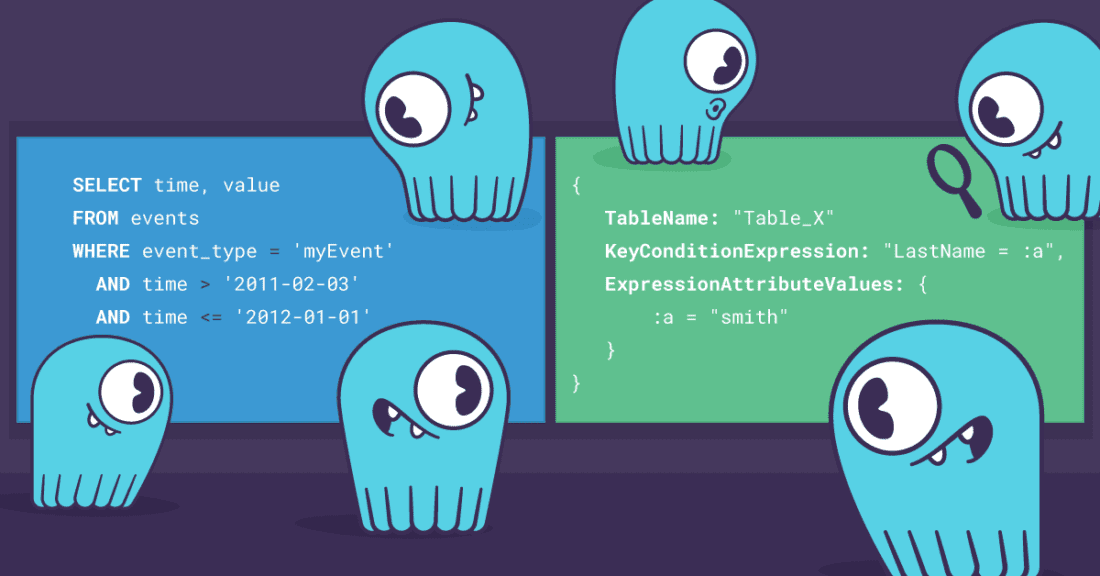
April 13, 2021 Load Balancing in ScyllaDB’s DynamoDB-Compatible API, Alternator Product, ScyllaDB Open Source, Integrations, Performance, Tutorials
January 31, 2018 ScyllaDB’s Compaction Strategies Series: Write Amplification in Leveled Compaction Featured, Tutorials, ScyllaDB Open Source
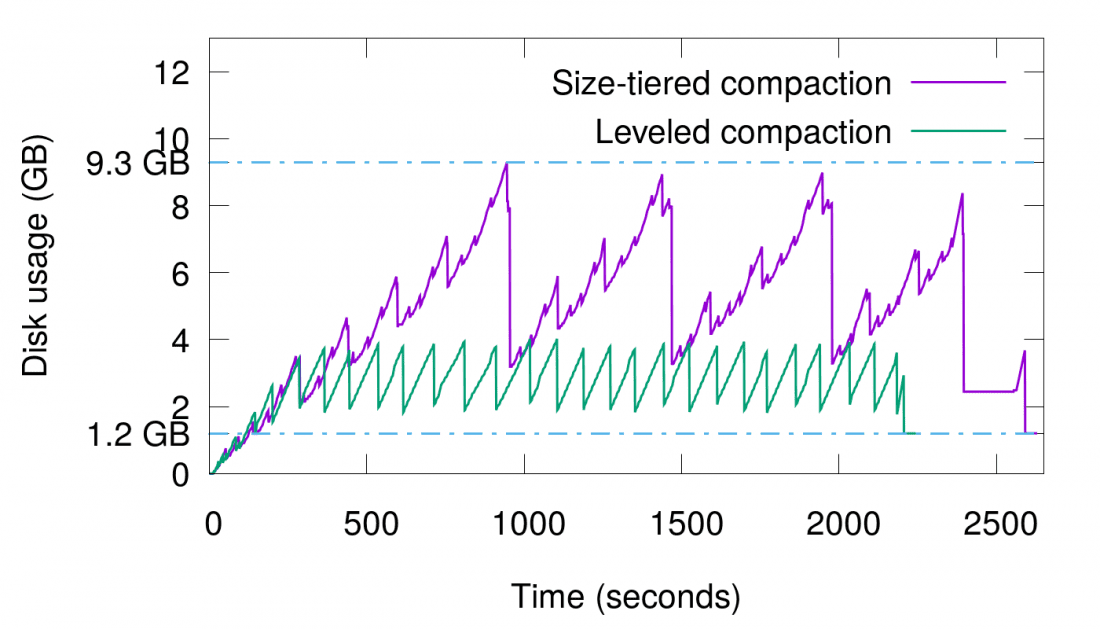
January 17, 2018 ScyllaDB’s Compaction Strategies Series: Space Amplification in Size-Tiered Compaction ScyllaDB Open Source, Featured, Tutorials