





Only a specialized subset of engineers obsess over long-tail latencies — P99, P999, or even P9999 percentiles — and are truly fascinated by things like:
- Programming techniques like io_uring, eBPF, and AF_XDP
- Tracing techniques like OSNoise tracer and Flamegraphs
- Application-level optimizations like priority scheduling and object compaction
- Distributed storage system optimizations in Ceph, Crimson, and LightOS
- Ways to get the most out of unikernels like OSv and Unikraft
- Hardware architecture considerations like persistent memory and RISC-V
It’s not for everyone. Neither is P99 CONF, a new vendor-neutral conference supported and organized by ScyllaDB. P99 CONF was created “by engineers, for engineers” to bring together the world’s top developers for technical deep dives on high-performance, low-latency design strategies. We selected experts to share performance insights from a variety of perspectives, including Linux kernel, Rust, Java, Go, Kubernetes, databases, and event streaming architectures.
Day 1 of P99 CONF featured 18 sessions, incisive Q&A, and captivating conversations with (and even among) speakers in the lively speaker lounge. In case you missed it, here’s a quick snapshot of the Day 1 general sessions.
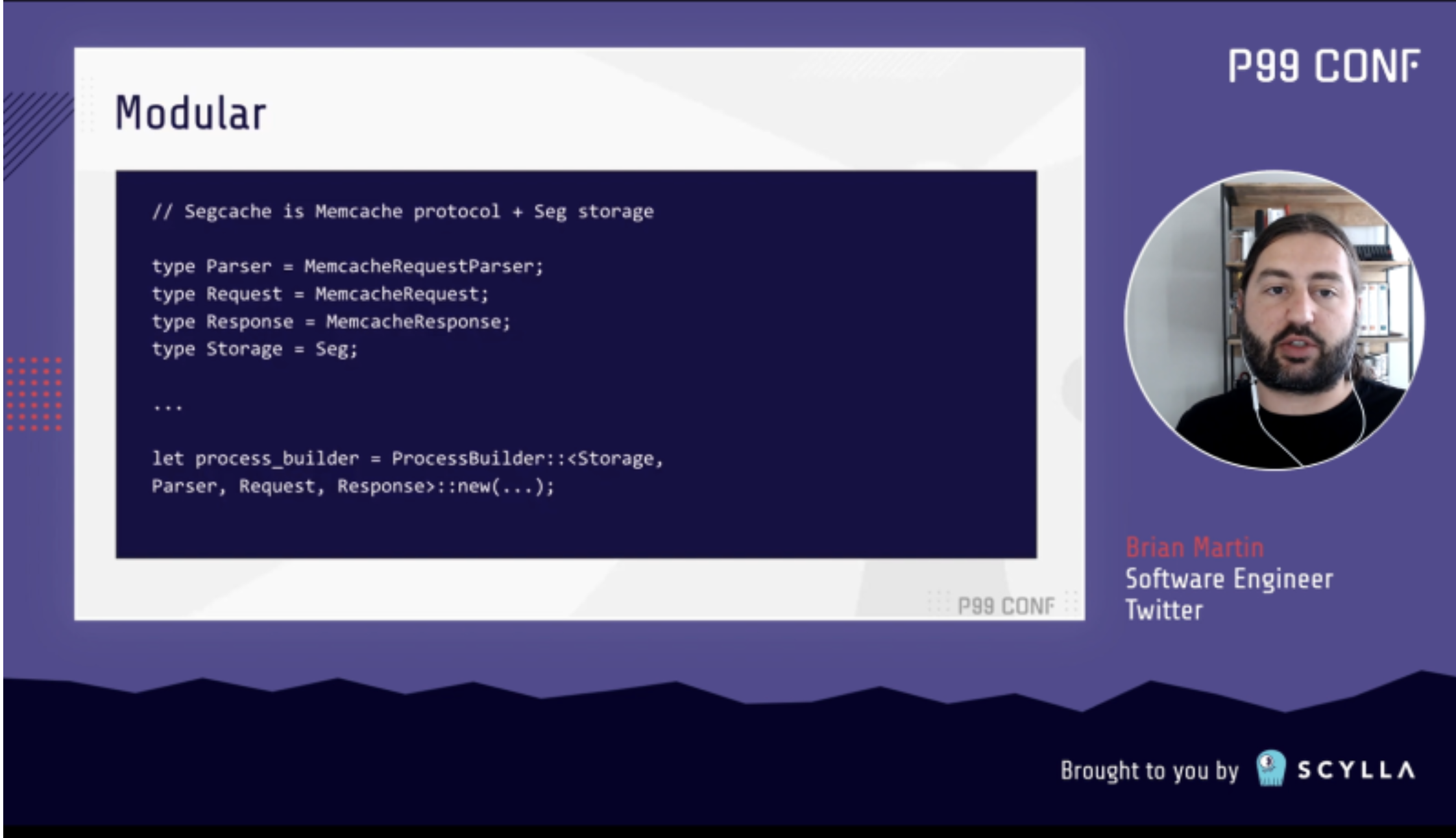
Whoops! I Rewrote It in Rust — Brian Martin
Twitter services’ scalability and efficiency are highly reliant on high-quality cache offerings.
They developed Pelikan as a caching system when Memcached and Redis didn’t fully meet their needs. Their #1 priority for Pelikan was “best-in-class efficiency and predictability through latency-oriented design and lean implementation.” This was initially achieved with a C implementation. However, two subsequent projects introduced Rust into the framework—with rather impressive development speed.
When they decided to add TLS support to Pelikan, Twitter Software Engineer Brian Martin suspected it could be done faster and more efficiently in Rust than in C. But to gain approval, the Rust implementation had to match (or beat) the performance of the C implementation.
Initial prototypes with the existing Rust-based Twemcache didn’t look promising from the performance perspective; they yielded 25-50% higher P999 latency as well as 10-15% slower throughputs. Even when Brian doubled down on optimizing the Rust prototype’s performance, he saw minimal impact. After yet more frustrating performance test results, he considered several different implementation approaches. Fortunately, just as he was weighing potential compromises, he came across a new storage design that made it easier to port the entire storage library over to Rust.
Brian went all in on Rust at that point—with a simplified single-threaded application and all memory allocations managed in Rust. The result? The 100% Rust implementation not only delivered performance equal to — or exceeding — both the C implementation and memcached. It also improved the overall design and enabled coding with confidence thanks to “awesome language features and tools,” which Brian then dove into.
WATCH BRIAN’S KEYNOTE ON DEMAND
Extreme HTTP Performance Tuning: 1.2M API req/s on a 4 vCPU EC2 Instance — Marc Richards
With over a decade of high-level performance tuning under his belt, Marc Richards recently tackled a low-level systems performance tuning project for an API server written in C. Reflecting on that adventure, his talk begins with 3 tips for anyone who’s curious about getting started with low-level performance tuning:
You don’t need to be a kernel developer or wizard sysadmin; it requires curiosity and persistence, but you can absolutely learn as you go along.
FlameGraph and bpftrace have really changed the game, making the discipline much more approachable.
There are a number of new eBPF-based tools on the horizon that will make things even easier.
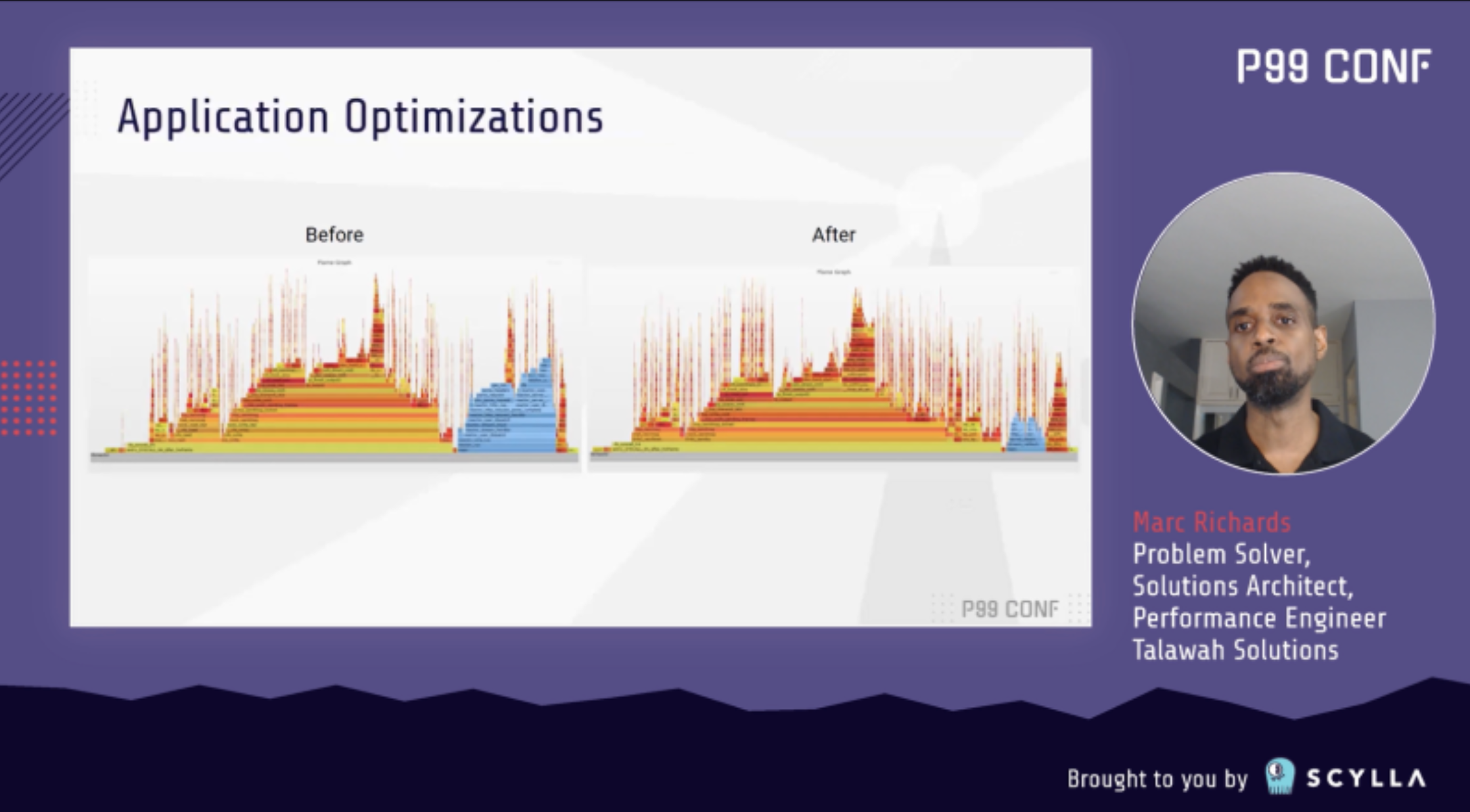
Shifting to the nuts and bolts of tuning, Marc outlined the 9 optimization categories that he focused on for this system, which was already rather high performing from the start (1.32ms P999 and 224k requests per second).
In the “application optimization” category alone, he achieved a staggering 55% gain (to 347k requests per second). By fixing a simple coding mistake, he was able to get the application running on all available cores—delivering a 25% improvement. Using the right combination of gcc flags in compiling the framework and application resulted in a 15% boost. Updating the framework to use send/recv calls instead of the more generic write and read added another 5%. Finally, he achieved an additional 3% increase by removing pthread overhead.
Richards continued to explain the various other optimizations he applied — carefully detailing why he decided to make each change and the performance improvement it delivered. The video covers the full range of optimizations, from perfect locality + interrupt optimizations to “the case of the nosy neighbor.” For an even deeper dive than Richards could provide in his 20 minute session, see his blog Extreme HTTP Performance Tuning: 1.2M API req/s on a 4 vCPU EC2 Instance.
WATCH MARC’S KEYNOTE ON DEMAND
Keeping Latency Low and Throughput High with Application-level Priority Management — Avi Kivity
Throughput and latency are at a constant tension. ScyllaDB CTO and co-founder Avi Kivity focused his keynote on discussing how high throughput and low latency can both be achieved in a single application by using application-level priority scheduling.
Avi began by outlining the stark contrast between throughput computing (OLAP) and latency computing (OLTP) and explaining the scenarios where it makes sense to mix these two types of jobs in a single application. When mixing is desired, two core actions are essential:
- Isolate different tasks for latency jobs and throughput jobs so you can measure and control them.
- Schedule them in a way that allows the latency jobs to be completed quickly, without interference from the throughput jobs.
But the devil is in the details. Do you take the common approach of isolating the tasks in threads and letting the kernel schedule them? It’s generally easier, but it doesn’t yield sufficient control or efficiency to achieve the optimal results.
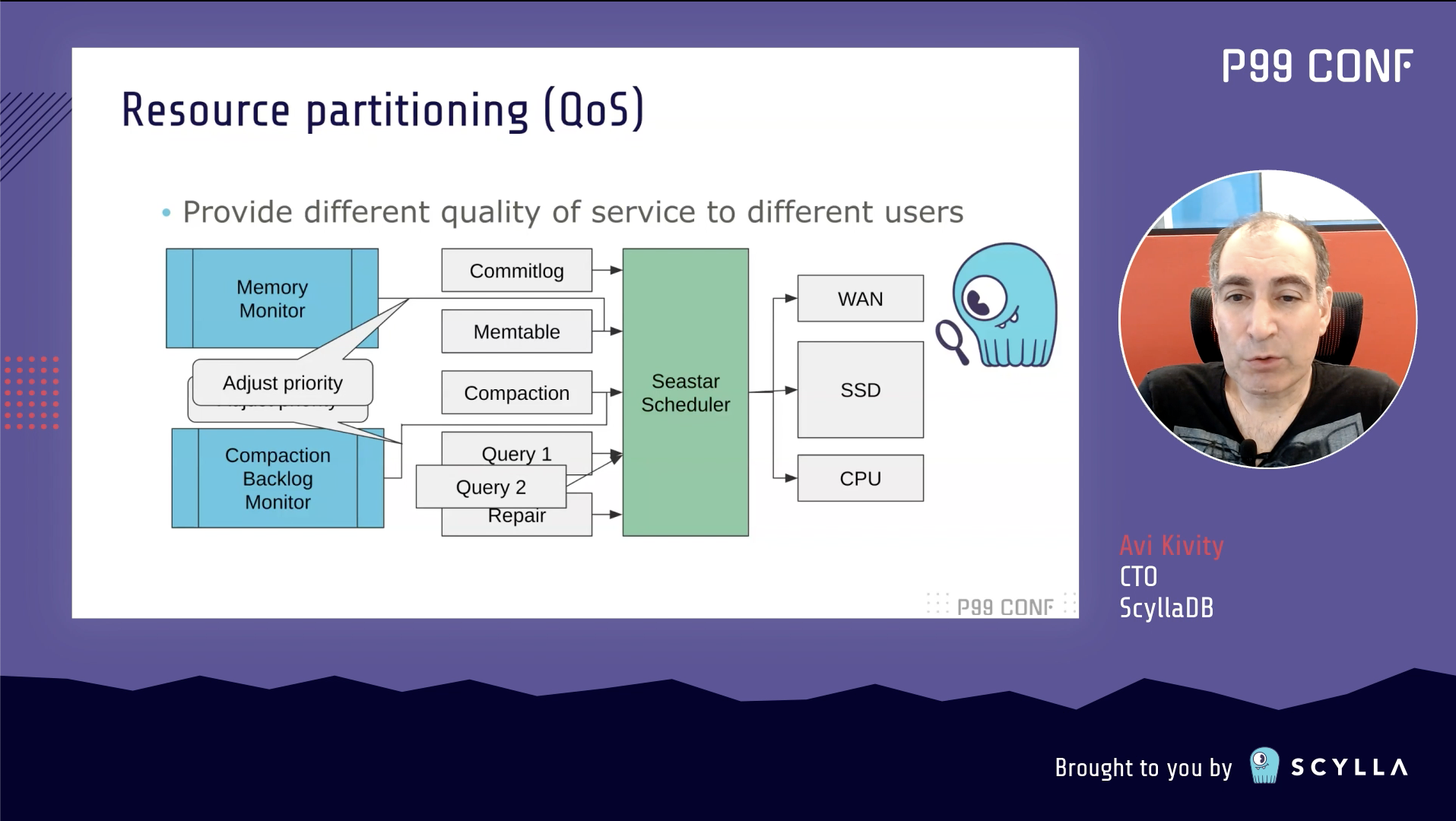
The alternative is application-level task isolation. Here, every operation is a normal object and tasks are multiplexed on a small number of threads (ideally, one thread per logical core, with both throughput- and latency-sensitive tasks on the same thread). A concurrency framework assigns tasks to threads and controls the order in which tasks are executed. This means you can fine-tune everything to your heart’s content… but all that fine-tuning can be addictive, drawing your attention away from other critical tasks. More advantages: there’s low overhead, simpler locking, good CPU affinity, and fewer surprises from the kernel. It’s a less mature (though improving) ecosystem, but Avi feels strongly that the extra effort required pays off immensely.
After visualizing what the execution timeline looks like, Avi delved into the finer details of switching queues, preemption techniques, and using a stall detector. To wrap up, he explained how it all plays out in a real-world example: ScyllaDB.
Track Sessions Across Core Low Latency Themes
The parallel track sessions addressed a broad spectrum of highly specialized topics. Here’s an overview of the amazing track sessions from Day 1, grouped by topic:
Observability
- Peter Zaitsev (Percona) presented 3 performance analysis approaches + explained the best use cases for each in “Performance Analysis and Troubleshooting Methodologies for Databases.”
- Heinrich Hartmann (Zalando) shared strategies for avoiding pitfalls with collecting, aggregating and analyzing latency data for monitoring and benchmarking in “How to Measure Latency.”
- Thomas Dullien (Optimyze.cloud) exposed all the hidden places where you can recover your wasted CPU resources in “Where Did All These Cycles Go?”
- Daniel Bristot de Oliveira (Red Hat) explored operating system noise (the interference experienced by an application due to activities inside the operating system) in “OSNoise Tracer: Who is Stealing My CPU Time?”
Programming Languages
- Felix Geisendörfer (Datadog) dug into the unique aspects of the Go runtime and interoperability with tools like Linux perf and bpftrace in “Continuous Go Profiling & Observability.”
- Glauber Costa (Datadog) outlined pitfalls and best practices for developing Rust applications with low p99 in his session “Rust Is Safe. But Is It Fast?”
Distributed Databases
- Dhruba Borthakur (Rockset) explained how to combine lightweight transactions with real-time analytics to power a user-facing application in “Real-time Indexing for Fast Queries on Massive Semi-Structured Data.”
Distributed Storage Systems
- Sam Just (Red Hat) shared how they architected their next-generation distributed file system to take advantage of emerging storage technologies for Ceph in “Seastore: Next Generation Backing Store for Ceph.”
- Orit Wasserman (Red Hat) talked about implementing Seastar, a highly asynchronous engine as a new foundation for the Ceph distributed storage system, in “Crimson: Ceph for the Age of NVMe and Persistent Memory.”
- Abel Gordon (Lightbits Labs) covered ways to achieve high-performance low-latency NVMe based storage over a standard TCP/IP network in “Vanquishing Latency Outliers in the Lightbits LightOS Software Defined Storage System.”
New Hardware Architectures
- Pavel Emelyanov (ScyllaDB) talked about ways to measure the performance of modern hardware and what it all means for database and system software design in “What We Need to Unlearn about Persistent Storage.”
- Doug Hood (Oracle) compared the latency of DDR4 DRAM to that of Intel Optane Persistent Memory for in-memory database access in “DB Latency Using DRAM + PMem in App Direct & Memory Modes.”
Streaming Data Architectures
- Karthik Ramaswamy (Splunk) demonstrated how data — including logs and metrics — can be processed at scale and speed with Apache Pulsar in “Karthik Ramasamy Scaling Apache Pulsar to 10 Petabytes/Day.”
- Denis Rystsov (Vectorized) shared how Redpanda optimized the Kafka API and pushed throughput of distributed transactions up to 8X beyond an equivalent non-transactional workload in “Is It Faster to Go with Redpanda Transactions than Without Them?!”
Day 2 of all things P99
Day 2 continued the conversation on many of the topics covered in Day 1 (Rust, event streaming architectures, low-latency Linux, and observability) and also expanded into new areas (unikernels and Kubernetes, for example).
Following Dor Laor’s intro, Day 2 kicked off the sessions with Bryan Cantrill (Co-founder and Chief Technology Officer at Oxide Computer Company) speaking on “Rust, Wright’s Law, and the Future of Low-Latency Systems.” Spoiler: he believes that the future of low-latency systems will include Rust programs in some very surprising places. Bryan’s talk led into 17 more sessions, including highly anticipated talks like:
- Steven Rostedt, VMware Open Source Engineer, digging deep into new flexible and dynamic aspects of ftrace to expose latency issues in different contexts.
- Tejas Chopra, Netflix Senior Software Engineer, sharing how Netflix gets massive volumes of media assets and metadata to the cloud fast and cost-efficiently.
- Yarden Shafir, Crowdstrike Software Engineer, introducing Windows’ implementation of I/O rings, demonstrating how it’s used, and discussing potential future additions.
- Waldek Kozaczuk, OSv committer, talking about optimizing a guest OS to run stateless and serverless apps in the cloud for CNN’s video supply chain.












