TRACTIAN’s comparison of ScyllaDB vs MongoDB and PostgreSQL, plus their migration challenges & results.
This article was written independently by João Pedro Voltani, Head of Engineering at TRACTIAN, and originally published on the TRACTIAN blog. It was co-authored by João Granzotti, Partner & Head of Data at TRACTIAN. Update 10/1/2025: Also see Why TRACTIAN Migrated from MongoDB to ScyllaDB for Real-Time ML.
In the beginning of 2022, TRACTIAN faced the challenge of upgrading our real-time machine learning environment and analytical dashboards to support an aggressive increase in our data throughput, as we managed to grow our customers database and data volume by 10x during 2021.
We recognized that in order to stay ahead in the fast-paced world of real-time machine learning (ML), we needed a data infrastructure that was flexible, scalable, and highly performant. We believed that ScyllaDB would provide us with the capabilities we lacked to support our real-time ML environment, enabling us to push our product and algorithms to the next level.
But probably you are wondering— why was ScyllaDB our best fit? We’d like to take you on the journey of transforming our engineering process to focus on improving our product’s performance. We’ll cover why we ultimately decided to use ScyllaDB, the positive outcomes we’ve seen as a result, and the obstacles we encountered during the transition.
Editor’s note: JP recently shared a video presenting more details about their scaling needs, database evaluation, and migration. You can watch it here.

How We Compared NoSQL Databases: MongoDB vs ScyllaDB vs PostgreSQL
When talking about databases, many options come to mind. However, we started by deciding to focus on those with the largest communities and applications. This left three direct options: two market giants and a newcomer that has been surprising the competitors. We looked at four characteristics of those databases — data model, query language, sharding, and replication — and used these characteristics as decision criteria for our next steps.
First off, let’s give you a deeper understanding of the three databases using the defined criteria:
MongoDB NoSQL
- Data Model: MongoDB uses a document-oriented data model where data is stored in BSON (Binary JSON) format. Documents within a collection can have different fields and structures, providing a high degree of flexibility. The document-oriented model enables basically any data modeling or relationship modeling.
- Query Language: MongoDB uses a custom query language called MongoDB Query Language (MQL), which is inspired by SQL but with some differences to match the document-oriented data model. MQL supports a variety of query operations, including filtering, grouping, and aggregation.
- Sharding: MongoDB supports sharding, which is the process of dividing a large database into smaller parts and distributing the parts across multiple servers. Sharding is performed at the collection level, allowing for fine-grained control over data placement. MongoDB uses a config server to store metadata about the cluster, including information about the shard key and shard distribution.
- Replication: MongoDB provides automatic replication, allowing for data to be automatically synchronized between multiple servers for high availability and disaster recovery. Replication is performed using a replica set, where one server is designated as the primary and the others as secondary members. Secondary members can take over as the primary in case of a failure, providing automatic fail recovery.
ScyllaDB NoSQL
- Data Model: ScyllaDB uses a wide column-family data model, which is similar to Apache Cassandra. Data is organized into columns and rows, with each column having its own value. This model is designed to handle large amounts of data with high write and read performance.
- Query Language: ScyllaDB uses the Cassandra Query Language (CQL), which is similar to SQL but with some differences to match the wide column-family data model. CQL supports a variety of query operations, including filtering, grouping, and aggregation.
- Sharding: ScyllaDB uses sharding, which is the process of dividing a large database into smaller parts and distributing the parts across multiple nodes [and down to individual cores]. The sharding is performed automatically, allowing for seamless scaling as the data grows. ScyllaDB uses a consistent hashing algorithm to distribute data across the nodes [and cores], ensuring an even distribution of data and load balancing.
- Replication: ScyllaDB provides automatic replication, allowing for data to be automatically synchronized between multiple nodes for high availability and disaster recovery. Replication is performed using a replicated database cluster, where each node has a copy of the data. The replication factor can be configured, allowing for control over the number of copies of the data stored in the cluster.
PostgreSQL
- Data Model: PostgreSQL uses a relational data model, which organizes data into tables with rows and columns. The relational model provides strong support for data consistency and integrity through constraints and transactions.
- Query Language: PostgreSQL uses the Structured Query Language (SQL), which is the standard language for interacting with relational databases. SQL supports a wide range of query operations, including filtering, grouping, and aggregation.
- Sharding: PostgreSQL does not natively support sharding, but it can be achieved through extensions and third-party tools. Sharding in PostgreSQL can be performed at the database, table, or even row level, allowing for fine-grained control over data placement.
- Replication: PostgreSQL provides synchronous and asynchronous replication, allowing data to be synchronized between multiple servers for high availability and disaster recovery. Replication can be performed using a variety of methods, including streaming replication, logical replication, and file-based replication.
What were our conclusions of the benchmark?
In terms of performance, ScyllaDB is optimized for high performance and low latency, using a shared-nothing architecture and multi-threading to provide high throughput and low latencies.
MongoDB is optimized for ease of use and flexibility, offering a more accessible and developer-friendly experience and has a huge community to help with future issues.
PostgreSQL, on the other hand, is optimized for data integrity and consistency, with a strong emphasis on transactional consistency and ACID (Atomicity, Consistency, Isolation, Durability) compliance. It is a popular choice for applications that require strong data reliability and security. It also supports various data types and advanced features such as stored procedures, triggers, and views.
When choosing between PostgreSQL, MongoDB and ScyllaDB, it is essential to consider your specific use case and requirements. If you need a powerful and reliable relational database with advanced data management features, then PostgreSQL may be the better choice. However, if you need a flexible and easy-to-use NoSQL database with a large ecosystem, then MongoDB may be the better choice.
But we were looking for something really specific: a highly scalable, and high-performance NoSQL database. The answer was simple: ScyllaDB is a better fit for our use case.
MongoDB vs ScyllaDB vs PostgreSQL Performance Compared
After the research process, our team was skeptical about making a choice that would shape the future of our product using just written information. We started digging to be sure about our decision in practical terms.
First, we built an environment to replicate our data acquisition pipeline, but we did it aggressively. We created a script to simulate a data flow bigger than the current one. At the time, our throughput was around 16,000 operations per second, and we tested the database with 160,000 operations per second (so basically 10x).
To be sure, we also tested the write and read response times for different formats and data structures; some were similar to the ones we were already using at the time.
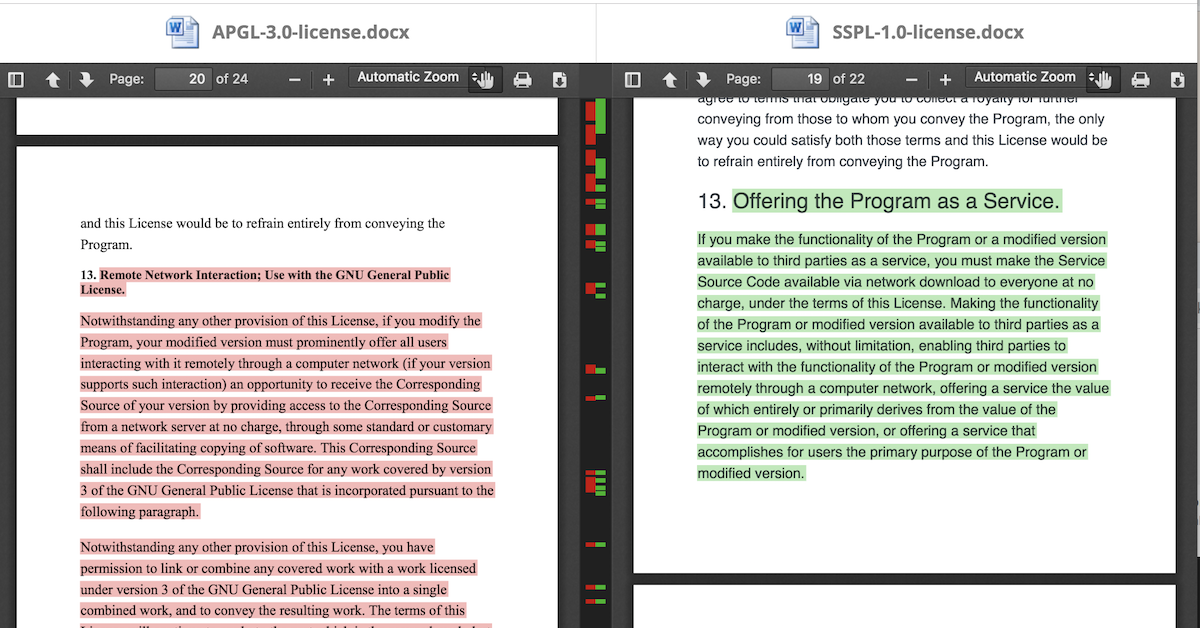
You can see below our results with the new optimal configuration using ScyllaDB and the configuration using that we had with MongoDB (our old setup) applying the tests mentioned above:
MongoDB vs ScyllaDB P90 Latency (Lower is Better)
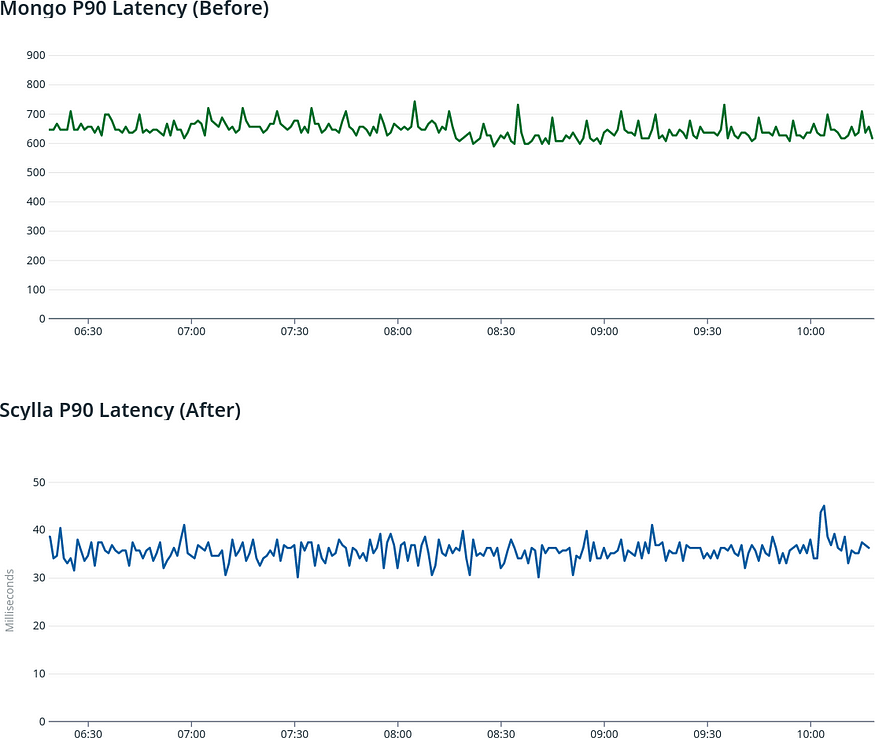
MongoDB vs ScyllaDB Request Rate / Throughput (Higher is Better)
The results were overwhelming! With similar infrastructure costs, we achieved much better latency and capacity; the decision was clear and validated! We had ahead of ourselves a massive database migration.
Migrating from MongoDB to ScyllaDB NoSQL
As soon as we decided to start the implementation, we faced real-world difficulties. Some things are important to mention.
In this migration, we added new information and formats, affecting all production services that consume this data directly or indirectly. They would have to be refactored by adding adapters in the pipeline or recreating part of the processing and manipulation logic.
During the migration journey, both services and databases had to be duplicated, since it is not possible to use an outage event to swap between old and new versions to validate our pipeline. It’s part of the issues that you have to deal with in critical real-time systems: an outage is never permitted, even if you are fixing or updating the system.
The reconstruction process should go through the Data Science models, so that they could take advantage of the new format, increasing accuracy and computational performance.
Given these guidelines, we created two groups. One was responsible for administering and maintaining the old database and architecture. The other group performed a massive re-processing of our data lake and refactored the models and services to handle the new architecture.
The complete process, from the designing the structure to the final deployment and swap of the production environment, took six months. During this period, adjustments and significant corrections were necessary. You never know what lessons you’ll learn along the way.
NoSQL Migration Challenges
ScyllaDB can achieve this kind of performance because it is designed to take advantage of high-end hardware and very specific data modeling. The final results were astonishing, but we took some time to achieve them. Hardware has a significant impact on performance. ScyllaDB is optimized for modern multi-core processors and utilizes all available CPU cores to process data. It uses hardware acceleration technologies such as AVX2 and AES-NI; it also depends on the type and speed of storage devices, including SSDs and NVMe drives.
In our early testing, we messed up some hardware configurations, leading to performance degradation. When those problems were fixed, we stumbled upon another problem: the data modeling.
ScyllaDB uses the Cassandra data model, which heavily dictates the performance of your queries. If you make incorrect assumptions about the data structures, queries, or the data volume ( as we did at the beginning), the performance will suffer.
In practice, the first proposed data format ended up exceeding the maximum size recommended for a ScyllaDB partition in some cases, which made the database perform poorly.
Our main difficulty was understanding how to translate our old data modeling to a ScyllaDB performing one. We had to re-structure the data into multiple tables and partitions, sometimes duplicating data to achieve better performance.
Our Lessons Learned Comparing and Migrating NoSQL Databases
In short, we learned three lessons during this process: some came from our successes and others from our mistakes.
In the process of researching and benchmarking the databases, it became clear that many of the specifications and functionalities present in the different databases have specific applications. Your specific use case will dictate the best database for your application. And that truth is only discovered by carrying out practical tests and simulations of the production environment in stressful situations. We invested a lot of time and our choice to use the most appropriate database has paid off.
When starting a large project, it is crucial to be prepared for a change of route in the middle of the journey. If you developed a project that did not change after its conception, you probably didn’t learn anything during the construction process or you didn’t care about the unexpected twists. Planning cannot completely predict all real-world problems, so be ready to adjust your decisions and beliefs along the way.
You shouldn’t be afraid of big changes. Many people were against the changes we were proposing due to the risk it brought and the inconvenience it caused to developers (by changing a tool already owned by the team to a new tool that was completely unknown to the team).
Ultimately, the decision was driven based on its impact on our product improvements and not on our engineering team, even though it was one of the most significant engineering changes we have had to date.
It doesn’t matter what architecture or system you are using. The real concern is whether it will be able to take your product into a bright future or not.
This is, in a nutshell, our journey in building one the bridges the future of TRACTIAN’s product. If you have any questions or comments, feel free to contact us.