




In 2020, FullContact launched our Resolve product, backed by Cassandra. Initially, we were eager to move from our historical database HBase to Cassandra with its promises for scalability, high availability, and low latency on commodity hardware. However, we could never run our internal workloads as fast as we wanted — Cassandra didn’t seem to live up to expectations. Early on, we had a testing goal of hitting 1000 queries per second, and then soon after 10x-ing that to 10,000 queries per second through the API. We couldn’t get to that second goal due to Cassandra, even after lots of tuning.
Late last year, a small group of engineers at FullContact tried out ScyllaDB to replace Cassandra after hearing about it from one of our DevOps engineers. If you haven’t heard about ScyllaDB before, I encourage you to check it out — it’s a drop in Cassandra replacement, written in C++, promising big performance improvements.
In this blog, we explore our experience starting from a hackathon and ultimately our transition to ScyllaDB from Cassandra. The primary benchmark we use for performance testing is how many queries per second we can run through the API. While it’s helpful to measure a database by reads and writes per second, our database is only as good as our API can send its way, and vice versa.
The Problem with Cassandra
Our Resolve Cassandra cluster is relatively small: 3 instances of c5.2xlarge EC2 instances, each with 2 TB of gp2 EBS storage. This cluster is relatively inexpensive and, short of being primarily limited by the EBS volume speed limitation (250MB/s), it gave us sufficient scale to launch Resolve. Using EBS as storage also lets us increase the size of EBS volumes without needing to redeploy or rebuild the database and gain storage space. Three nodes may be sufficient for now, but if we’re running low on disk, we can add a terabyte or two to each node while running and keep the same cluster.
After several production customer-runs and some large internal batch loads began, our Cassandra Resolve tables grew from hundreds of thousands to millions and soon to over a hundred million rows. While we load-tested Cassandra before release and could sustain 1000 API calls per second from one Kubernetes pod, this was primarily an empty database or at least one with only a relatively small data set (~ a few million identifiers) max.
With both customers calling our production Resolve API and internal loads at 1000/second, we saw API speeds starting to creep up: 100ms, 200ms, and 300ms under heavy load. For us, this is too slow. And upon exceptionally heavy load for this cluster, we were seeing more and more often the dreaded:
DriverTimeoutException: Query timed out after PT2Scoming from the Cassandra Driver.
Cassandra Tuning
One of the first areas we found to gain performance had to do with Compaction Strategies — the way Cassandra manages the size and number of backing SSTables. We used the Size Tiered Compaction Strategy — the default setting, designed for “general use,” and insert heavy operations. This compaction strategy caused us to end up with single SSTables larger than several gigabytes. This means on reads, for any SSTables that get through the bloom filter, Cassandra is iterating through many extensive SSTables, reading them sequentially. Doing this at thousands of queries per second means we were quite easily able to max the EBS disk throughput, given sufficient traffic. 2 TB EBS volumes attached to an i3.2xlarge max out at a speed of ~250MB/s. From the Cassandra nodes, it was difficult to see any bottlenecks or why we saw timeouts. However, it was soon evident in the EC2 console that the EBS write throughput was pegged at 250MB/s, where memory and CPU were well below their maximums. Additionally, as we were doing large reads and writes concurrently, we have huge files being read. Still, the background compaction added additional stress on the drives by continuously bucketing SSTables into different size tables.
We ended up moving to Leveled Compaction Strategy:
alter table mytable WITH compaction = { 'class' :
'LeveledCompactionStrategy’};Then after an hour or two of Cassandra completing its shuffling data around to smaller SSTables, were we again able to handle a reasonably heavy workload.
Weeks after updating the table’s compaction strategies, Cassandra (having so many small SSTables) struggled to run as fast with heavy read operations. We realized that the database likely needed more heap to run the bloom filtering in a reasonable amount of time. Once we doubled the heap in
/opt/cassandra/env.sh:
MAX_HEAP_SIZE="8G"
HEAP_NEWSIZE="3G"Followed by a Cassandra service restart, one instance at a time, it was back to performing more closely to how it did when the cluster was smaller, up to a few thousand API calls per second.
Finally, we looked at tuning the size of the SSTables to make them even smaller than the 160MB default. In the end, we did seem to get a marginal performance boost after updating the size to something around 8MB. However, we still couldn’t get more than about 3,000 queries per second through the Cassandra database before we’d reach timeouts again. It continued to feel like we were approaching the limits of what Cassandra could do.
alter table mytable WITH compaction = { 'class' :
'LeveledCompactionStrategy’, ‘sstable_size_in_mb’ : 80 };Enter ScyllaDB
After several months of seeing our Cassandra cluster needing frequent tuning (or more tuning than we’d like), we happened to hear about ScyllaDB, the monstrously fast and scalable NoSQL database. From their website: “We reimplemented Apache Cassandra from scratch using C++ instead of Java to increase raw performance, better utilize modern multi-core servers and minimize the overhead to DevOps.”
This overview comparing ScyllaDB and Cassandra was enough to give it a shot, especially since it “provides the same CQL interface and queries, the same drivers, even the same on-disk SSTable format, but with a modern architecture.”
With ScyllaDB billing itself as a drop-in replacement for Cassandra promising MUCH better performance on the same hardware, it sounded almost too good to be true!
As we’ve explored in our previous Resolve blog, our database is primarily loaded by loading SSTables built offline using Spark on EMR. Our initial attempt to load a ScyllaDB database with the same files as our current production database left us a bit disappointed. loading all the files to a fresh ScyllaDB cluster required us to rebuild them with an older version of the Cassandra driver to force it to generate files using an older format.
After talking to the folks at ScyllaDB, we learned that it didn’t support Cassandra’s latest MD file format. However, you can rename the .md files to .mc, and this will supposedly allow these files to be read by ScyllaDB. [Editor’s note: ScyllaDB fully supports the “MD” SSTable format as of ScyllaDB Open Source 4.3.]
Once we were able to get SSTables loaded, we ran into another performance issue of starting the database in a reasonable amount of time. On Cassandra, when you copy files to each node in the cluster and start it, the database starts up within a few seconds. In ScyllaDB, after copying files and restarting the ScyllaDB service, it would take hours for larger tables to be re-compacted, shuffled, and ready to go, even though our replication factor was 3, on a 3 node cluster. So in copying all the files to each cluster, our thinking was data shouldn’t need to be transformed at all.
Once data was loaded, we were able to properly load test our APIs finally! And guess what? We were finally able to hit 10,000 queries per second relatively easily!
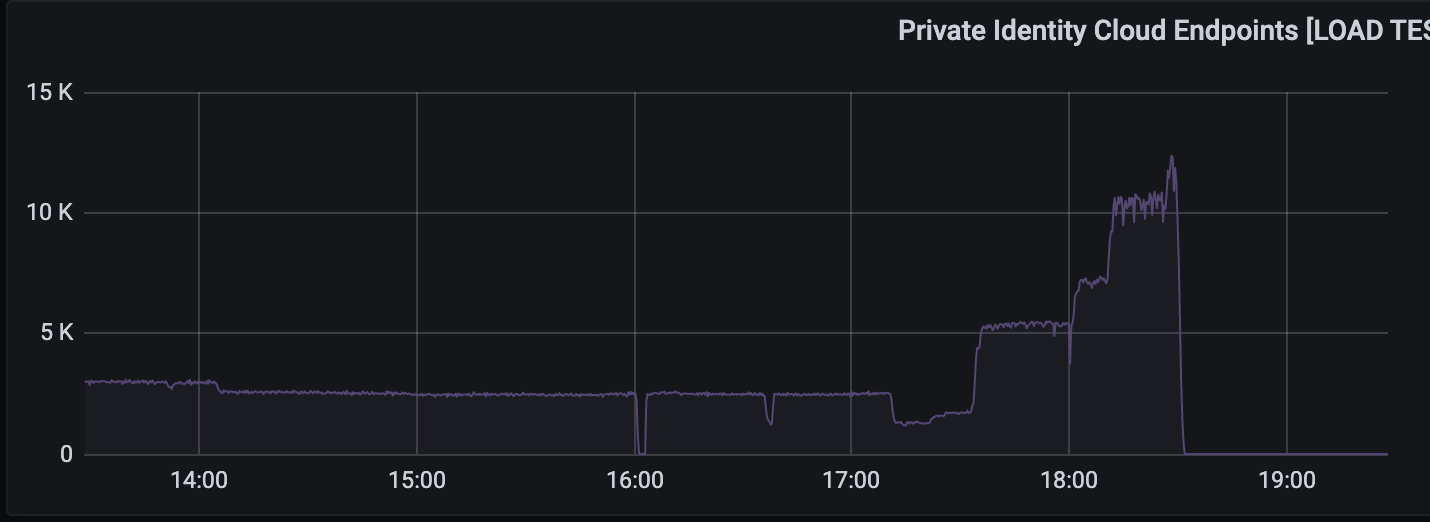
Grafana dashboard showing our previous maximum from 13:30 – 17:30 running around 3,000 queries/second. We were able to hit 5,000, 7,500, and over 10,000 queries per second with a loaded ScyllaDB cluster.
We’ve been very pleased with ScyllaDB’s performance out-of-the-box, being able to achieve double our goal set earlier last year of 10,000 queries per second, peaking at over 20,000 requests per second, all while keeping our 98th percentile under 50ms! And best of all — this is all out-of-the-box performance! No JVM or other tuning needs required! (The brief blips near 17:52, 17,55, and 17:56 are due to our load generator changing Kafka partitioning assignments as more load consumers are added).
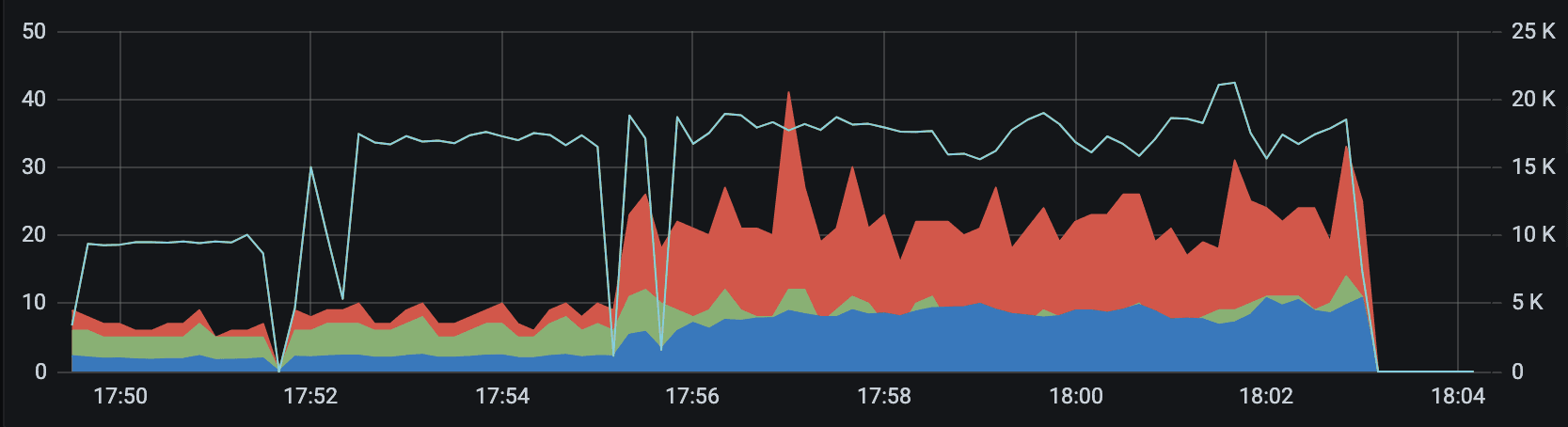
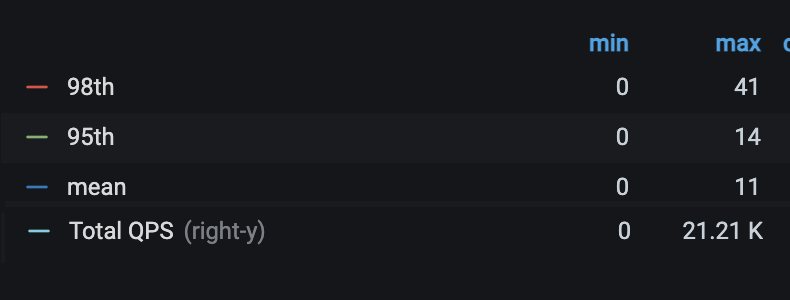
In addition to the custom dashboards we have from the API point of view, ScyllaDB conveniently ships Prometheus metric support and lets us install their Grafana dashboards easily to monitor our clusters with minimal effort.
OS metrics dashboard from ScyllaDB:
ScyllaDB Advanced Dashboard:
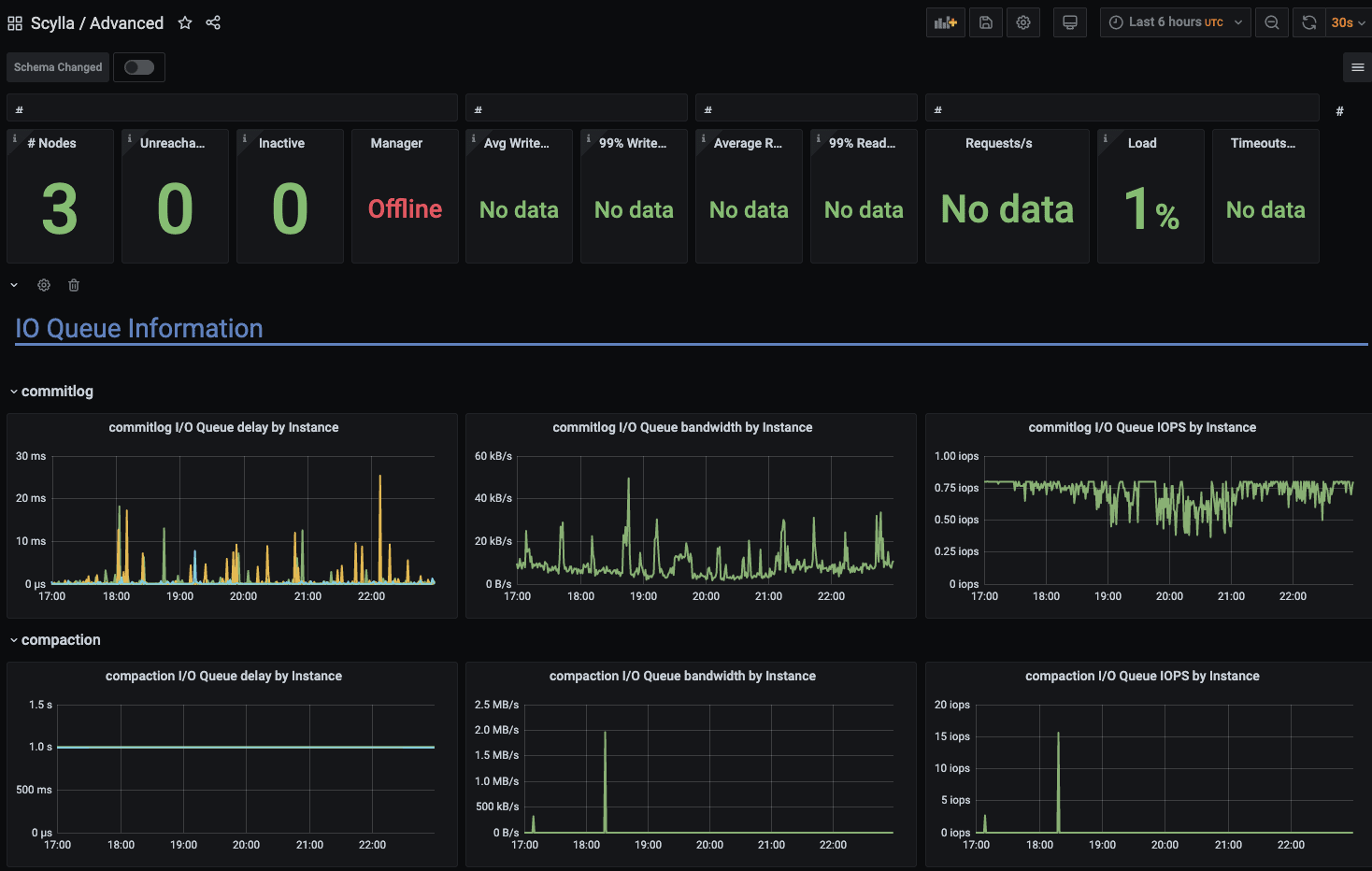
Offline SSTables to Cassandra Streaming
After doing some quick math factoring in ScyllaDB’s need to recompact and reshuffle all your data loaded from offline SSTables, we realized reworking the database building, replacing it with streaming inserts straight into Cassandra would be faster using the spark-cassandra-connector.
In reality, rebuilding a database offline isn’t the primary use case that’s run regularly. Still, it is a useful tool for large schema changes and large internal data changes. This, combined with the fact that our SSTable build ultimately has SSTables being written to a single executor, we’ve since abandoned the offline SSTable build process.
We’ve updated our Airflow DAG to stream directly to a fresh ScyllaDB cluster:

Version 1 of our Database Rebuild process, building SSTables offline.
Updated version 2 looks very similar, but it streams data directly to ScyllaDB:

Conveniently the code is pretty straightforward as well:
We create a spark config and session:
val sparkConf = super.createSparkConfig()
.set("spark.cassandra.connection.host",
cassandraHosts)
// any other settings we need/want to set,
consistency level, throughput limits, etc.
val session =
SparkSession.builder().config(sparkConf).getOrCreate()
val records = session.read
.parquet(inputPath)
.as[ResolveRecord]
.cache()2. For each table we need to populate, we can map to a case class matching the table schema and saving as the correct table name and keyspace:
records
// map to a row
.map(row => TableCaseClass(id1, id2, ….))
.toDF()
.format("org.apache.spark.sql.cassandra")
.options(Map("keyspace" -> keyspace, "table" ->
"mappingtable"))
.mode(SaveMode.Append)
// stream to scylla
.save()With some trial and error, we have found the sweet spot of the numbers and size of EMR EC2 nodes: for our data sets, running an 8 node c5.large was able to keep the load as fast as the EBS drives could handle while not running into more timeout issues.
Cassandra and ScyllaDB Performance Comparison
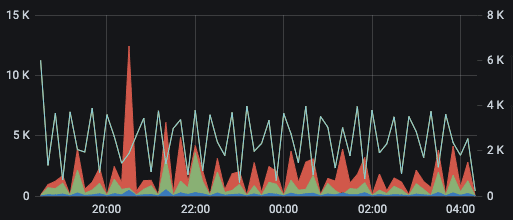 Our Cassandra cluster under heavy load
Our Cassandra cluster under heavy load
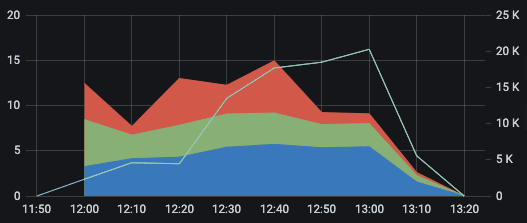 Our ScyllaDB cluster on the same hardware, with the same type of traffic
Our ScyllaDB cluster on the same hardware, with the same type of traffic
The top graph shows queries per second (white line; right Y-axis) we were able to push through our Cassandra cluster before we encountered timeout issues with the API speed measured at the mean, 95th, and 98th percentiles, (blue, green, and red, respectively; left-Y axis). You can see we could push through about 7 times the number of queries per second while dropping the 98th percentile latency from around 2 seconds to 15 milliseconds!
Next Steps
As our data continues to grow, we are continuing to look for efficiencies around data loading. A few areas we are currently evaluating:
- Using ScyllaDB Migrator to load Parquet straight to ScyllaDB, using ScyllaDB’s partition aware driver
- Exploring i3 class EC2 nodes
- Network efficiencies with batching rows and compression, on the spark side
- Exploring more, smaller instances for cluster setup
This article originally appeared on the FullContact website here and is republished with their permission. We encourage others who would like to share their ScyllaDB success stories to contact us. Or, if you have questions, feel free to join our user community on Slack.





