May 27, 2021 Zero to ~2M OPS in 5 Minutes on ScyllaDB Cloud Tutorials, Performance, ScyllaDB Cloud, Product
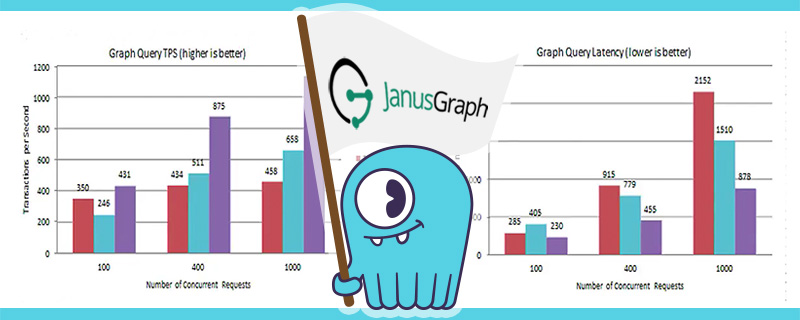
December 21, 2017 Performance Evaluation: ScyllaDB as a Database Backend for JanusGraph Performance, Integrations, Featured, ScyllaDB Open Source, Tutorials
December 12, 2017 A Year in the Life of mParticle using ScyllaDB for its Mission-Critical Functionality User Stories, ScyllaDB Open Source, Featured
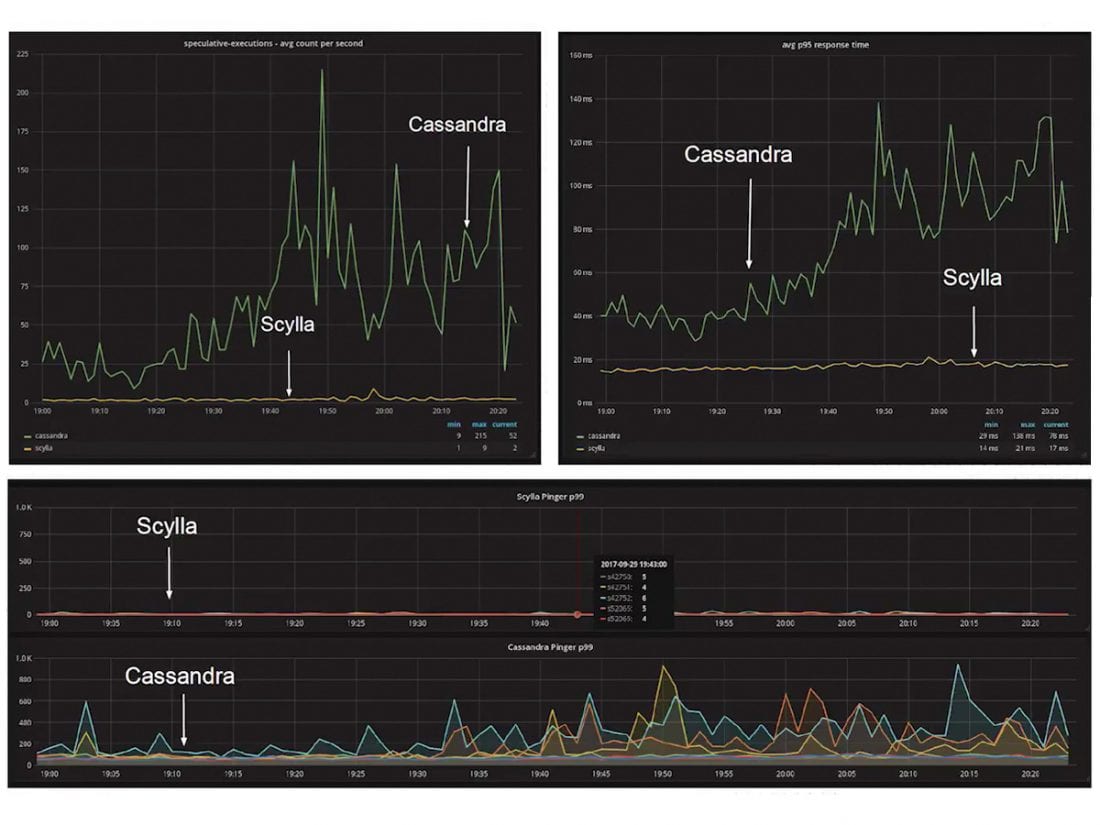
November 22, 2017 How Allegro Group Saves Latency and Money With ScyllaDB User Stories, ScyllaDB Open Source, Featured
November 17, 2017 7 Rules for Planning Your Queries for Maximum Performance ScyllaDB Open Source, Featured, Tutorials, Performance
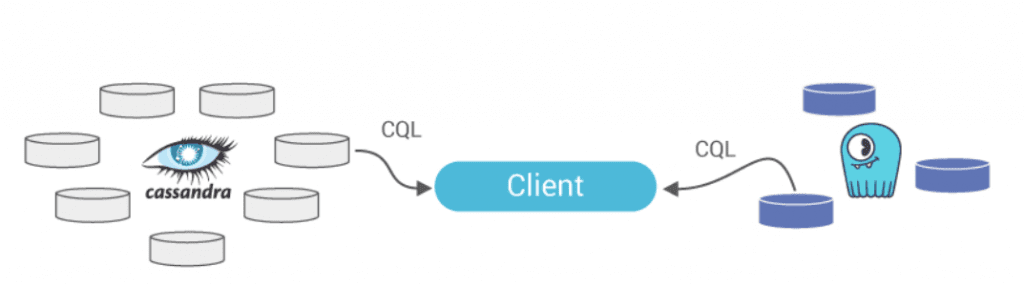
November 13, 2017 New Docs: 4 Phases to Migrate from Apache Cassandra to ScyllaDB ScyllaDB Open Source, Featured, Tutorials