




At ScyllaDB, our development team is all about performance with improved latency and throughput. Our speakers at our recent ScyllaDB Summit provided many tips and tricks to make ScyllaDB’s superior latency and performance even better.
ScyllaDB’s VP of R&D, Schlomi Livne, added to the growing repertoire of these tips with his talk Planning your queries for maximum performance. In it, he outlined some of the how and why of ScyllaDB performance, and concluded with seven rules to optimize your queries.
Prior to joining ScyllaDB, Shlomi headed up a platform team that was later acquired by Oracle. Leading up to his work at ScyllaDB, he enjoyed a keen interest and focus on performance and integration in large-scale systems.
Shlomi’s talk kicked off with a quick review of commonalities between ScyllaDB and Apache Cassandra, before diving deeper into how queries were executed per shard. This provided the background for understanding how the seven rules worked.
7 Rules for Planning Your Queries for Maximum Performance
What specific steps can you take to optimize query performance?
Rule #1: Use Prepared Statements
Prepared statements help you avoid repetitive work and optimize the amount of work that the coordinator must do to preprocess a query. Also, prepared statements make the client direct the query to a coordinator, which is a replica.
Tip: If you want to adapt your code to better performance, with new releases, use prepared statements.
Rule #2: Use Paging
Paging is a way to return a lot of data in manageable chunks. What if I have a query that returns 1 million rows? With paging disabled, the coordinator is forced to prepare a single result that holds all the data and returns it. This can have an obvious performance impact.
Tip: Paging is enabled by default. Do not disable it.
Rule #3: Use Correct Page Size
Drivers enable paging with a default page size of 5000 rows. Does this number make sense? That depends on the row size. Results of a performance test indicated that with wider rows, a 5k-row page size was no longer the magic number for optimal performance, as query duration in the tests nearly doubled on Apache Cassandra.

Note however that ScyllaDB caps the amount of memory it will use for a page, so even if the rows are massive, ScyllaDB will return only a subset of data that fits within ~1MB.
Tip: Don’t use a small page size that can cause issues.
Rule #4: Be Wary of Multi-Partition CQL on IN Queries
CQL allows you to do a select on IN queries, on which you cannot specify partition- or row keys.
When you specify multiple partitions, the coordinator will receive a query (even if you’re using prepared statements) where it will not be able to answer with all results from each dataset. It will need to split it up and send the request to other replicas.
Tip: If you’re latency sensitive, and querying multiple partitions, on the client side, split the query into single-partition queries, send the queries in parallel, and aggregate the results.
Rule #5: Be Wary of Single-Partition CQL on IN Queries
Should I split my CQL IN query?
Tests showed that depending on how wide your rows are, splitting a single-partition CQL IN query into parallel CQL queries may provide better latency and throughput.
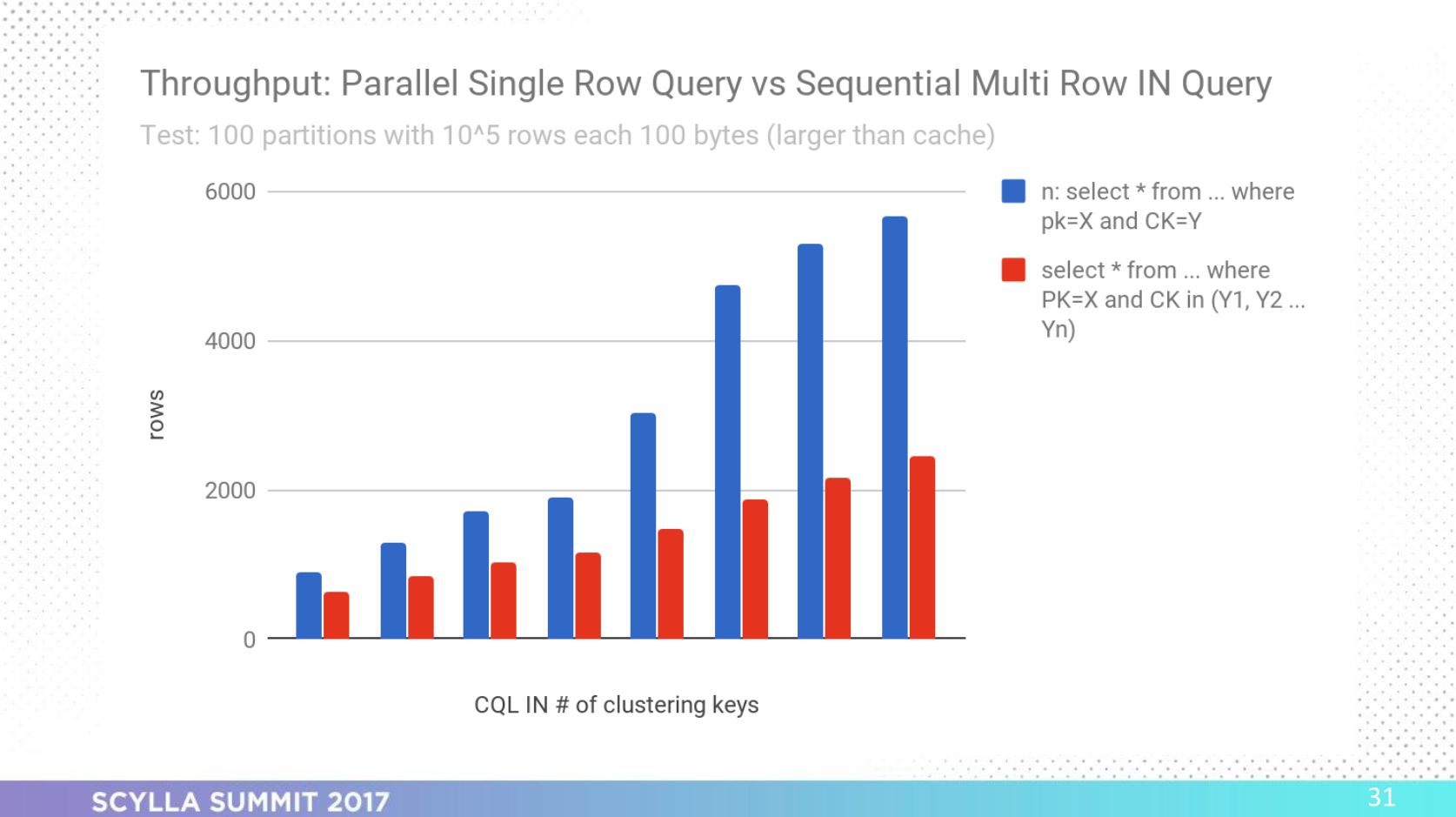
Tip: Deciding whether or not to split your CQL IN query depends on how wide your rows are.
Rule #6: There’s a Faster Way to Do Full Scans
Is there a faster way to do full scans than splitting your ranges into subranges and running “enough” subranges in parallel? Yes there is.
Tip 1: Using the token ownership of nodes in the ring, you can select ranges of tokens. Once a “range” has been processed, the next one can be selected based on ownership in the ring.
Tip 2: Even better, you can use the “sharding” information and aim ranges based on shards in a machine – this way, all cores are executing requests in parallel.
Rule #7: Use the Tools
Tip: To troubleshoot, debug, and benchmark ScyllaDB query latency and performance, you can use probabilistic tracing, slow query tracing, wireshark, or even CQL Tracing, and client-side tracing.
Want more details? Watch the video above or view the slides below.
Want to try out ScyllaDB? See our download page to learn how to run ScyllaDB on AWS, install it locally in a Virtual Machine, or run it in Docker.




