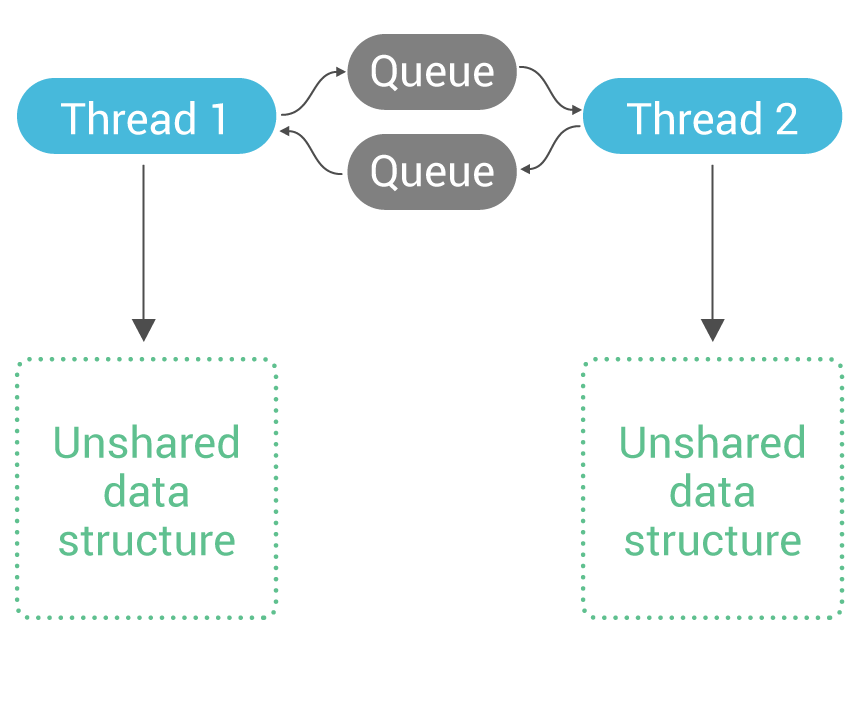
February 15, 2018 Adventures with Memory Barriers and Seastar on Linux Featured, Tutorials, Seastar, ScyllaDB Open Source, Engineering
January 17, 2018 ScyllaDB’s Compaction Strategies Series: Space Amplification in Size-Tiered Compaction ScyllaDB Open Source, Tutorials, Featured
December 28, 2017 How to Ruin Your Performance by Choosing the Wrong Compaction Strategy Performance, ScyllaDB Open Source, Tutorials, Featured
December 13, 2017 Stop Wasting ScyllaDB’s CPU Time by Not Being Prepared Tutorials, Featured, ScyllaDB Open Source
November 17, 2017 7 Rules for Planning Your Queries for Maximum Performance Tutorials, ScyllaDB Open Source, Performance, Featured
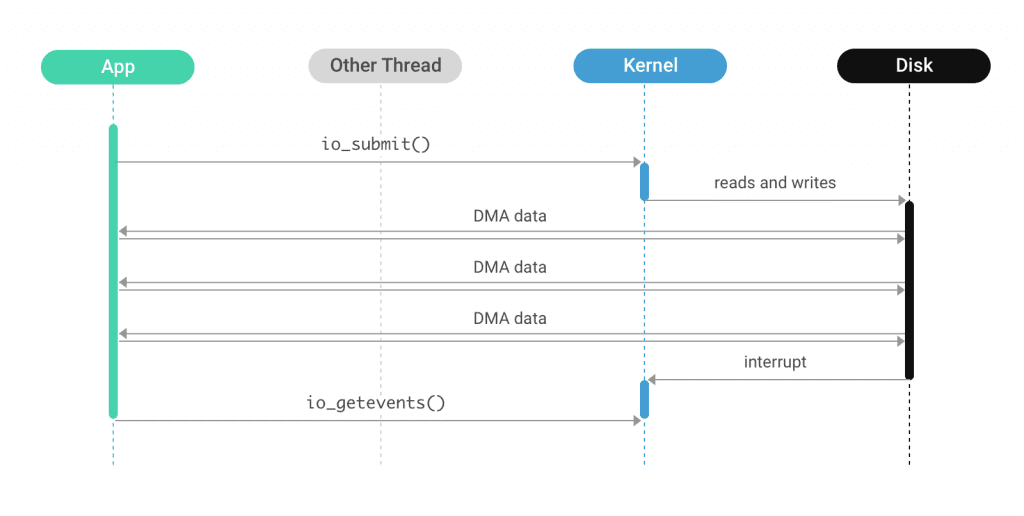
October 5, 2017 Different I/O Access Methods for Linux, What We Chose for ScyllaDB, and Why Engineering
July 31, 2017 7 Reasons Not to Put a Cache in Front of Your Database ScyllaDB Open Source, Tutorials, Featured