





Apache Pulsar is an open source event streaming platform continually rising in popularity since its first public release in 2016. It graduated from incubator status to top level Apache Foundation project in just two years. Since then the Pulsar community continues to grow by leaps and bounds, now boasting over 500 contributors.
The scale, timeline and growth of Apache Pulsar mirrors the rise of ScyllaDB in many ways. Both systems cater to highly scalable, low-latency and high performance use cases. And it is no surprise there is increasing interest in our respective user bases to see how a big, fast NoSQL database like ScyllaDB can be used by a big, fast event streaming service like Apache Pulsar. In fact, thousands of people signed up to learn exactly how to do just that when StreamNative and ScyllaDB partnered to host a Distributed Data Systems Masterclass in June.
I was honored and pleased to be given an opportunity to speak at the recent Pulsar Summit in San Francisco. Another day I’ll share the talk I gave. For now I wanted to give you a glimpse into many of the other speakers who presented, and some insights into the momentum this event reflected on the broad adoption of Apache Pulsar and its integration into other open source communities.
Top 5 Apache Software Foundation Project
The keynote of StreamNative CEO Sijie Guo was informative as to just how popular and influential the Apache Pulsar project has become. He pointed out that Pulsar was one of the Top Five Apache Software Foundation (ASF) projects in terms of commits. It continues to broaden in all dimensions of a healthy and booming open source community, from committer base (now over 500 developers, who have made over 10,000 commits), to Slack community size (over 7,000 members), to the thousand-plus organizations who are running Pulsar in production.

He then turned the stage over to StreamNative CTO Matteo Merli, who introduced (pf)SQL. This capability, built on top of Pulsar Functions, will allow filtering, transformation and routing of data, and also allow transformations for Pulsar IO connectors. It won’t replace a dedicated system that provides such a service — for example, Apache Flink — but it will allow users to write more complex components that reside natively within Pulsar.

Apache Beam
Matteo was followed by Google’s Bryon Ellis, who is working on the Apache Beam project. Beam, another ASF top-level project, is a unified system to do both batch and stream data processing pipelines and transformations. Neither batch nor streaming is an afterthought (as Bryon’s slides noted, “Batch is batch, and streaming is streaming”).
What makes Beam somewhat unique is that the I/O connectors are directly part of the project. Given the growing popularity of Pulsar, the Beam team decided to add it to their growing list of supported systems. The great news is that as of June 2022 the first pull request from StreamNative of PulsarIO was done, and you can try it out now on your own machine using the Beam DirectRunner, or by running Beam pipelines in Spark, Flink, or Google Cloud Dataflow. There is still a lot more work to cover all the features of Pulsar, though, so interested community members can follow progress (or offer to contribute) on the related JIRA page here.
Apache Pinot
Next up on the main stage was Xiang Fu, co-founder of StarTree, the team behind the Apache Pinot project. Pinot was designed to do Online Analytical Processing (OLAP) blazingly fast. Designed for near real time ingestion and low latency, Pinot makes for a perfect pairing with Apache Pulsar.

Xiang observed these new data architectures and analytics capabilities allow organizations to fundamentally change how they use and expose data. Whereas in the past analytics was seen as the proprietary purview of the organization itself, increasingly there is a movement to expose data analytics to external partners and customers. This data democratization has to take into account the time-value of data, and the window of opportunity for these events. We’ve moved from a world of days or hours of computation to produce results to timeframes measured in seconds or even milliseconds.
The challenge is the cycle we’ve created. As we improve user experience and increase engagement, we also require collecting and managing more and more events. We’ve moved from basic publish-and-subscribe (pub-sub), to log aggregation, to stream processing (such as Flink or Beam) to real time analytics (such as Pinot). As our data ingestion happens at ever increasing scales, to do so with low latency millions of times per second becomes hard.
Xiang brought up three examples of Pinot being used at scale. The first was LinkedIn (birthplace of the Pinot project), where they ingest a million events per second, run over 200,000 queries against their dataset per second, and query latency is measured in milliseconds. The second was at Uber, with over 200 terabytes of data, 30,000 queries per second, and latencies faster than 100 milliseconds. The third was at Stripe, where the massive trillion-row dataset is over a petabyte in total size. Even then they get subsecond latency for their queries.
Mercado Libre

Ignacio Alvarez of Mercado Libre then spoke about their use of Pulsar. Mercado Libre is an online shopping platform popular across Latin America, with a massive user base. Some estimates put it as high as 140 million active users per month. Supporting a real-time shopping experience for a user base that large translates to 200 million requests per minute (3.3 million events per second). Mercado Libre maintains thirty active Pulsar clusters on AWS Graviton-based servers, allowing them to run cost-effectively. Definitely a use case to pay attention to.

Databricks Data Lakehouse
At this point the event broke into two tracks. I participated in the Ecosystem track, emcee’d by StreamNative’s Tim Spann, and the following will reflect what I was able to see therein. The first talk in the track was delivered by DataBricks’ Nick Karpov, who described the movement from the ETL-oriented data warehouses of the 1980s and data lake of the 2010s to the streaming-oriented architecture of the “data lakehouse.” The lakehouse architecture also provides new query engines, and metadata and governance layers on top of the raw data, making data easier to manage and faster to effectively access.
I found the discussion about Z-order multidimensional clustering for data-skipping particularly interesting. It’s a method to improve on sorting, minimizing the number of files needed to scan and the number of false positive results.
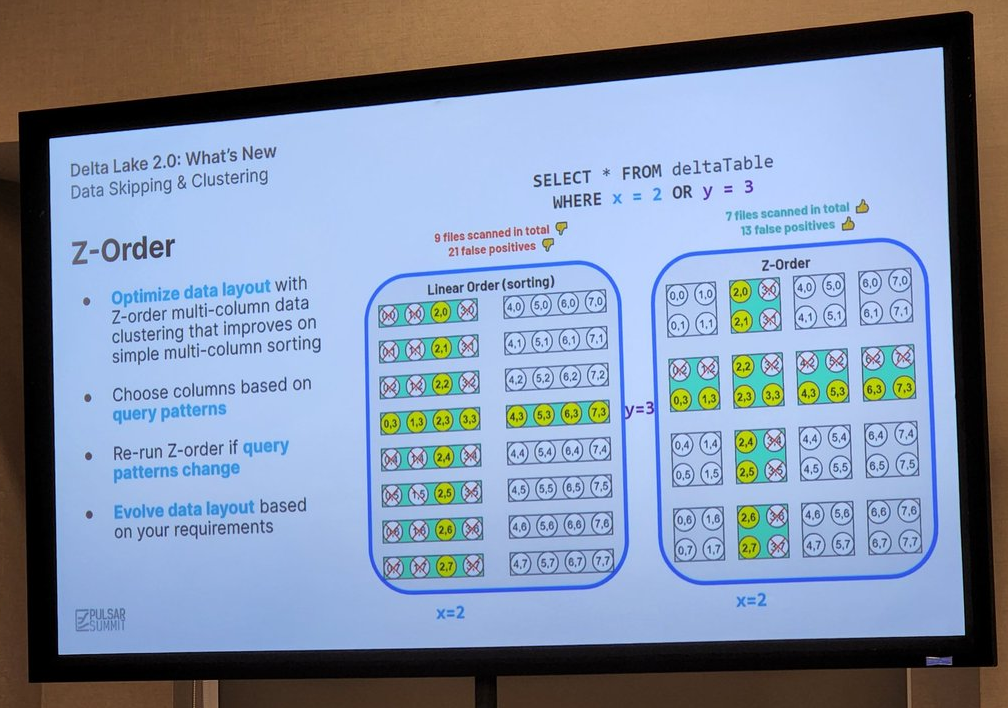
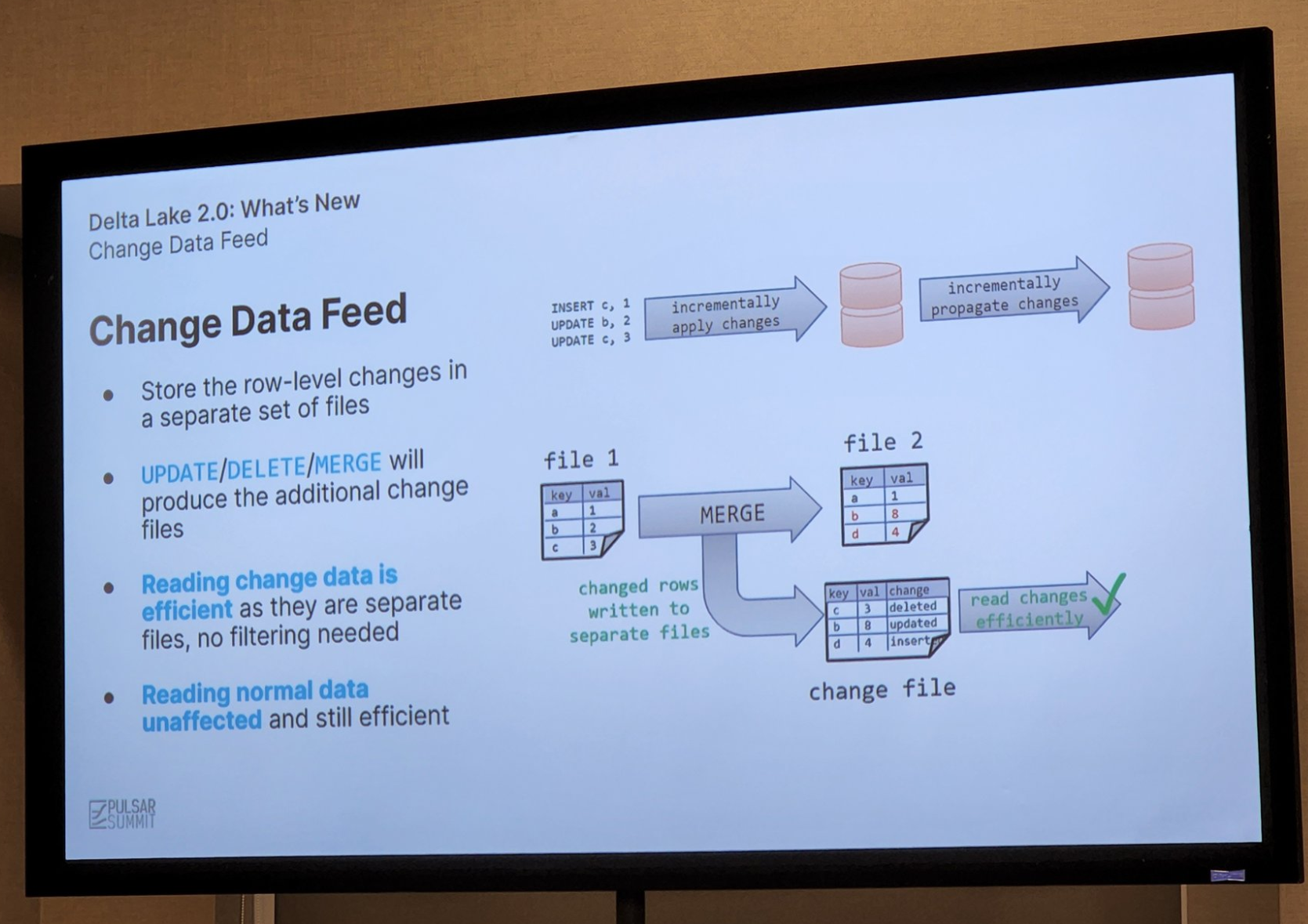
Then again, if you are more of a fan of Change Data Capture (CDC), this is called Change Data Feed in the Databricks Delta table context, and Nick covered that too in his talk, noting that it can either be read as a batch or as an event feed.
Specifically for Apache Pulsar, there are Lakehouse connectors available, allowing you to integrate Lakehouse as both source and sink. It is under active development, providing opportunities for contribution. For example CDC files are not yet implemented, and the Delta-Pulsar-Delta round trip only supports append-only workflows. So stay tuned for updates!
Apache Hudi
Next up was Alexey Kudinkin of Onehouse, the lakehouse-as-a-service provider built on Apache Hudi. While conceptually there are a lot of components you can connect to Hudi, at its core it provides transactions, upserts, and deletes on datalake storage and enables CDC when used with Pulsar.
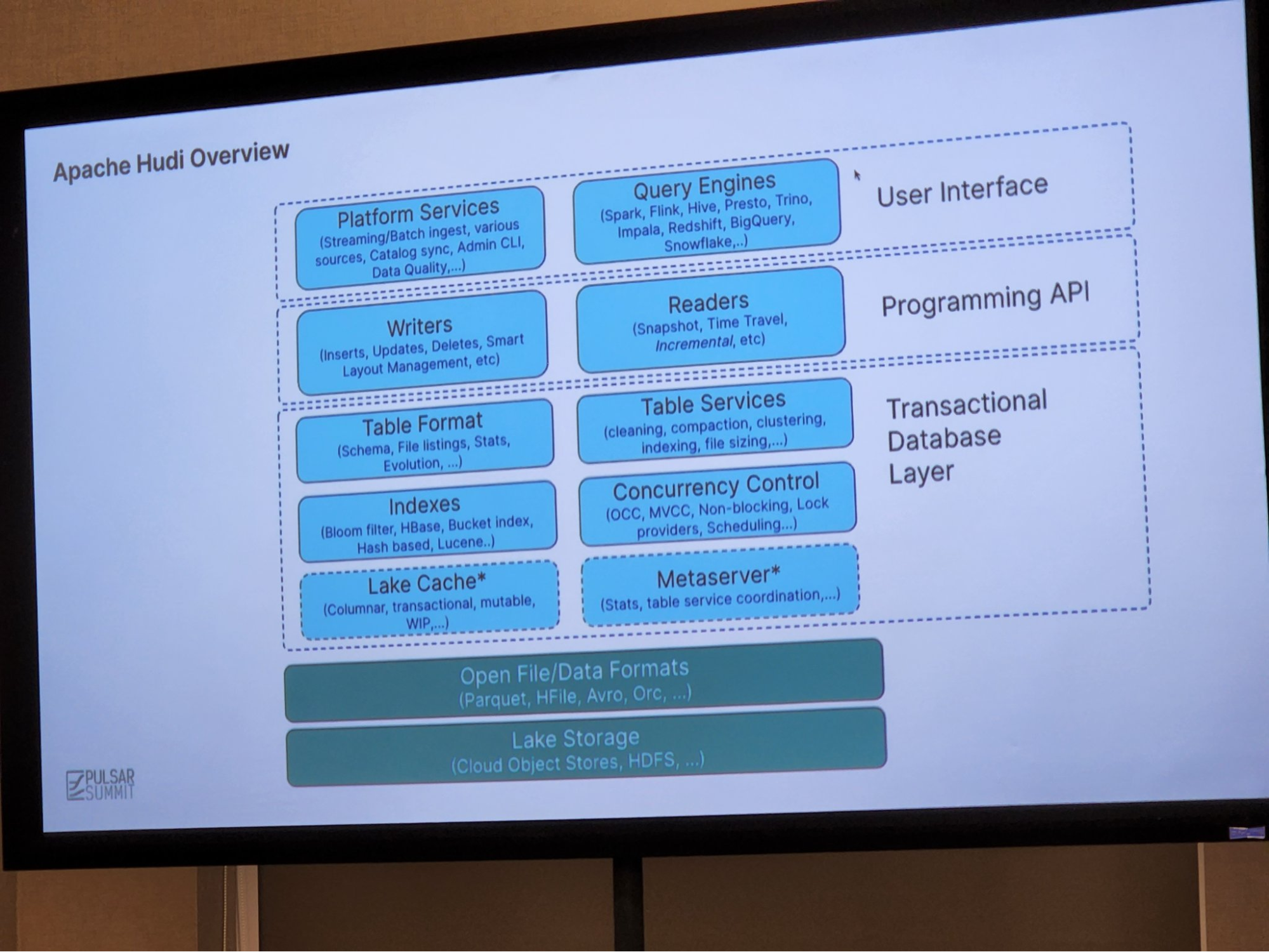
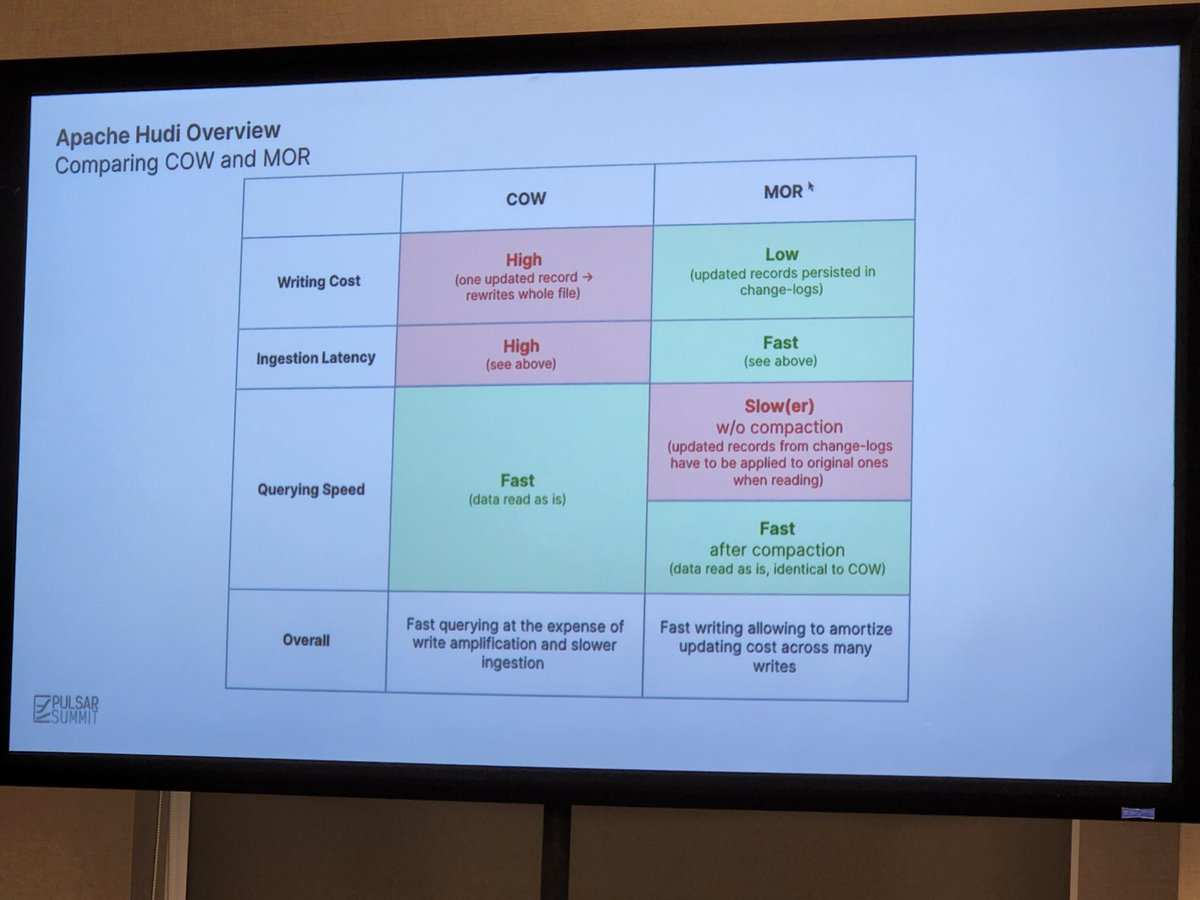
One particular facet that Alexey drilled down on was comparing copy-on-write (COW) versus merge-on-read (MOR). In COW data is stored in Parquet files in a columnar format; the file is copied and updates are merged into the file on writes. MOR is a bit more complicated, because data is stored in both columnar-oriented Parquet files and row-based Avro formats. In this latter case, data is logged to delta files and later compacted. You can discover more in the Hudi documentation here. Which system you use depends on the various tradeoffs to optimize for in terms of latency, update cost, file size, and write amplification.
Addison Higham, StreamNative’s Chief Architect and Head of Cloud Engineering, joined Alexey onstage to talk about the use cases and best practices in joining Pulsar and Hudi together.
Currently there are a few ways to currently integrate Pulsar and Hudi:
- Pulsar’s Apache Spark connector
- Hudi’s DeltaStreamer utility
- StreamNative’s Lakehouse Sink (currently in Beta)
One of the critical determinations users need to make when combining Hudi and Pulsar together is based on the domain of data over time. Are these results you need processed in milliseconds, or over months? Based on the atomicity of the data you are dealing with, or the complexity or sheer scale of it, will determine if you should lean towards the event-driven engines of Pulsar or the massive analytics capabilities of Hudi. And there are these in-between places, where you may be pre- or post-processing data, such as in Flink, Pinot, Hive or Spark.
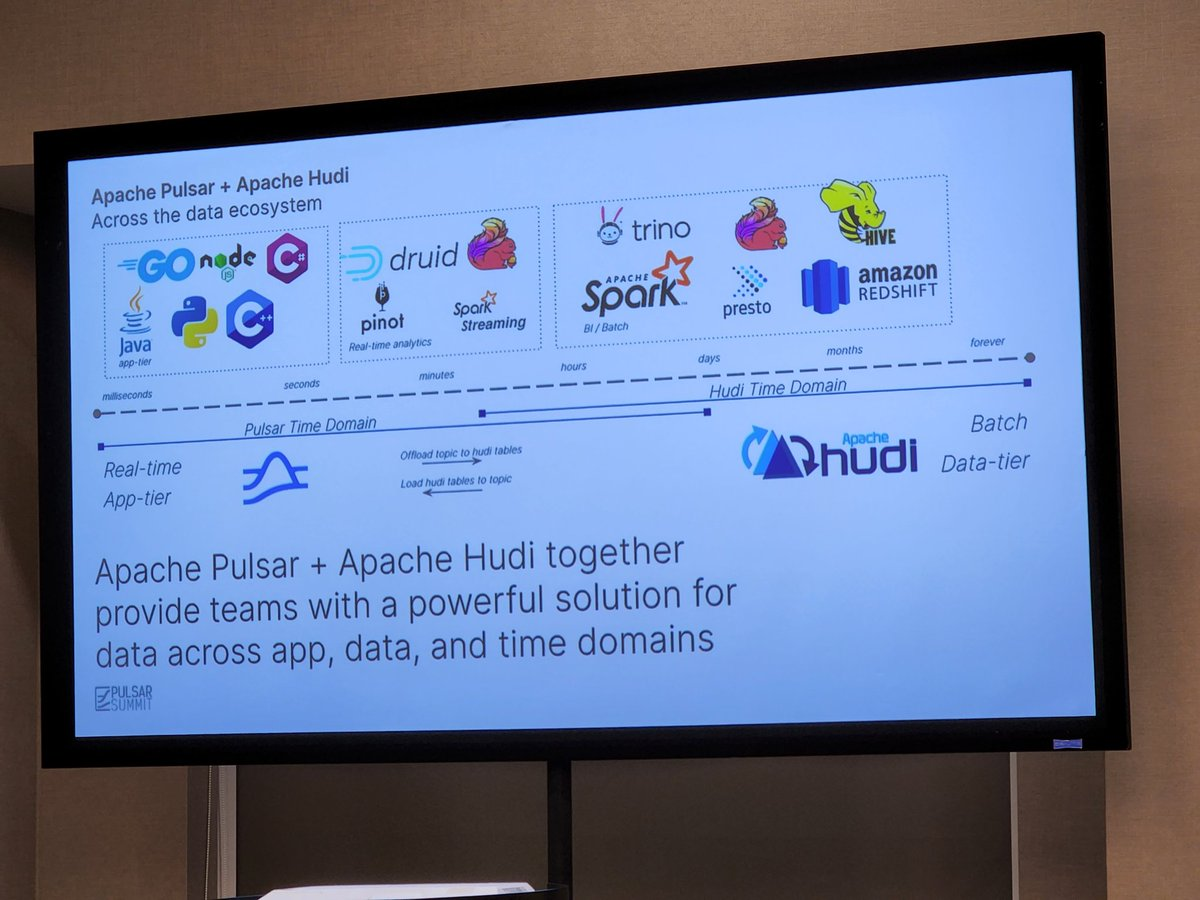
Apache Flink

Speaking about Apache Flink, Caito Scherr of Ververica came to provide insights of using this popular stream processing platform. There are a lot of challenges to master. You can’t pause a stream to fix it. You’re dealing with a lot of data coming at you fast, and you have to ingest it in multiple formats. There’s failures to recover from, and there’s this inexorable need to scale.
Hence Flink. Caito noted the name itself means “nimble” in German. It was designed to make stream processing easier by solving a lot of problems in streaming. Yet there are still conceptual barriers you have to wrap your head around to really “get” Flink. Such as running SQL queries on event streaming: you aren’t returned a discreet result set; your query is continuous.

If you are interested in getting involved with Flink you can check out their community page, and join their Slack community.
Kafka-on-Pulsar
AWS’ Ricardo Ferreira presented one of those crazy-ideas-that-just-might-work: Kafka-on-Pulsar (KoP). What if you were a Kafka developer and you wanted to write a “Kafka” service that actually had Apache Pulsar at its heart?

You would write your microservice as you might usually do in Spring Boot. Or consume CDC data from MySQL using a Debezium connector. Or maybe you want to be able to do stream processing using ksqlDB to transform events — flattening out a nested structure, and move them from JSON to protobuf. You think it’s all Kafka. But meanwhile, hidden away, the backbone is Pulsar.
Ricardo walked us through the method to “wrap” Pulsar in such a way that it looked, smelled, and acted like Kafka to external systems. Not only was his talk entertaining and illuminating, but the extensive Github repository, both code and documentation, will give users great hands-on examples they can use for their own environments.
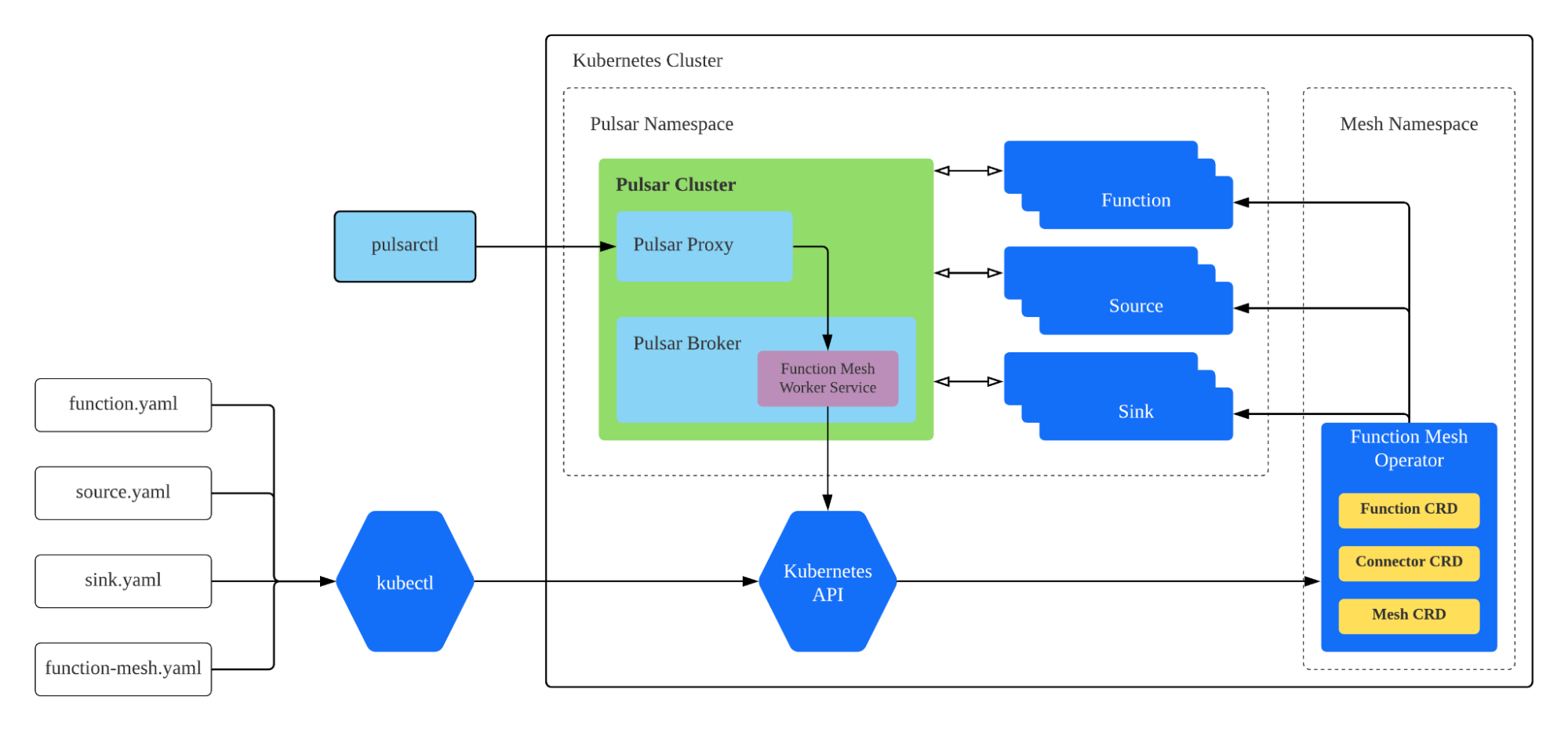
Pulsar Functions and Function Meshes
The talk just before mine was hosted by Neng Lu, StreamNative’s Platform Engineering Lead, Compute. He recapped the serverless function mesh architecture. It consists of a set of Custom Resource Definitions (CRDs) for defining Pulsar Functions and sink or source connectors, plus an operator that constantly reconciles the submitted CR, creating it, updating according to user change, or auto-scaling if configured. There are a lot of use cases for Pulsar Functions and function meshes, such as filtering/routing, or to add transformations for connectors.
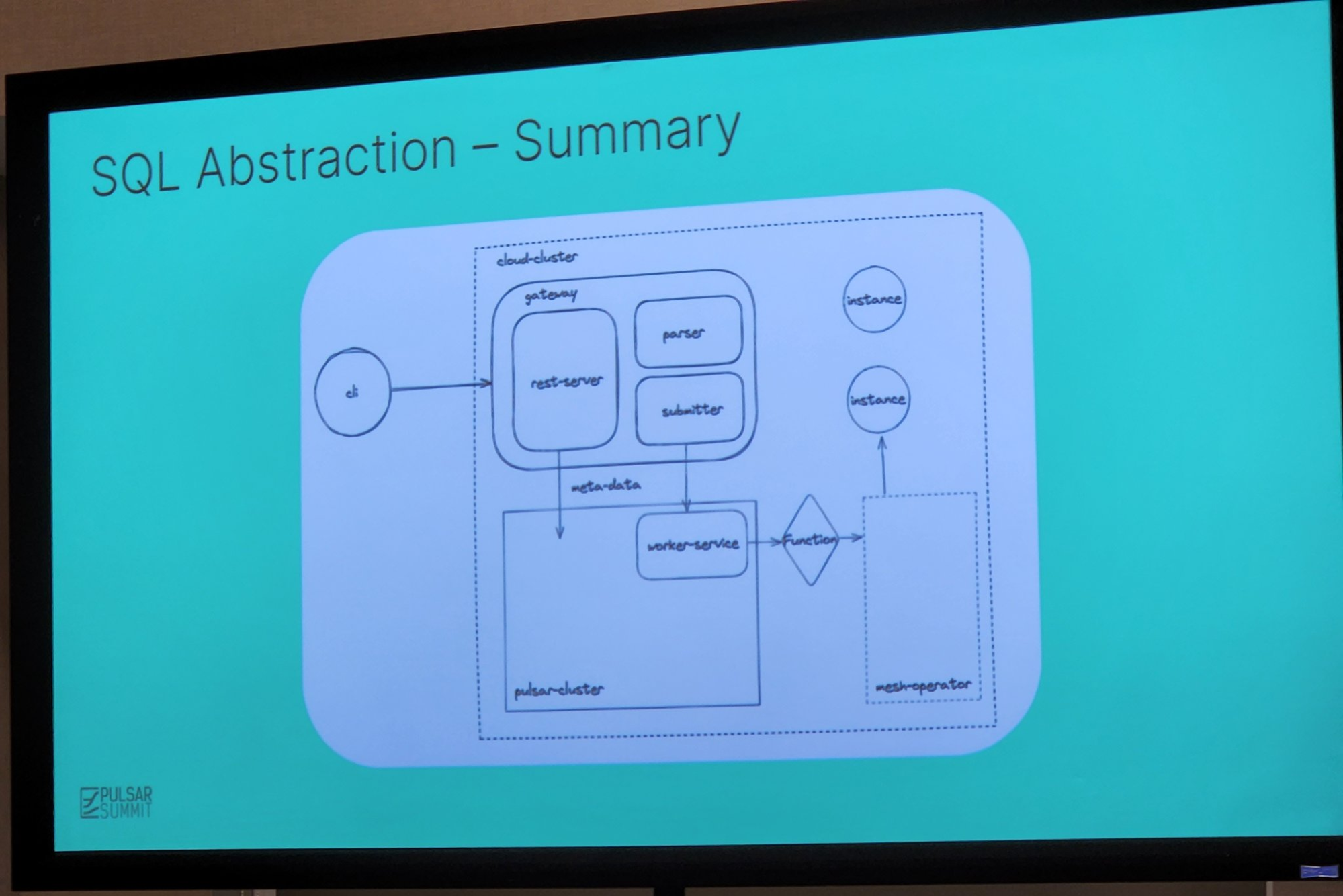
To facilitate the development cycle, Neng described the SQL Abstraction they devised. This abstraction was a simplified way to develop Pulsar Functions pipelines; it was not an interactive tool just to run ad-hoc queries. The SQL Abstraction consisted of a gateway, runner and CLI component. The gateway consisted of a parser-to-runner component, and a REST API server to CLI component.
More to Come!
There was a lot more than I could cover to each of these talks. And there were a lot more talks than I could personally cover. I’m looking forward to seeing the full videos posted online to be able to catch up on all the sessions I missed, and to see if I missed anything in the sessions I did attend.
Also, I’ll come back at another time to blogify the session I presented myself, which was on Distributed Database Design Decisions to Support High Performance Event Streaming. For now, I just wish to congratulate all the Pulsar Summit 2022 presenters, and the event staff and the organizers at StreamNative who put on such a great event.
And for anyone looking for other cool events to attend, let me remind you that ScyllaDB is sponsoring the upcoming P99 CONF, a free online virtual event October 19th and 20th, all about high performance distributed systems. We’ll have talks on observability and performance tuning, event streaming and distributed databases, and advanced programming and Linux operating system methods. Much like Pulsar Summit, it’s an event you won’t want to miss. Register today!



