




This article includes content from our webinar “Demystifying the Distributed Database Landscape.” You can register now to watch the webinar in full.
We’re in the middle of what we at ScyllaDB have dubbed “This Next Tech Cycle.” Not “the world of tomorrow” nor “the shape of things to come” nor “the wave of the future.” It’s already here today. We’re in the thick of it. And it’s a wave that’s carrying us forward from trends that got their start earlier this century.
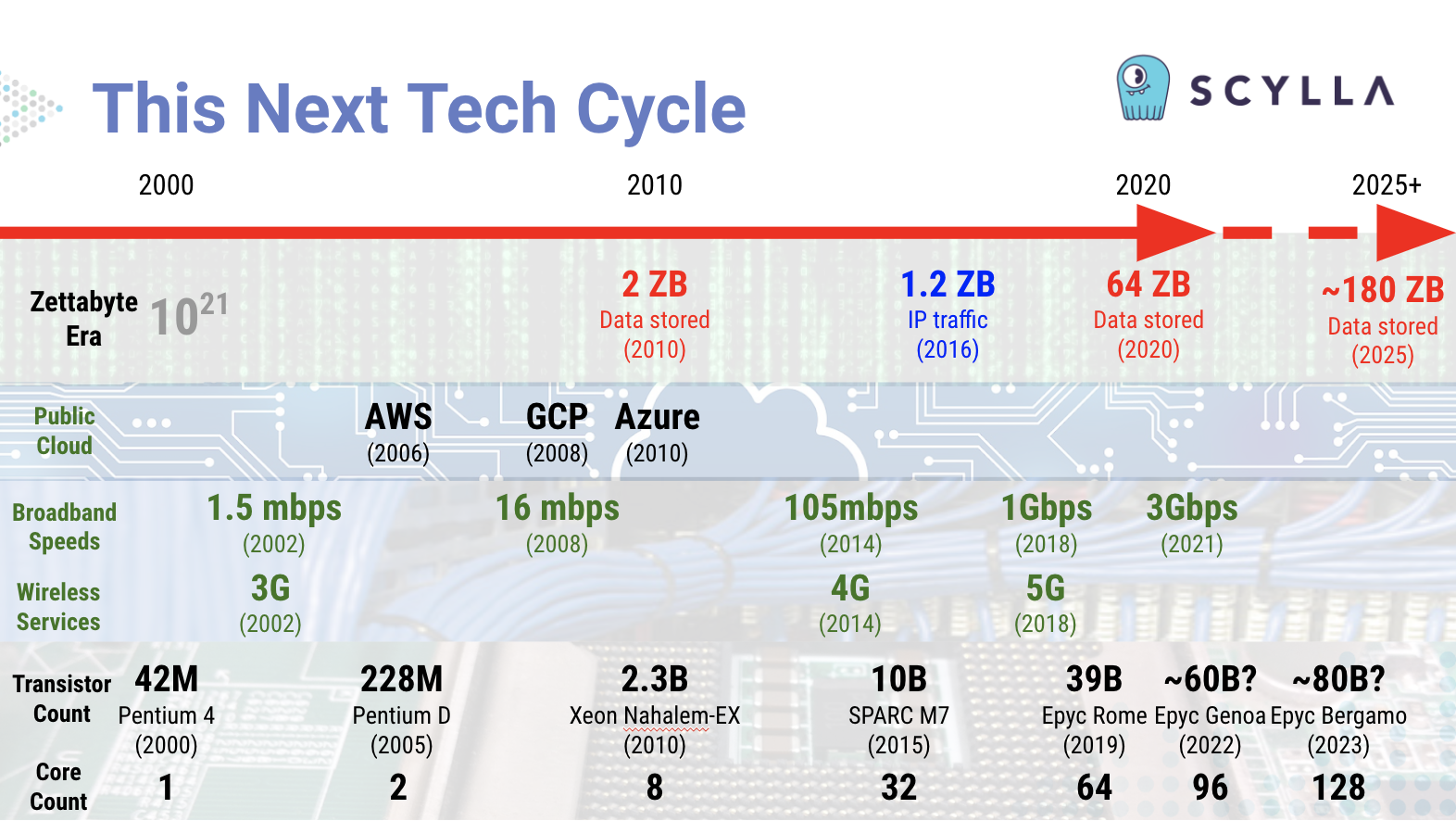 Trends in technology shaping this next tech cycle: total data volumes at zettabyte-scale, the proliferation of public cloud services, gigabit per second broadband and wireless services, and CPU transistor and core counts continuing to grow.
Trends in technology shaping this next tech cycle: total data volumes at zettabyte-scale, the proliferation of public cloud services, gigabit per second broadband and wireless services, and CPU transistor and core counts continuing to grow.
Everything is co-evolving, from the hardware you run on, to the languages and operating systems you work with, to the operating methodologies you use day-to-day. All of those familiar technologies and business models are themselves undergoing revolutionary change.
This next tech cycle goes far beyond “Big Data.” We’re talking huge data. Welcome to the “Zettabyte Era.” This era, depending on who is defining it, either started in 2010 for total data stored on Earth, or in 2016 for total Internet protocol traffic in a year.
Right now individual data intensive corporations are generating information at the rate of petabytes per day, and storing exabytes in total. There are some prognosticators who believe we’ll see humanity, our computing systems, and our IoT-enabled machinery generating a half a zettabyte of data per day by 2025.
Yet conversely, we’re also seeing the importance of small data. Look at the genomics revolution.
Because the RNA gene sequence of, say, COVID-19 is actually not at all big data-wise — you can store it in less than 100kb — less than an ancient floppy. But it is increasingly important to understand every single byte of that information, because vaccinating against this global pandemic requires understanding every change of that rapidly-evolving pathogen.
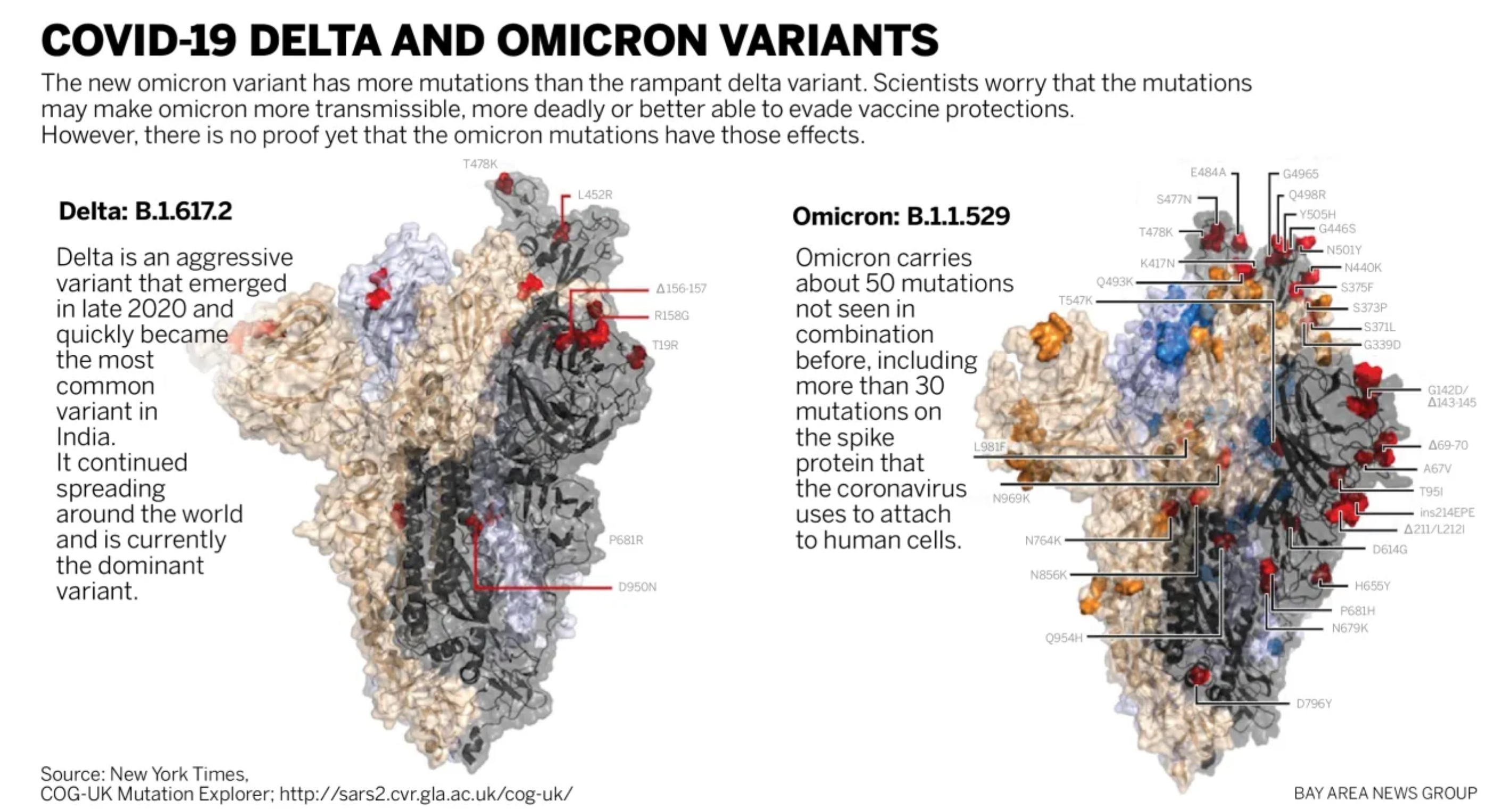
Spike proteins of the Delta and Omicron COVID-19 variants, showing the new mutations in the viral pathogen. However, just knowing that there are differences does not mean scientists yet understand the pragmatics of what each difference does or means for human health. Source: New York Times / Bay Area News Group
So this next tech cycle has to scale everything between huge data and small data systems. And the database you will use, and the data analytics you perform, needs to align with the volume, variety and velocity of the data you have under management.
“Great! Now Make it All Multi-Cloud!”
Also, this next tech cycle is not just the “cloud computing cycle.” AWS launched in 2006. Google Cloud launched in 2008. And Azure formally launched in 2010. So we’re already well over a decade past the dawn of the public cloud. Yet this next tech cycle definitely builds on the ecosystems, methodologies and technologies these hyperscalers provide.
So the database you use also has to align with where you need to deploy it. Does it only work in the cloud, or can it be deployed on premises far behind your firewall? Does it just work with one cloud vendor, or is it deployable to any of them? Or all of them simultaneously? These are important questions.
Just as we do not want to be locked into old ways of thinking and doing, the industry does not want to be locked into any one technology provider.
So if you’ve just been mastering the art of running stateful distributed databases on a single cloud using Kubernetes, now you’re being asked to do it all over again, now only in a hybrid or multi-cloud environment using Anthos, OpenShift, Tanzu, EKS Anywhere or Azure Arc.
 |
 |
Computing Beyond Moore’s Law
Underpinning all of this are the raw capabilities of silicon, summed up by the transistor and core counts of current generation CPUs. We’ve already reached 64-core CPUs. The next generations will double that, to a point where a single CPU will have more than 100 processors. Fill a rack based high performance computer with those and you can easily get into thousands of cores per server.
And all of this is just traditional CPU-based computing. You also have GPU advancements that are powering the world of distributed ledger technologies like blockchain. Plus all of this is happening concurrently as IBM plans to deliver a 1,000 qubit quantum computer in 2023, and Google plans to deliver a computer with 1 million qubits by 2029.
This next tech cycle is powered by all of these fundamentally revolutionary capabilities. It’s what’s enabling real-time full streaming data from anyone to anywhere. And this is just the infrastructure.
If you dive deeper into that infrastructure, you know that each of the hardware architecture bottleneck points is undergoing its own revolution.
We’ve already seen CPU densities growing. Yet vanilla standalone CPUs themselves are also giving way to full Systems on a Chip (or SoCs).
And while they’ve been used in high performance computing in the past, expect to see commonly-available server systems with greater than 1,000 CPUs. These will be the workhorses — or more rightly the warhorses — of this next generation: Huge beasts capable of carrying mighty workloads.
Memory, another classic bottleneck, is getting a huge boost from DDR5 today and DDR6 in just a few years. Densities are going up so you can expect to see warhorse systems with a full terabyte of RAM. These and larger scales are going to be increasingly common — and for businesses, increasingly affordable.
Storage is also seeing its own revolution with the recently-approved NVMe base and transport specifications, which will enable much easier implementation of NVMe over fabrics.
It’s also not the basic broadband or wireless Internet revolutions. We’re fully two decades into both of those. Yet the advent of gigabit broadband and the new diverse range of 5G services — also capable of scaling to a gigabit — enable incredible new opportunities in real time data streaming services, IoT and more. And in the datacenter? You’re talking about the steady march towards true terabit ethernet — earlier this year, the IEEE passed an amendment to support rates of up to 400 Gbps.
So how does your database work when you need to connect to systems far and near? How important are the limitations of the speed of light to your latencies? How well do you deal with data ingested from hundreds of millions of endpoints at multiple gigabits per second scales?
Now, software will have to play catch up to these capabilities. Just as it took time for kernels and then applications inside of a vertically scaled box to be made async everywhere, shared-nothing, sharded-per-core, and NUMA-aware, this next tech cycle is going to require systems to adapt to whole new methodologies of getting the most from these new hardware capabilities. We will need to reconsider many foundational software assumptions.
Evolving Methodologies: Agile and Onwards
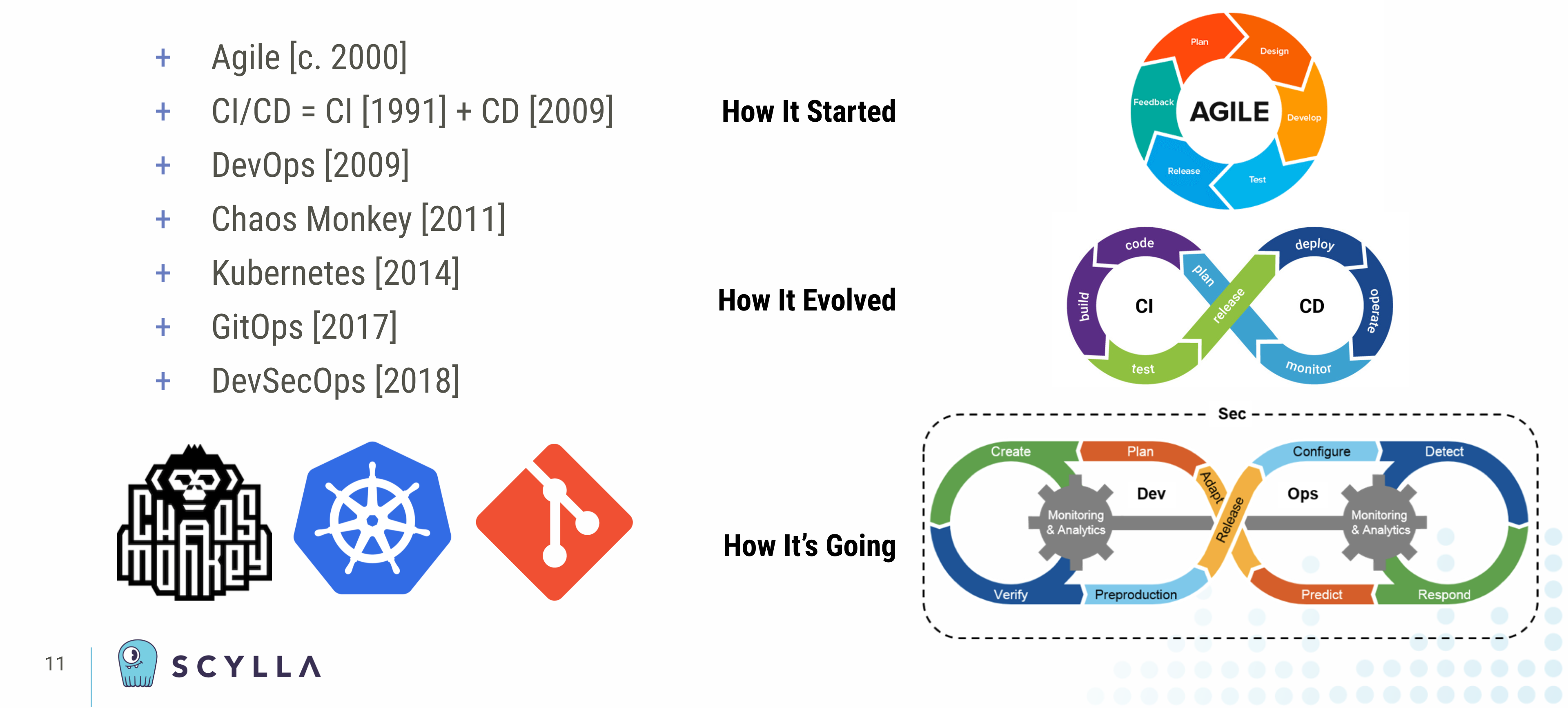
Speaking of methodologies, just look at these from the dawn of the millennium and onwards. As an industry we’ve moved from batch operations and monolithic upgrades performed with multi-hour windows of downtime on the weekend to a world of streaming data and continuous software delivery performed 24 × 7 × 365 with zero downtime ever.
And by adopting to the cloud and this always-on world we’ve exposed ourselves and our organizations to a world of random chaos and security threats. We now have to operate fleets of servers autonomously and orchestrate them across on-premises, edge and multiple public cloud vendor environments.
While Scrum has been around since the 1980s, and Continuous Integration since 1991, in this century the twelve principles of the Agile Manifesto in 2001 altered the very philosophy — never mind the methodologies — underlying the way software is developed.
The Agile Manifesto’s very first line talks about the highest priority being “to satisfy the customer through early and continuous delivery of valuable software.”
However the specific term Continuous Delivery (CD), as we know it today, didn’t take hold until 2009. It was then joined at the hip to Continuous Integration and coincided with the birth of what we now know as DevOps.
With that, you had a framework for defining change-oriented processes and software life cycles through a responsive developer culture that now, a decade or two into this revolution, everyone takes as a given.
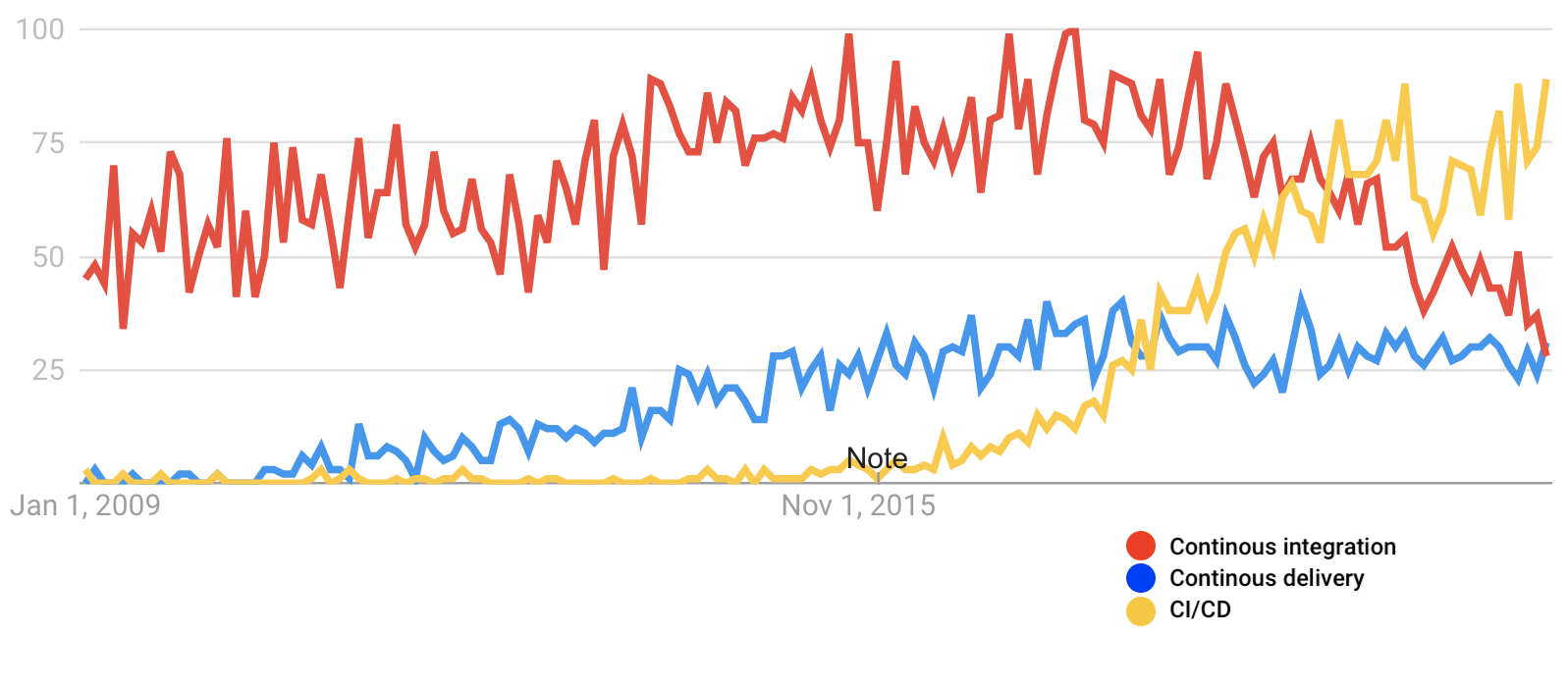
Graph showing how Continuous Integration (CI) and Continuous Delivery (CD) evolved independently. They were eventually conjoined by the term “CI/CD,” whose popularity as a search term only began to rise c. 2016 and did not displace the two separate terms until early in 2020. It is now increasingly rare to refer to “CI” or “CD” separately. Source: Google Trends
Onto that baseline were built tools and systems and philosophies that extended those fundamental principles. The Chaos Monkeys of the world, as well as the pentesters, want to break your system — or break into them — to uncover flaws and defects long before something stochastic and catastrophic or someone maliciously does it for you.
Cloud native technologies like Kubernetes and single source of truth for infrastructure methodologies like GitOps were created out of the sheer necessity to scale systems to the hundreds of thousands of production software deployments under management.
DevSecOps
And it’s not enough. We’ve already seen software supply chain attacks with SolarWinds, low level system attacks like Spectre, Meltdown and Zombieload, or human-factor threats like viral deep fakes and millions of fictitious social media accounts using profile images generated by Generative Adversarial Networks, never mind millions of IoT-enabled devices being nefariously harnessed for Distributed Denial of Service botnet attacks. Plus, just recently news broke of the vulnerability of log4j — our best wishes to anyone patching code this holiday season.
These are all just the bowshocks of what’s to come.
So now your AI-powered security systems are locked in combat every day in real time against the threat actors attempting to undermine your normal operations. We know this because a growing number of intrusion prevention and malware analysis systems are built at terabyte-and-beyond scale using distributed databases like ScyllaDB as their underlying storage engines.
Hence these days, rather than just “DevOps,” increasingly we talk about “DevSecOps” — because security cannot be an afterthought. Not even for your MVP. Not in 2021.
And these methodologies are continuing to evolve.
Summary
This next tech cycle is already upon us. You can feel it in the same way you’d yearn for a major life or career change. Maybe it’s a programming language rebase. Is it time to rewrite some of your core code as Rust? Or maybe it’s in the way you are considering repatriating certain cloud workloads, or extending your favorite cloud services on-premises such as through an AWS Outpost. Or maybe you’re actually looking to move data to the edge? Planning for a massive fan-out? Whatever this sea change means to you, you’ll need infrastructure that’s available today in a rock-solid form to take workloads into production right now, but flexible enough to keep growing with your emerging, evolving requirements.
We’ve built ScyllaDB to be that database for you. Whether you want to download ScyllaDB Open Source, sign up for ScyllaDB Cloud, or take ScyllaDB Enterprise for a trial, you have your choice of where and how to deploy a production-ready distributed database for this next tech cycle.

|

|

|
Learn More at ScyllaDB Summit 2022
To discover more about how ScyllaDB is the right database for this next tech cycle, we invite you to join us at ScyllaDB Summit 2022, this coming 09-10 February 2022. You’ll be able to hear about the latest features and capabilities of ScyllaDB, as well as hear how ScyllaDB is being deployed to handle some of the most challenging use cases on the planet. If you are building your own data infrastructure for this next tech cycle, find out how ScyllaDB can be right at the beating heart of it.









