





This post is by 2021 P99 CONF speaker Glauber Costa, founder and CEO of ChiselStrike. It first appeared as an article in ITNext. To hear more from Glauber and many more latency-minded engineers, sign up for P99 CONF updates.
I have previously written about how major changes in storage technology are changing conventional knowledge on how to deal with storage I/O. The central thesis of the article was simple: As fast NVMe devices become commonplace, the impact of the software layer gets bigger. Old ideas and APIs, designed for a time in which storage accesses were in the hundreds of milliseconds should be revisited.
In particular, I investigated the idea that Buffered I/O, where the operating system caches data pages on behalf of the user should always be better than Direct I/O, where no such caching happens. Once we employ modern APIs that is simply not the case. As a matter of fact, in the example using the Glommio io_uring asynchronous executor for Rust, Direct I/O reads performed better than Buffered I/O in most cases.
But what about writes? In this article, we’ll take a look at the issue of writes, how it differs from reads, and show that much like credit card debt, Buffered I/O writes are only providing the illusion of wealth on cheap money. At some point in time, you still have to foot the bill. Real wealth, on the other hand, comes from Direct I/O.
How Do Reads and Writes Differ?
The fact that reads and writes differ in their characteristics should surprise no one: that’s a common thing in computer science, and is what is behind most of the trend toward immutable data structures in recent years.
However, there is one open secret about storage devices in particular that is nothing short of mind-blowing:

It is simply not possible to issue atomic writes to a storage device. Or at least not in practice. This stackoverflow article does a good job summarizing the situation, and I also recommend this LWN.net article that talks about changes some Linux Filesystem developers are discussing to ameliorate the situation.
For SSDs the situation is quite helpless. For NVMe, it is a bit better: there is a provision in the spec for atomic writes, but even if all devices implemented it (which they don’t), there’s still a big contingent of devices where software has to run on where this is simply not available.
For this reason, writes to the middle of a file are very rare in applications, and even when they do happen, they tend to come accompanied by a journal, which is sequential in nature.
There are two immediate consequences of this:
- Append-only data structures vastly dominate storage writes. Most write-optimized modern stores are built on top of LSM trees, and even workloads that use more traditional data structures like B-Trees will have a journal and/or other techniques to make sure data is reliably written.
- There is usually a memory buffer that is used to accumulate writes before they are passed into the file: this guarantees some level of control over the state of the file when the write happens. If we were to write directly to an mmap’d file, for instance, flushes could come at any time and we simply would have no idea in which state the file is in. Although it is true that we can force a maximum time for a sync with specialized system calls like msync the operating system may have to force a flush due to memory pressure at any point before that.
What this means is that coalescing, which is the usual advantage of buffering, doesn’t apply for writes. For most modern data structures, there is little reason to keep a buffer in-memory waiting for the next access: likely what is sent to the file is never touched again, except for future reads. And at that point the calculations in my read article apply. The next write is likely for the next position in the file.
This tips the scale even more in favor of Direct I/O. In anticipation of using the recently written pages in the future, Buffered I/O may use an immense amount of memory in the operating system page cache. And while is true that this is cached memory, that memory needs to be written to the device first before it can be discarded. If the device is not fast enough, we can easily run out of memory. This is a problem I have written about in the past.
Since we can write an entire Terabyte-large file while keeping only a couple of kilobytes in memory, Direct I/O is the undisputed way to write to files.
But How Much Does Direct I/O Cost?
Much like reads, you need to make sure you are measuring the right thing to realize the advantage of Direct I/O. And how to do that that is far from obvious.
Recently, one of our users opened an issue in our Github page, in which he noted that despite what we advertise, Direct I/O writes consumed a lot more CPU than buffered writes. So why is that?
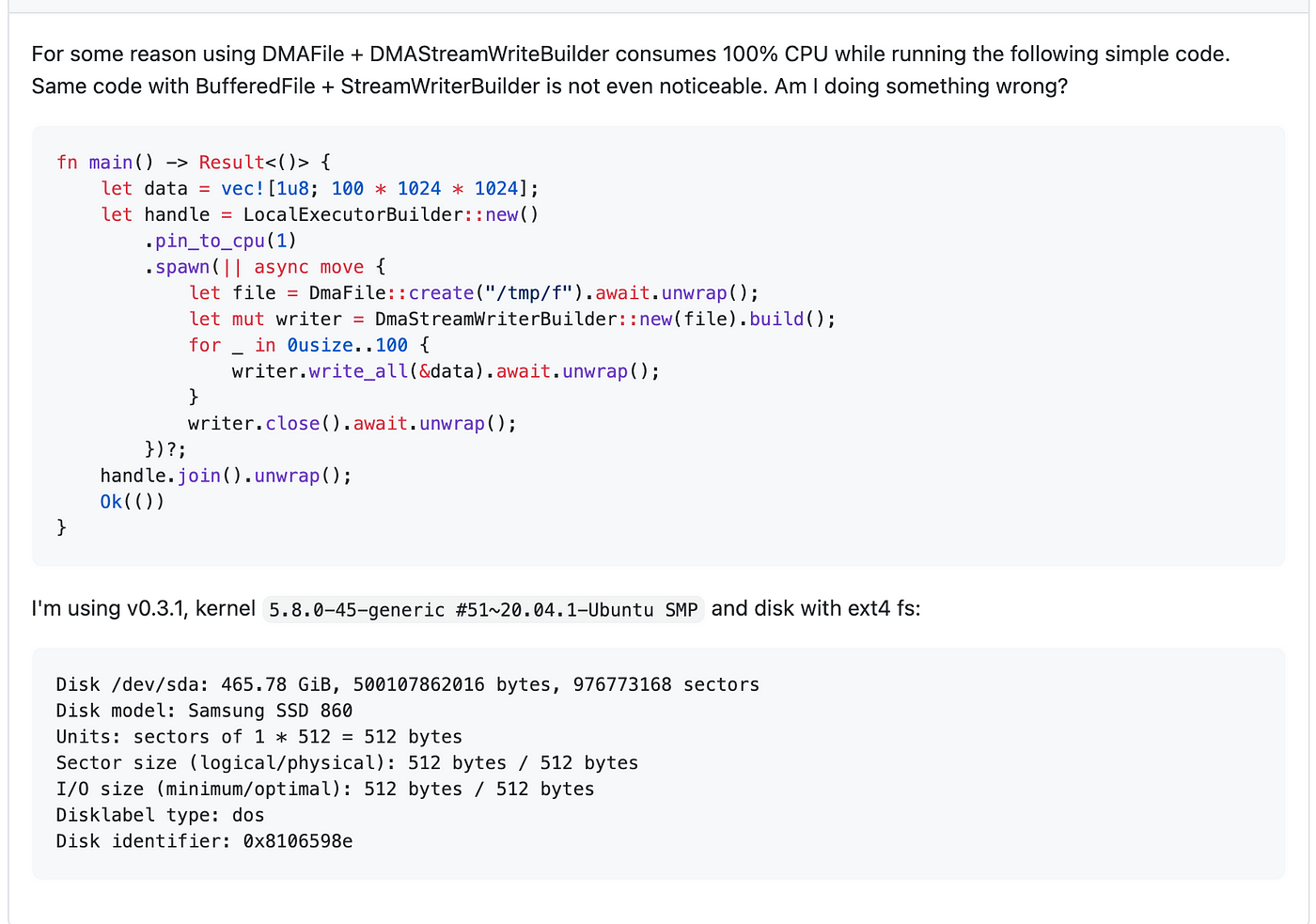
The reason is: Buffered writes are like a loan: you can get your asset for cheap now, but you then have to pay it back in the future, with interest. When you issue a Direct I/O write, you are paying most of the costs related to the transaction right away, and in the CPU that dispatched the I/O — which is predictable. The situation is different for Buffered I/O: the only cost to be paid immediately are the very cheap memory writes.
The actual work to make the data persistent is done in kernel threads. Those kernel threads are free to run in other CPUs, so in a simple system that is far from its saturation point, this can give the user the illusion of cheaper access.
Much like a loan, there are certainly cases in which this can work in your favor. However, in practice, that will happen at an unpredictable — and potentially inconvenient time in the future.
Aside from this unpredictability, in order to make the right decision one needs to be at least aware of the fact that the total cost of the loan may be higher. More often than not it can be the case that at or close to saturation, all your CPUs are busy, in which case the total cost is more important.
If we use the time command to measure the Direct I/O vs Buffered version of the same code provided by the user, and focus on system and user times, we have:
Direct I/O:
user 0m7.401s sys 0m7.118s
And Buffered I/O:
user 0m3.771s sys 0m11.102s
So there we have it: all that the Buffered I/O version did was switch user time to system time. And because that system time is consumed by kernel threads, which may be harder to see, we can get the illusion that buffered writes are consuming less CPU.
But if we sum up user and system times, we can clearly see that in reality we’re eventually paying interest on our loan: Buffered writes used 1.7% more CPU than Direct I/O writes. This is actually not very far from current monthly interest rates on my credit card. If this is a shocking coincidence or a big conspiracy, is up for you, the reader, to decide.
But Which is Faster?
Many users would be happy to pay some percentage of CPU time to get faster results. But if we look at the real time in the examples above, Direct I/O is not only cheaper, but faster.
You will notice in the example code that the user correctly issued a call to close. By default, Glommio’s stream close imply a sync. But not only that can be disabled, most of the time in other languages and frameworks this is not the case. In particular, for Posix, close does not imply a sync.
What that means is that even after you write all your buffers, and close your file, your data may still not safely be present in the device’s media! What can be surprising, however, is that data is not safely stored even if you are using Direct I/O! This is because Direct I/O writes the data immediately to the device, but storage devices have their own internal caches. And in the event of a power loss data can still be lost if those caches are not persisted.
At this point it is fair to ask: if a sync is necessary for both buffered writes and Direct I/O, is there really an advantage to Direct I/O? To investigate that behavior we can use Glommio’s example storage benchmark.
At first, we will write a file that is smaller than memory and not issue a sync. It is easy to have the impression that Buffered I/O is faster. If we write a 4GiB file in a server with 64GiB of DRAM, we see the following:
Buffered I/O: Wrote 4.29 GB in 1.9s, 2.25 GB/s Direct I/O: Wrote 4.29 GB in 4.4s, 968.72 MB/s
Buffered I/O is more than twice as fast! That is because since the file is so small compared to the size of memory, it can just sit in memory for the whole time. However, at this point your data is not safely committed to storage at all. If we account for the time-to-safety until our call to sync returns, the setup costs, lack of parallelism, mapping, and other costs discussed when analyzing reads start to show:
Buffered I/O: Wrote 4.29 GB in 1.9s, 2.25 GB/s Buffered I/O: Closed in 4.7s, Amortized total 642.54 MB/s Direct I/O: Wrote 4.29 GB in 4.4s, 968.72 MB/s Direct I/O: Closed in 34.9ms, Amortized total 961.14 MB/s
As we can see, Buffered I/O loans provided us with the illusion of wealth. Once we had to pay the bill, Direct I/O is faster, and we are richer. Syncing a Direct I/O file is not free, as previously noted: but 35ms later we can predictably guarantee it is safely stored. Compare that to the more than 4s for Buffered I/O.
Things start to change as the file gets bigger. That is because there is more pressure in the operating system virtual memory. As the file grows in size, the operating system is no longer able to afford the luxury of waiting until the end to issue a flush. If we now write 16 GiB, a 32Gib, and a 64Gib file, we see that even the illusory difference between Buffered and Direct I/O start to fade away
Buffered I/O: Wrote 17.18 GB in 10.4s, 1.64 GB/s Buffered I/O: Closed in 11.8s, Amortized total 769.58 MB/s Buffered I/O: Wrote 34.36 GB in 29.9s, 1.15 GB/s Buffered I/O: Closed in 12.2s, Amortized total 814.85 MB/s Buffered I/O: Wrote 68.72 GB in 69.4s, 989.7 MB/s Buffered I/O: Closed in 12.3s, Amortized total 840.59 MB/s
In all the cases above Direct I/O kept writing at around 960MB/s, which is the maximum throughput of this particular device.
Once the file gets bigger than memory, then there is no more pretending: Direct I/O is just faster, from whichever angle we look at it.
Buffered I/O: Wrote 107.37 GB in 113.3s, 947.17 MB/s Buffered I/O: Closed in 12.2s, Amortized total 855.03 MB/s Direct I/O: Wrote 107.37 GB in 112.1s, 957.26 MB/s Direct I/O: Closed in 43.5ms, Amortized total 956.89 MB/s
Conclusion
Having access to credit is not bad. It is, many times, crucial for building wealth. However, we need to pay attention to total costs, make sure the interest rates are reasonable, to be sure we are building real, and not illusory wealth.
When writing to files on modern storage, the same applies. We can write them for cheap at first, but we are bound to pay the real cost — with interest — later. Whether or not that is a good thing is certainly situational. But with high interest rates and a potential for memory spiraling out of control if you write faster than what the device can chew, Buffered I/O can easily become subprime. Direct I/O, with its fixed memory usage, and cheaper CPU costs, is AAA.
I hope this article will empower you to make better choices so you can build real storage wealth.
WATCH GLAUBER’S P99 CONF SESSION: RUST IS SAFE, BUT IS IT FAST




