDB, like Cassandra, was designed with multi-datacenter deployments in mind from the get-go.
Clustering: Primary-Replica vs Active-Active
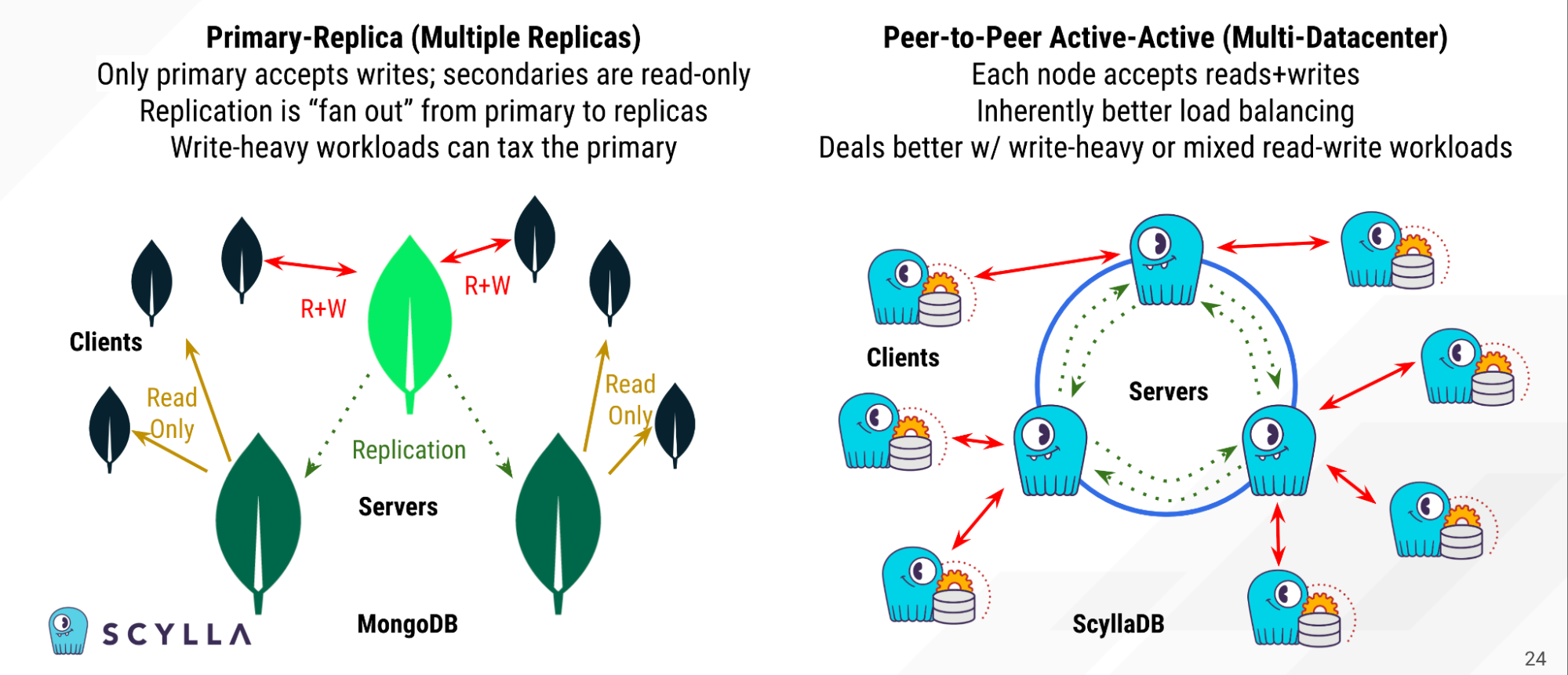
How you do replication and sharding is also dependent upon how hierarchical or homogeneous your database architecture is.
For example, in MongoDB there is a single primary server; the rest are replicas of that primary. This is referred to as a replica set. You can only make writes to this primary copy of the database. The replicas are read-only. You can’t update them directly. Instead, you write to the primary, and it updates the replicas. So nodes are heterogenous; not homogenous.
This helps distribute traffic in a read-heavy workload, but in a mixed or write-heavy workload it’s not doing you much good at all. The primary can become a bottleneck.
As well, what happens if the primary goes down? You’ll have to hold up writes entirely until the cluster elects a new primary, and write operations are shunted over to it. It’s a concerning single point of failure.
Instead, if you look at ScyllaDB, or Cassandra, or any other leaderless, peer-to-peer system — these are known as “active-active,” because clients can read from or write to any node. There’s no single point of failure. Nodes are far more homogenous.
And each node can and will update any other replicas of the data in the cluster. So if you have a replication factor of 3, and three nodes, each node will get updated based on any writes to the other two nodes.
Active-active is inherently more difficult to do computationally, but once you solve for how the servers keep each other in sync, you end up with a system that can load balance mixed or write-heavy workloads far better, because each node can serve reads or writes.
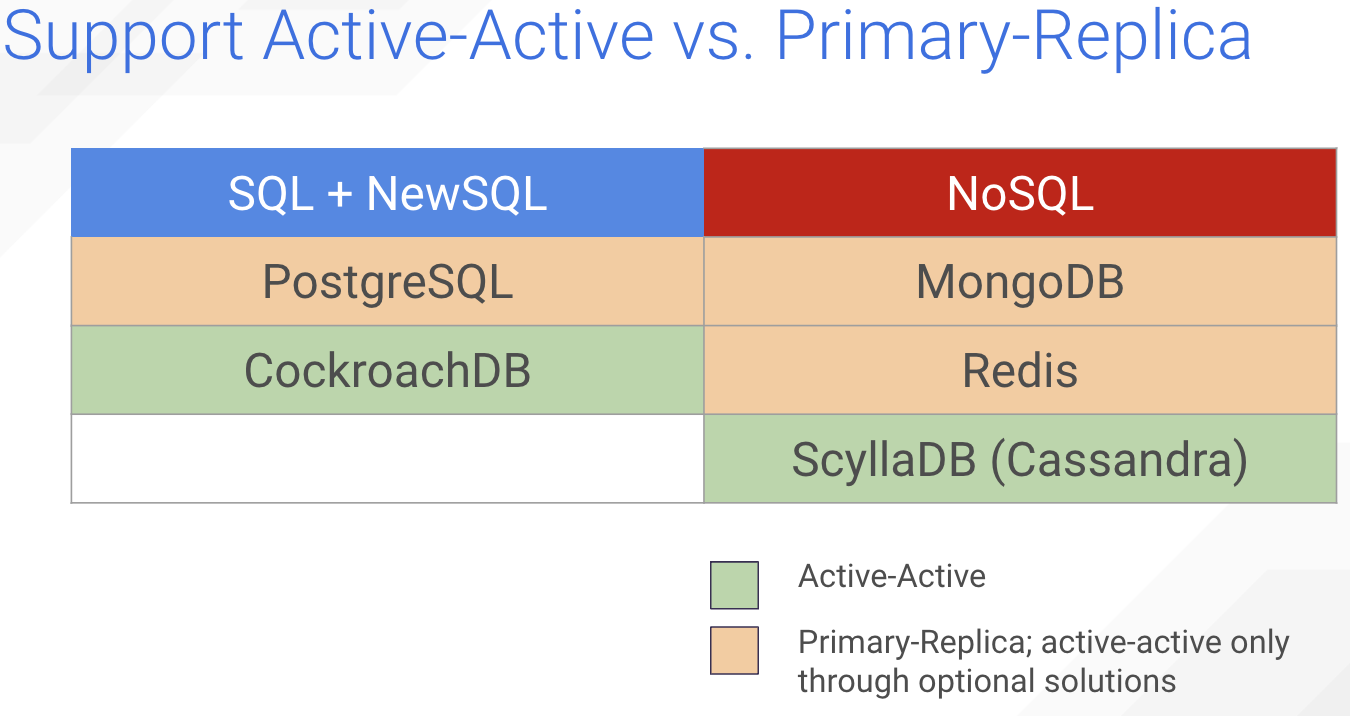
So how do our various examples stack up in regards to primary-replica or active-active peer-to-peer?
CockroachDB and ScyllaDB (and Cassandra) began with a peer-to-peer active-active design in mind.
Whereas in Postgres there’s a few optional ways you can do it, but it’s not built in.
Also, active-active is not officially supported in MongoDB, but there have been some stabs at how to do it.
And with Redis, an active-active model is possible with Conflict-free replicated data types — CRDTs — in Redis Enterprise.
Otherwise Postgres, MongoDB and Redis all default to a primary-replica data distribution model.
Replication: Primary-Replica vs Active-Active
Distributed systems designs also affect how you might distribute data across the different racks or datacenters you’ve deployed to. For example, given a primary-replica system, only the datacenter with the primary can serve any write workloads. Other datacenters can only serve as a read-only copy.
In a peer-to-peer system that supports multi-datacenter clustering, each node in the overall cluster can accept reads or writes. This allows for better geographic workload distribution.
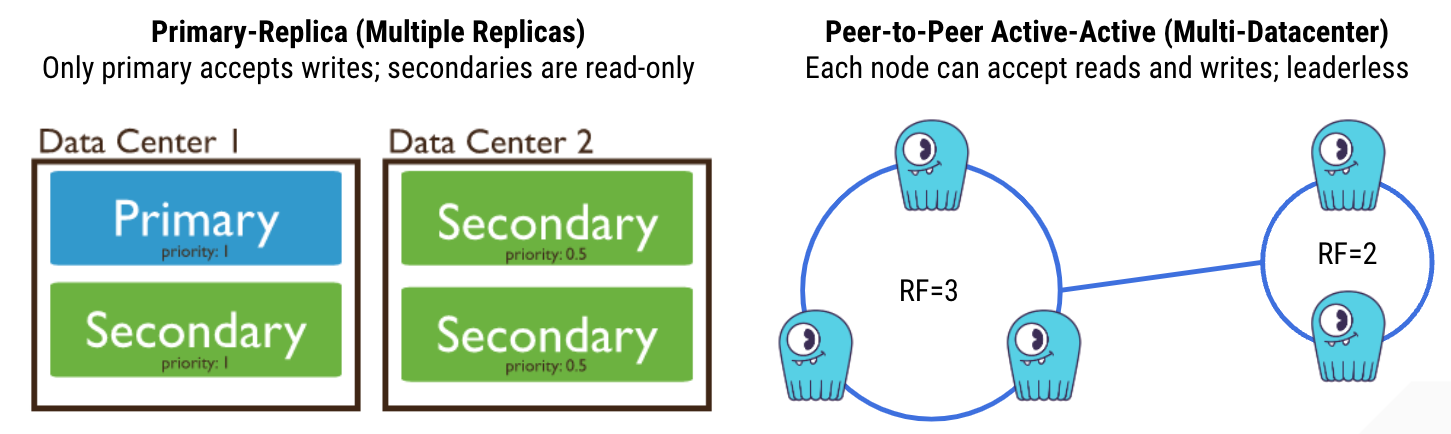
With ScyllaDB you can decide, for example, to have the same or even different replication factors per site. Here I’ve shown the possibility of having three replicas of data at one datacenter and two replicas at another.
Operations then can have different levels of consistency. You might have a local quorum read or write at the three node datacenter — requiring two of three nodes to be updated for local quorum. Or you might have a cluster-wide quorum, requiring any three nodes across either or both datacenters to be updated for an operation to be successful. Tunable consistency, combined with multi-datacenter topology awareness, basically gives you a lot more flexibility to customize workloads.
Topology Awareness
Local clustering was the way distributed databases began, allowing more than one system to share the load. This was important if you wanted to allow for sharding your database across multiple nodes, or replicating data if you wanted to have high availability by ensuring the same data was available on multiple nodes.
But if all your nodes were installed in the same rack, and if that rack went down, that’s no good. So topology awareness was added so that you could be rack aware within the same datacenter. This ensures you spread your data across multiple racks of that datacenter, thus minimizing outages if power or connectivity is lost to one rack or another. That’s the barest-bones form of topology awareness you’d want.
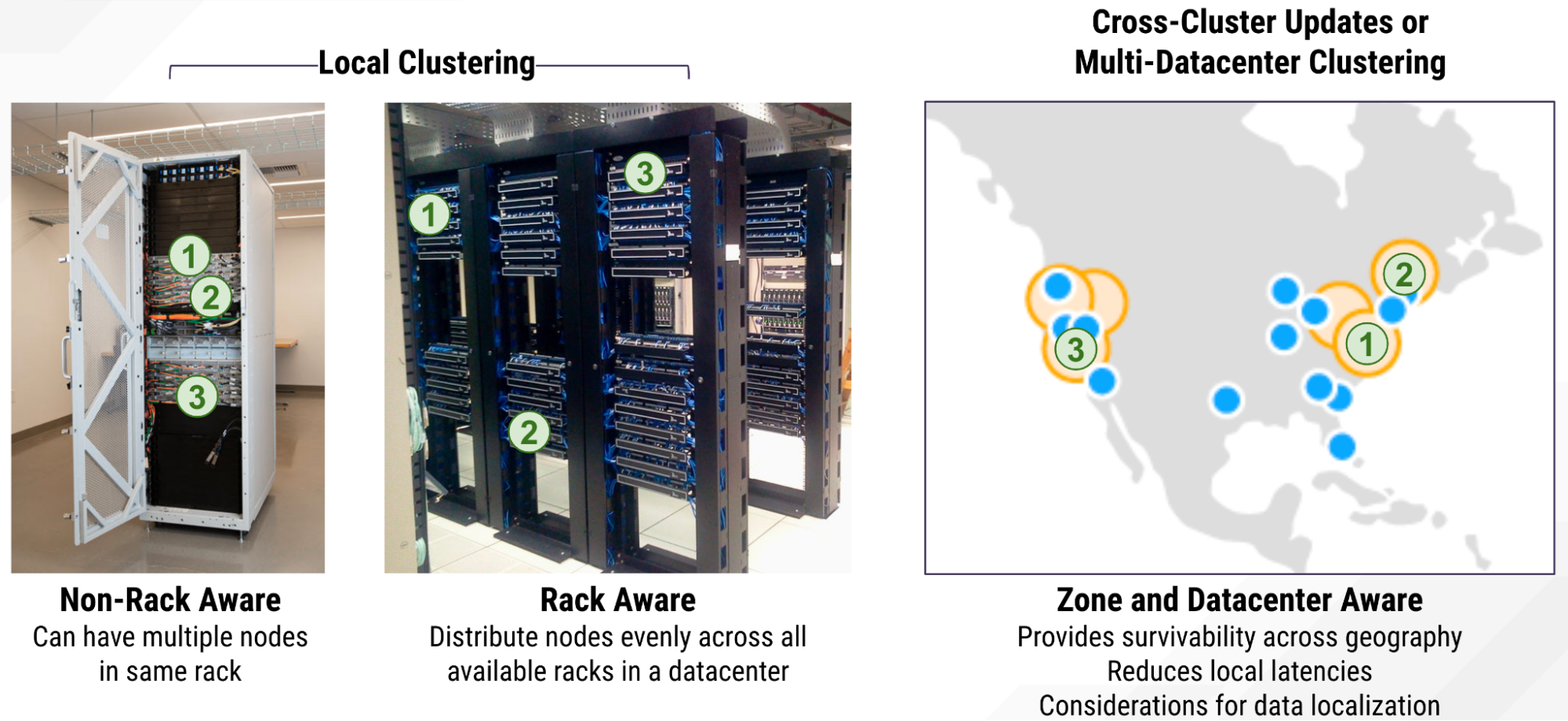
Some databases do better than this, and allow for multiple copies of the database to be running in different datacenters, with some sort of cross-cluster updating mechanism. Each of these databases is running autonomously. Their synchronization mechanism could be unidirectional — one datacenter updating a downstream replica — or it could bidirectional or multi-directional.
This geographic distribution can minimize latencies by allowing connections closer to users. Spanning a database across availability zones or regions also ensures that no single datacenter disaster means you’ve lost part or all of your database. That actually happened to one of our customers last year, but because they were deployed across three different datacenters, they lost zero data.
Cross-cluster updates were at first implemented in a sort of gross, batch level. Ensuring your datacenters got in sync at least once a day. Ugh. That didn’t cut it for long. So people started ensuring more active, transaction-level updates.
The problem there was, if you were running strongly consistent databases, you were limited based on the real-time propagation delay of the speed of light. So eventual consistency was implemented to allow for multi-datacenter, per operation updates, with the understanding and tradeoff that in the short term it might take time before your data was consistent across all your datacenters.
So how do our exemplars stack up in terms of topology awareness?
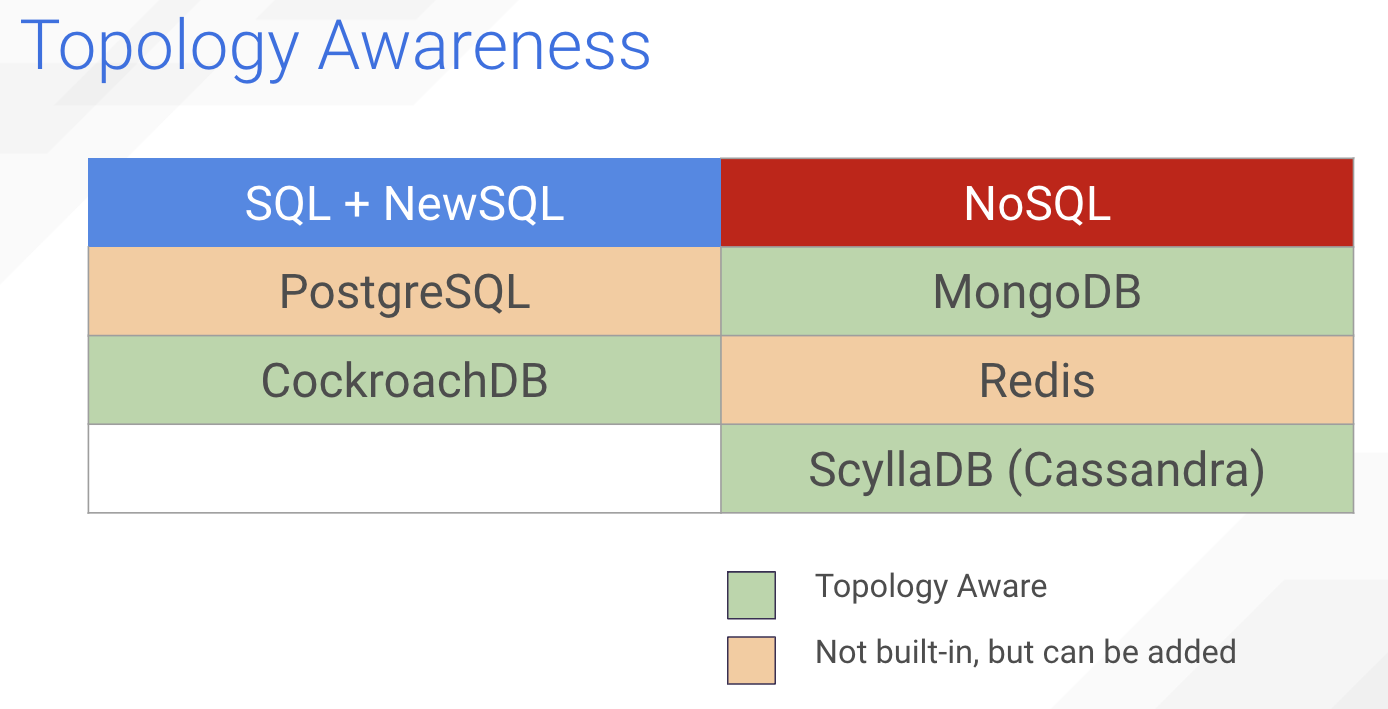
So, again, with CockroachDB and ScyllaDB this comes built in.
Topology awareness was also made part of MongoDB starting circa 2015. So, not since its launch in 2009, but certainly they have years of experience with it.
Postgres and Redis were originally designed to be single datacenter solutions, thus dealing with multi-datacenter latencies are sort of an anti-pattern for both. Now, you can add-on topology awareness, like you can add on active-active system features, but it doesn’t come out of the box.
So let’s review what we’ve gone over by looking at these databases individually versus these attributes.
PostgreSQL
“Postgres” is one of the most popular implementations of SQL these days. It offers local clustering out of the box.
However, Postgres, as far as I know, is still working on its cross-cluster and multi-datacenter clustering. You may have to put some effort into getting it working.
Because SQL is grounded in a strongly consistent transactional mindset, it doesn’t lend itself well to spanning a cluster across a wide geography. Each query would be held up by long latency delays between all the relevant datacenters.

Also, Postgres relies upon a primary-replica model. One node in the cluster is the leader, and the others are replicas. And while there are load balancers for it, or active-active add-ons those are also beyond the base offering.
Finally, sharding in Postgres still remains manual for the most part, though they are making advances in developing auto-sharding which are, again, beyond the base offering.
CockroachDB
CockroachDB bills itself as “NewSQL” — a SQL database designed in mind for distribution. This is a SQL designed to be survivable. Hence the name.
Note that CockroachDB uses the Postgres wire protocol, and borrows heavily from many concepts pioneered in Postgres. However, it doesn’t limit itself to the Postgres architecture.
Multi-datacenter clustering and peer-to-peer leaderless topology is built-in from the get-go.
So is auto-sharding and data replication.
And it has datacenter-awareness built in, and you can add rack-awareness too.

The only caveat to CockroachDB — and you may see it as a strength or a weakness — is that it requires strong consistency on all its transactions. You don’t have the flexibility of eventual consistency nor tunable consistency. Which will lower throughput and require high baseline latencies in any cross-datacenter deployment.
MongoDB
MongoDB is the venerable leader of the NoSQL pack. So over time as it developed a lot of distributed database capabilities were added. It’s come a long way from its origins. Now MongoDB is capable of multi-datacenter clustering. It still follows a primary-replica model for the most part, but there are ways to make it peer-to-peer active-active.

Redis
Next up is Redis, a key-value store designed to act as an in-memory cache or datastore. While it can persist data, it suffers from a huge performance penalty if the dataset doesn’t fit into RAM.
Because of that, it was designed with local clustering in mind. Because if you can’t afford to wait five milliseconds to get data off an SSD, you probably can’t wait 145 milliseconds to make the network round trip time from San Francisco to London.
However, there are enterprise features that do allow multi-datacenter Redis clusters for those who do need geographic distribution.

Redis operates for the most part as a primary-replica model. Which is appropriate for a read-heavy caching server. But what it means is that the primary is where the data needs to get written to first, which will then fan out to the replicas to help balance their caching load.
There is an enterprise feature to allow peer-to-peer active-active clusters.
Redis does auto-shard and replicate data, but its topology awareness is limited to rack-awareness as an enterprise feature.
ScyllaDB
Finally we get to ScyllaDB. It was patterned after the distributed database model found in Apache Cassandra. And so it comes, by default, with multi-datacenter clustering. A leaderless active-active topology.
It automatically shards and has tunable consistency per operation, and, if you want stronger consistency, even supports lightweight transactions to provide linearizability of writes.

As far as topology awareness, ScyllaDB of course supports rack-awareness and datacenter-awareness. It even supports token-awareness and shard-awareness to know not only which node data will be stored in, but even down to which CPU is associated with that data.
All the goodness you need from a distributed database.
Distributed Database Comparison: Where to Go From Here?
While there is no industry standard for what a distributed database is, we can see that many of the leading SQL and NoSQL databases support a core set of features or attributes to some degree or other. Some of these features are built in, and some are considered value-added packages or third-party options.
Of the five exemplar distributed database systems analyzed herein, CockroachDB offers the most comprehensive combination of features and attributes out-of-the-box for SQL databases and ScyllaDB offers the most comprehensive combination for NoSQL systems.
This analysis should be considered a point-in-time survey. Each of these systems is constantly evolving given the relentless demands of this next tech cycle. Database-as-a-Service offerings. Serverless options. Elasticity. The industry is not standing still.
The great news for users is that with each year more advances are being made to distributed databases to make them ever more flexible, more performant, more resilient, and more scalable.
If you’d like to stay on top of the advances being made in ScyllaDB, we encourage you to join our user community in Slack.






