At ScyllaDB Summit 2021, we were joined by two members of the engineering team at Grab, Chao Wang and Arun Sandu, who generously provided their insights into the ways that Grab is using ScyllaDB to solve multiple business challenges at scale.
Chao works on Grab’s Trust team, where he is helping to build out a machine learning-driven fraud detection platform. Arun works on design, automation, and cloud operations for Grab’s NoSQL datastores.
The Grab platform is one of Southeast Asia’s largest, providing an all-in-one app used daily by tens of millions of people to shop, hail rides, make payments, and order food. In just eight years, Grab has evolved to become the region’s number one consumer, transportation, and FinTech platform. Today, Grab covers 339 cities in 8 countries and 187 million active users.
According to Chao, Grab’s mission is to “drive Southeast Asia forward by improving the quality of life for everyone.” As such, Grab offers a range of everyday services. The diversity of Grab’s services presents the engineering team with a unique challenge: how to build a platform-wide solution that supports multiple business verticals with the lowest engineering costs and shortest possible development cycles.
Grab’s Counter Service
Chao’s team’s specific mission is to protect users and to enhance trust across the Grab ecosystem. To support this mission, the team operates a real-time pipeline, complemented by online data processing, for conducting checks and for calculating “verdicts.” Real-time services include login, payment card management, bookings, and driver payouts. Periodic data processing is used to calculate a range of fraud scores, including for drivers, passengers, bookings and card fraud. Real-time counters are used for calculating real-time verdicts, some of which involve policy enforcement, while others involve velocity rules or verdicts based on past behavior.
The Grab platform relies on a variety of counters to detect fraud, identity, and safety risks. Chao provided an example of the way that a counter might be used to identify a potentially fraudulent pattern of transactions. “For example, say passenger A and driver B together take more than 10 rides in the past hour, then that is flagged as suspicious, and actions would be taken against future rides.”
Chao took a moment to explain how Grab’s approach differs from conventional big data processing and big data analytics. Chao pointed out that these processes are typically offline, involving engineers who work on scripts. “There will be a bottleneck, so it’s not in real time, ” explains Chao. “Real time is important to us; offline processing creates a long development life cycle for production.”
According to Chao, a major challenge is scalability. “It’s a great challenge to store counters in the database and query and aggregate them in real time. When there are millions of counter keys across a long period of time, we have to find a scalable way to write and fetch keys efficiently and meet our SLA. The second reason is self-service; a counter is usually invented by the data team and then used online by engineers. It used to take two or more weeks for the whole dev iteration. If there are any changes in the middle, which happens quite often, the whole process loops again.”
The third challenge that Chao identified is manageability and extensibility, which improve the connection between real-time and offline data. With the new ScyllaDB-based solution, the platform’s users can get a view of what is stored in the counters and their performance for future analytics.
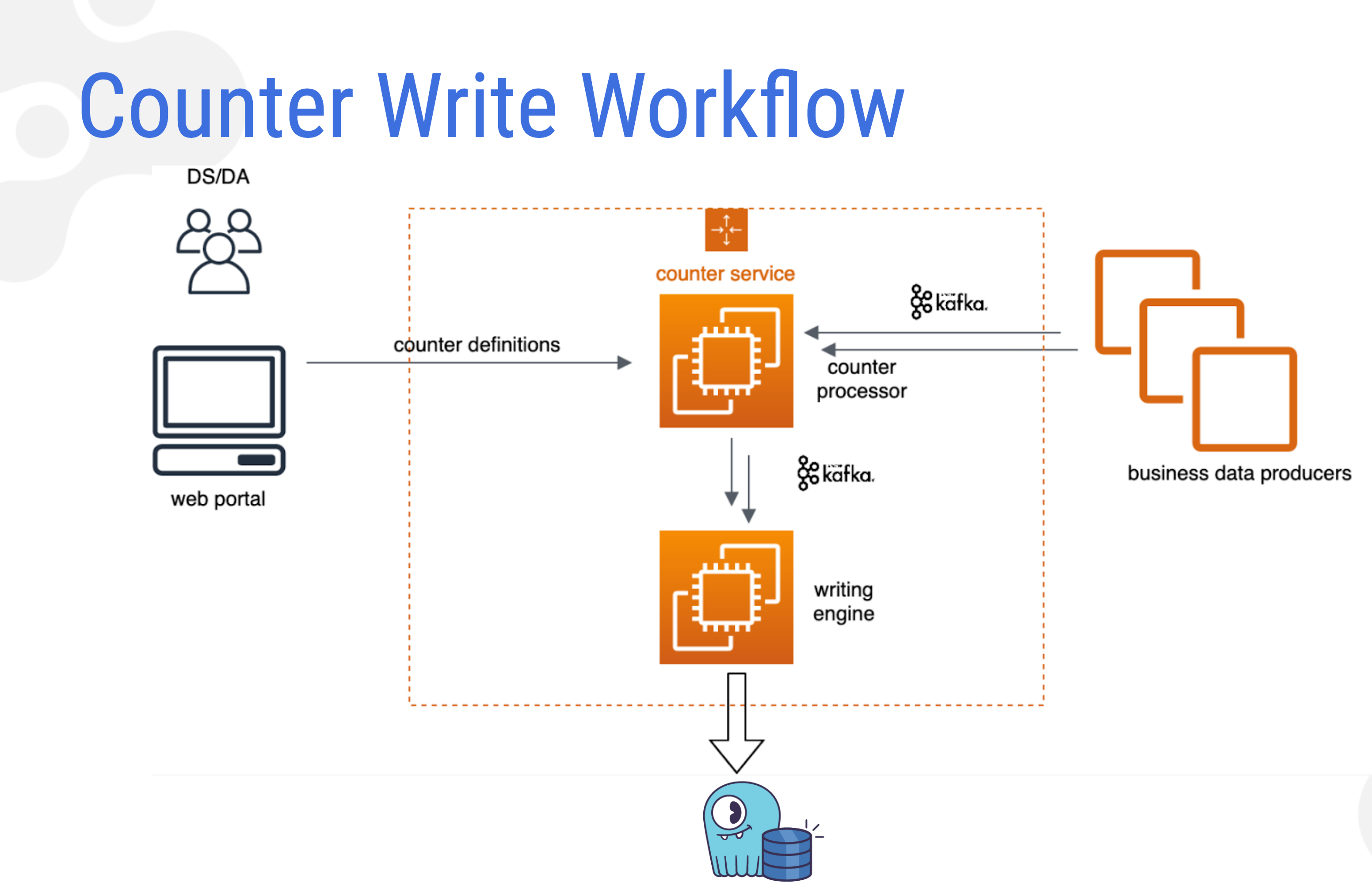
Grab’s counter write workflow, showing how they use both ScyllaDB and Apache Kafka to process counter data used for their fraud detection systems.
The diagram above shows Grab’s workflow. On the left side is the counter creation workflow. A user opens the counter creation UI and configures new counter definitions. The service monitors the new counter creation, inserts a new counter into the script process, and begins processing new counter events. The counter service monitors multiple streams, as ingress assembles actual data from online data services. The resulting rich dataset will also be available for counter creators to stream resources. The workflow means that it’s not necessary to redeploy the counter definition logic to the counter processor.
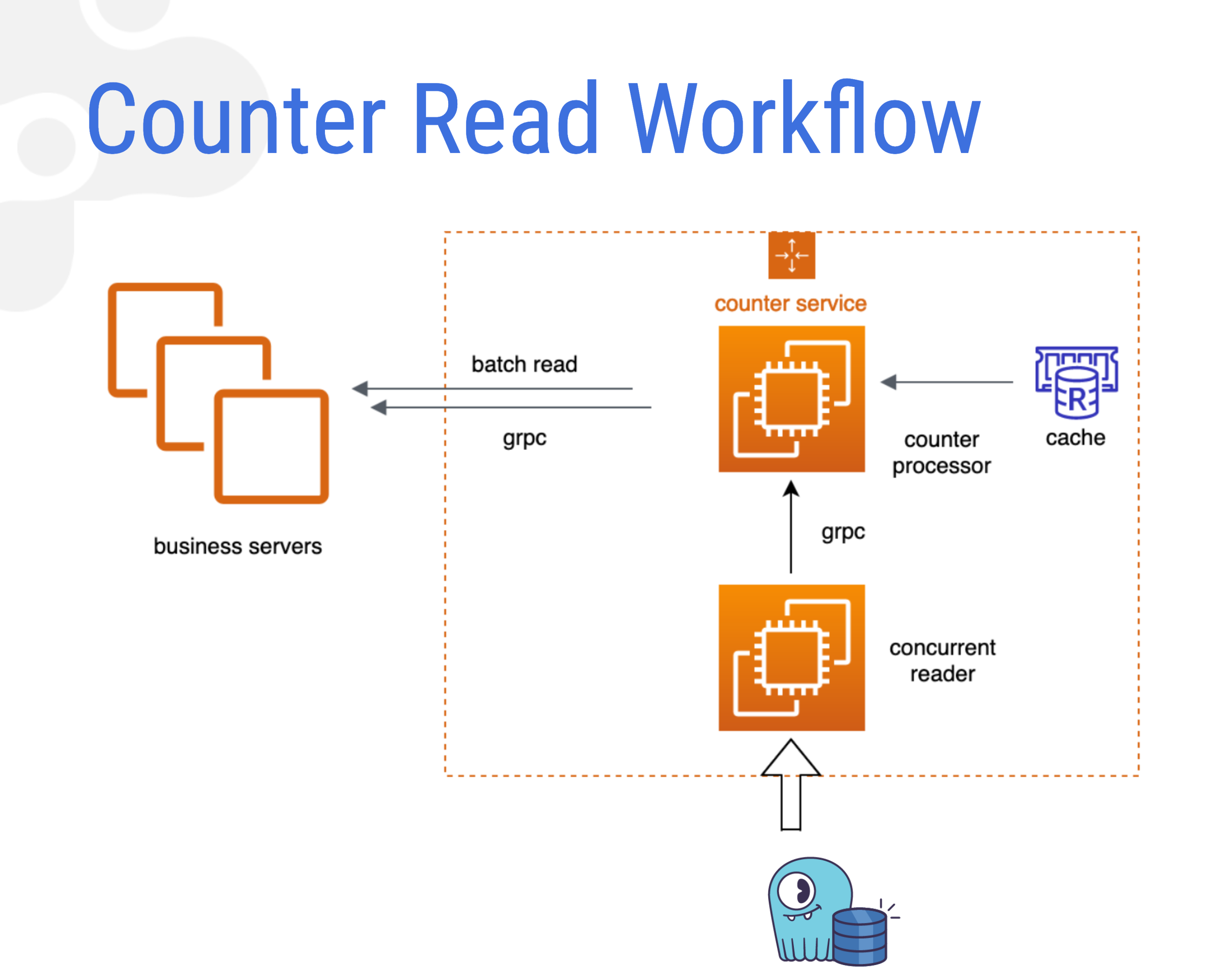
The counter read process is straightforward. Upstream services use RPC requests, and the service queries ScyllaDB concurrently.
The diagram below displays the data structure Grab uses to tackle scalability and SLA requirements. As Chao explained, “We save the aggregate value in the time window instead of the transactions. We save the aggregate values to the time buckets. So there are limited windows to aggregate for each query. We avoid doing heavy aggregations, but still keep the granularity to 15 minute intervals in a scalable response time.”
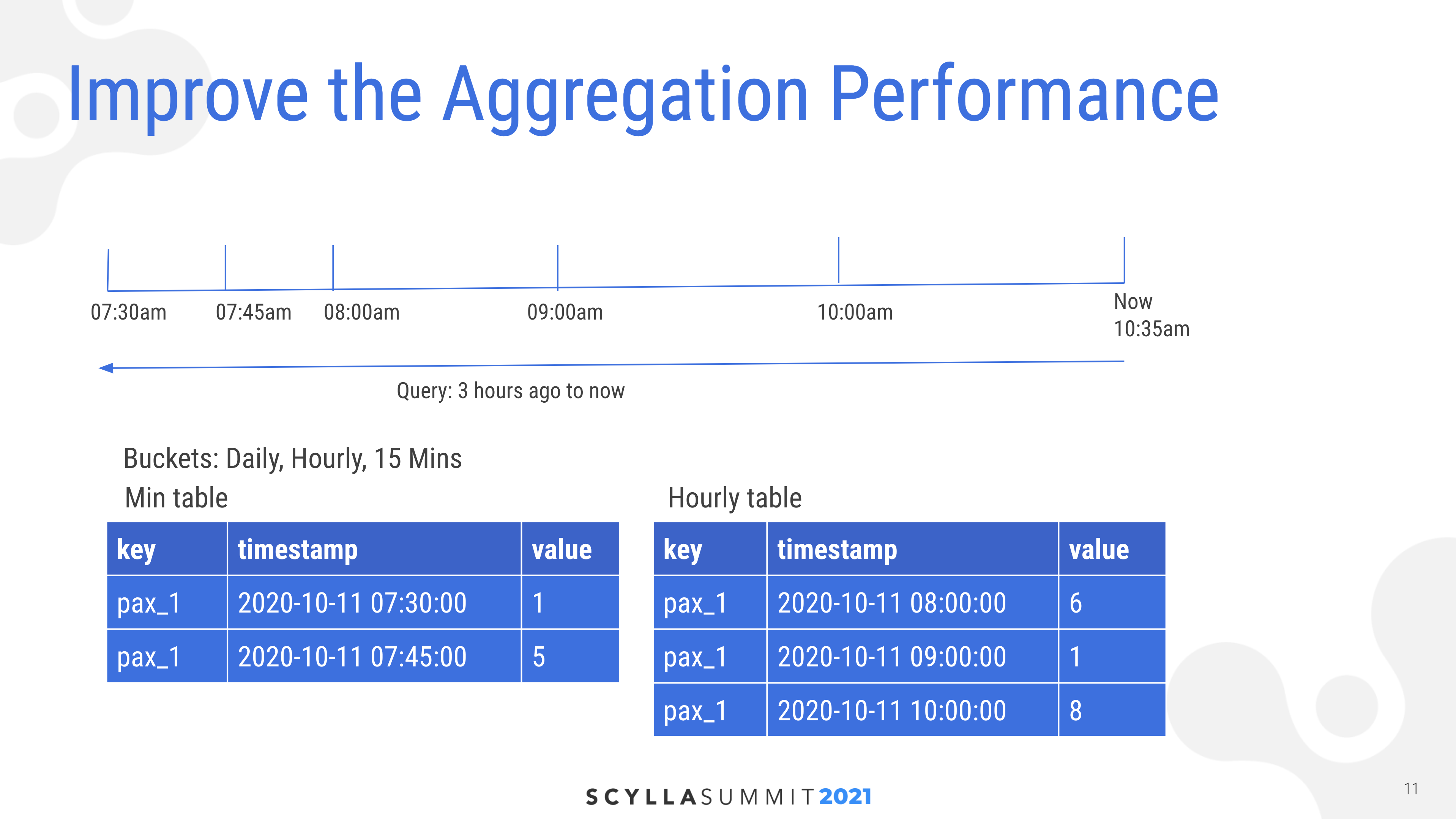
Grab’s data model, which is designed for scale and predictable performance.
Chao presented a typical query. In the use case presented, “we want to know how many rides passenger 1 has taken in the last three hours. During the writing process all packets keep receiving records simultaneously, so we can easily take those records out of the 15 minutes and hour tables and then add values as the results.”
Other ScyllaDB Use Cases at Grab
With that Chao wrapped up his discussion of Grab’s trust platform and handed it off to his colleague, Arun, who presented other Grab use cases that leverage ScyllaDB as the distributed data store. Arun also spoke to some optimizations that have improved latencies and reduced costs.
Ads
To support frequency capping, Grab uses ScyllaDB to log the events that are generated when a user sees an ad, such as clicks and impressions. Grab stores all those statistics and uses them to improve ads.
Stream Processing of Time Series Data
KairosDB is a distributed time series database that uses ScyllaDB as the back-end storage for metrics data. Arun provided the diagram below to show how Grab uses ScyllaDB and KairosDB, leveraging a pipeline that reads data from Kafka and works with KairosDB ingestors to write to KairosDB, and then to ScyllaDB for stream processing.
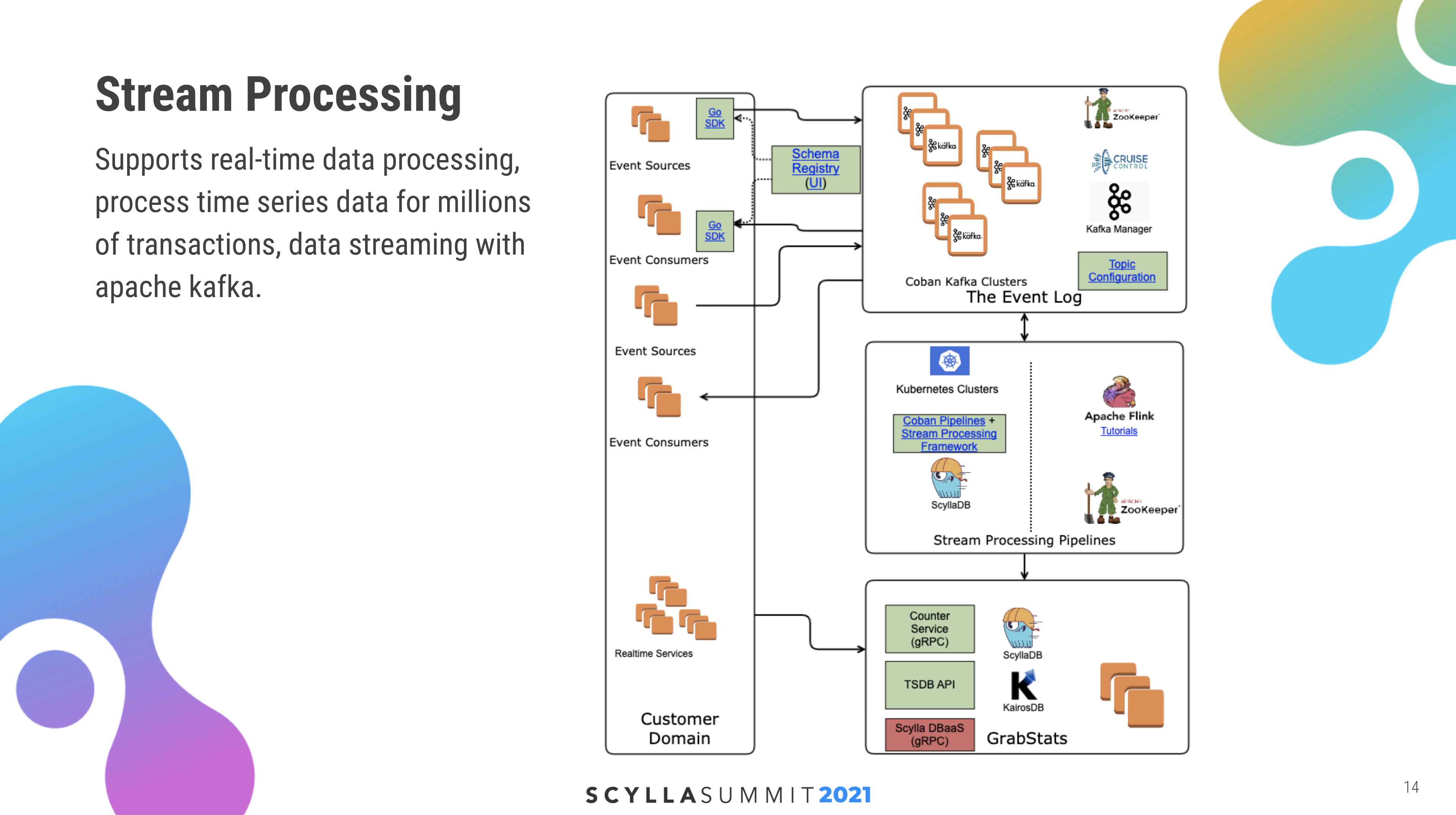
This framework is built on an event sourcing architectural pattern that supports time series data processing for millions of transactions with Apache Kafka. “We use ScyllaDB here as persistent storage to process stateful transformations such as aggregations, joins, and windowing.”
Hundreds of pipelines are created, all of which can process both stateful and stateless transformations, depending on customer requirements. The platform is currently built to scale to billions of events per day.

Many of Grab’s real time services make use of the streams’ aggregated output, which relies on the Grab Stat service to interact with ScyllaDB. Fraud detection is just one of the services that make gRPC calls to Grab Stats to interact with the database segmentation platform. This functions as an experimentation platform that is widely used across Grab for a variety of use cases, such as running hypotheses against targeted segments, issuing driver loyalty rewards or incentives, or to create, run, and publish promotions. It also performs eligibility checks on users, while applying promotions in real time.
Some other features this platform provides include ad targeting and campaigns, along with machine learning models for promotions and recommendations.
Segmentation Management
Grab provides internal users with a user interface (UI) for managing segments and to schedule jobs for segment creation. Another feature that the UI provides is the ability to perform passenger lookups within a segment.
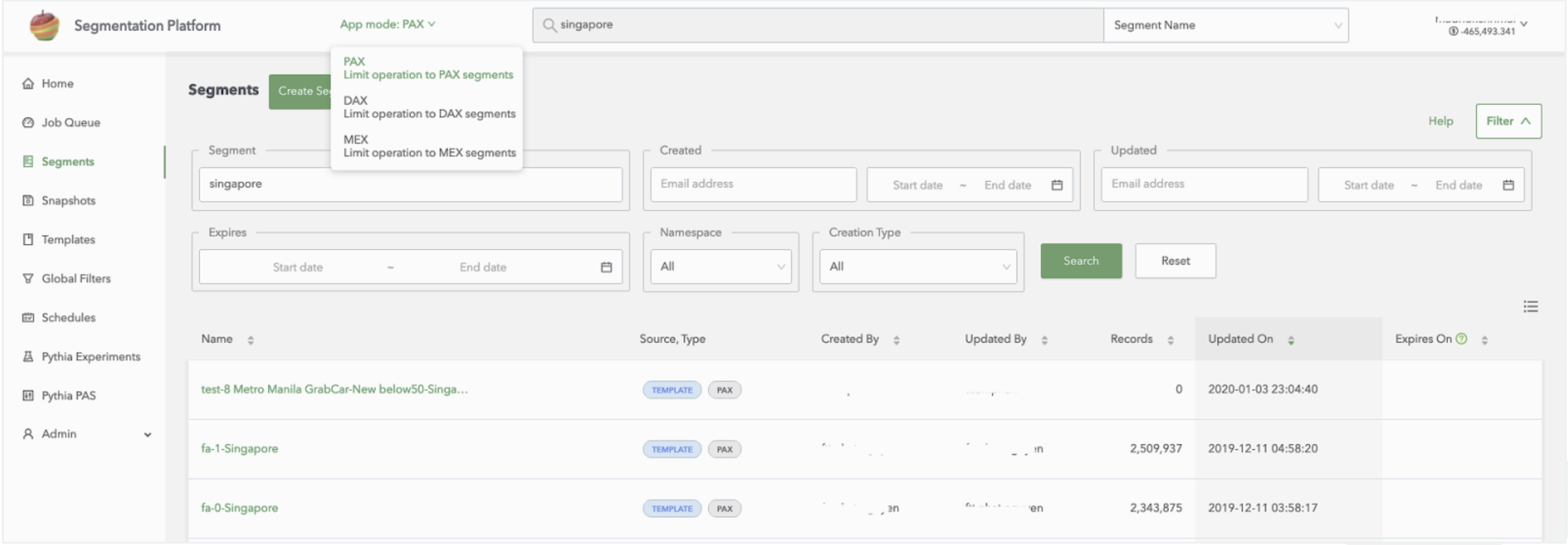
Grab segmentation platform user interface
The diagram below shows the architecture of the segmentation platform and the ways that the various components communicate. Presto acts as a query engine. Apache Spark processes the scheduled jobs. ElasticSearch is used for lookups. Finally, messages are published to Kafka, and ScyllaDB serves as the data store.
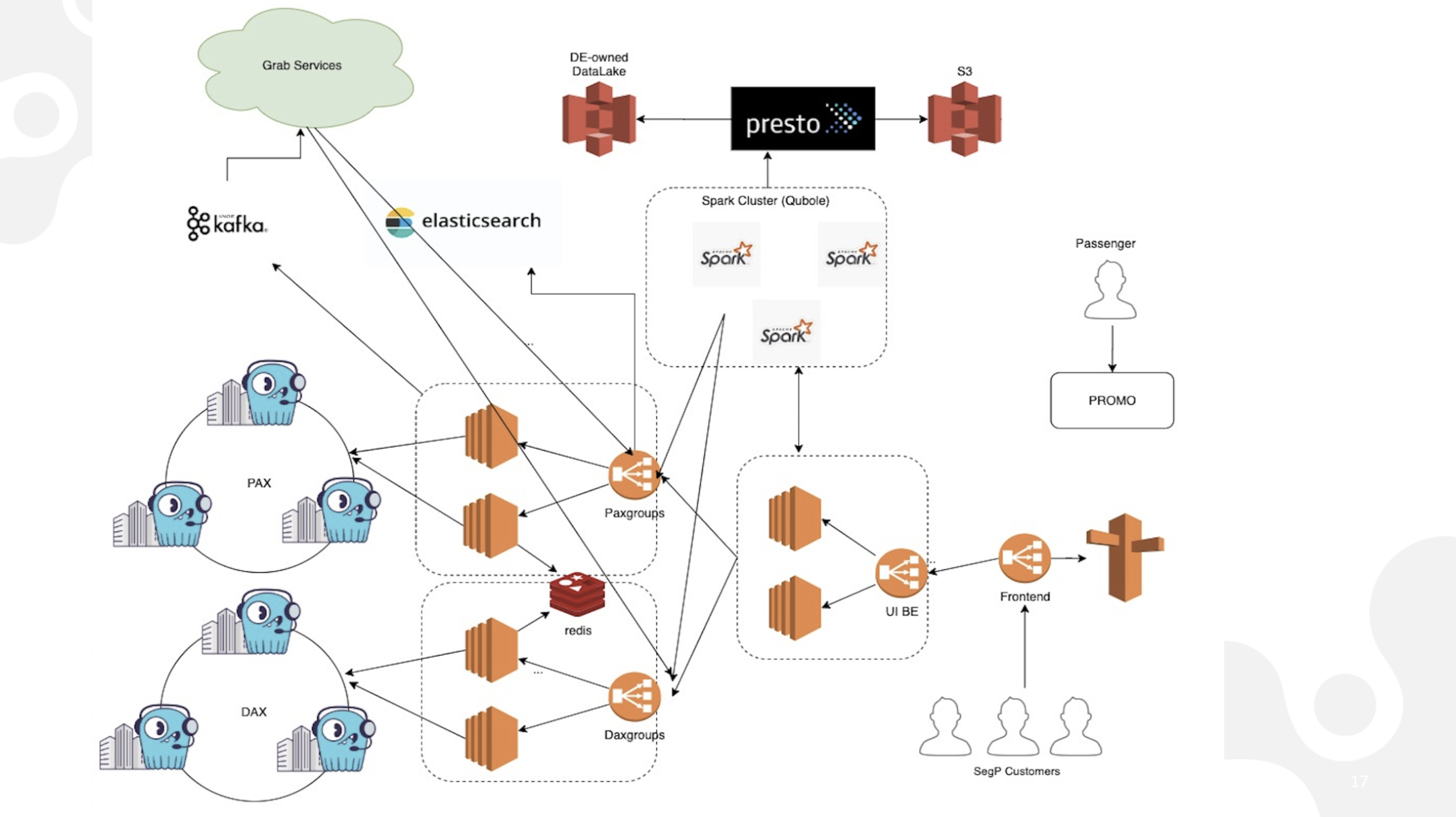
Grab’s segmentation platform architecture
Arun walked us through the architecture. “Let’s take an example of what happens when a passenger wants to book a ride using a promotion. Imagine the user logs into the app, updates location information, and applies the promotion. In the background, this action triggers a call to the service, which performs an eligibility check to make sure that the right passenger is applying the promotion. This service uses ScyllaDB as the source of truth, providing a good example on how our internal customers use the interface to create or schedule the jobs that are eventually processed by Spark and ElasticSearch.”
Optimizations
The team at Grab has also learned a great deal about optimizing their use of ScyllaDB, and shared some key learnings with the community.
- ScyllaDB Monitoring Stack — Arun noted that, following the migration from Cassandra to ScyllaDB, the team started to see latencies increasing for a subset of requests. Upon troubleshooting, the root cause turned out to be the Datadog agent process running on shard zero. The agent was hogging CPU on each ScyllaDB instance. The team switched over to Prometheus from ScyllaDB Monitoring Stack, subsequently exporting metrics to Datadog. The results were impressive. P99 read latencies were reduced from 100 milliseconds to 25 millisecond, and the error rate went from 1% down to zero.
- Managing Major Compactions — One of Grab’s use cases frequently refreshes a segment, which deletes records, leaving behind records known as ‘tombstones’ across replicas. To address this, Arun’s team scheduled a major compaction to evict expired tombstones and improve latencies. (Learn more about managing tombstones.)
- Managing Large Partitions — According to Arun, some of Grab’s segments are “really huge, with millions of passengers in them.” Rather than simply creating large partitions, Arun’s team implemented logic to dynamically create partitions, which helps to distribute data across ScyllaDB clusters without requiring large partitions. (Read more about hunting large partitions in your own clusters.)
Cost Savings
Arun moved on to discuss a few initiatives undertaken by his team to reduce costs. The team:
- Introduced time-to-live (TTL) with a default expiration, so that the majority of segments are now deleted after the TTL expiration
- Defined rate limiters for writes and reads based on the target queries per second (QPS) to avoid overloading the database
- Upgraded to new storage format (MinIO Client)
- Deleted segments no longer in use
These relatively straightforward optimizations produced significant results. As Arun pointed out “these actions actually helped us save money and reduce the cluster size and storage size by more than 50 percent.”
Discover ScyllaDB Cloud
The easiest way to take advantage of ScyllaDB’s highly available, highly scalable NoSQL database is via ScyllaDB Cloud (NoSQL DBaaS), our fully managed Database-as-a-Service (DBaaS). We manage all the deployment, uptime, and backups, leaving you to focus on your applications. To help you get started we recently published a few articles about Capacity Planning with Style using the ScyllaDB Pricing Calculator, and getting from Zero to ~2 Million Operations per Second in 5 Minutes.
It all begins with creating an account on ScyllaDB Cloud. Get started today!