ScyllaDB is the Database Built for High Availability
ScyllaDB is designed to be highly available, meaning that, short of a complete systemic global outage, the database should remain up and available for your mission-critical applications.
Peer-to-Peer Architecture
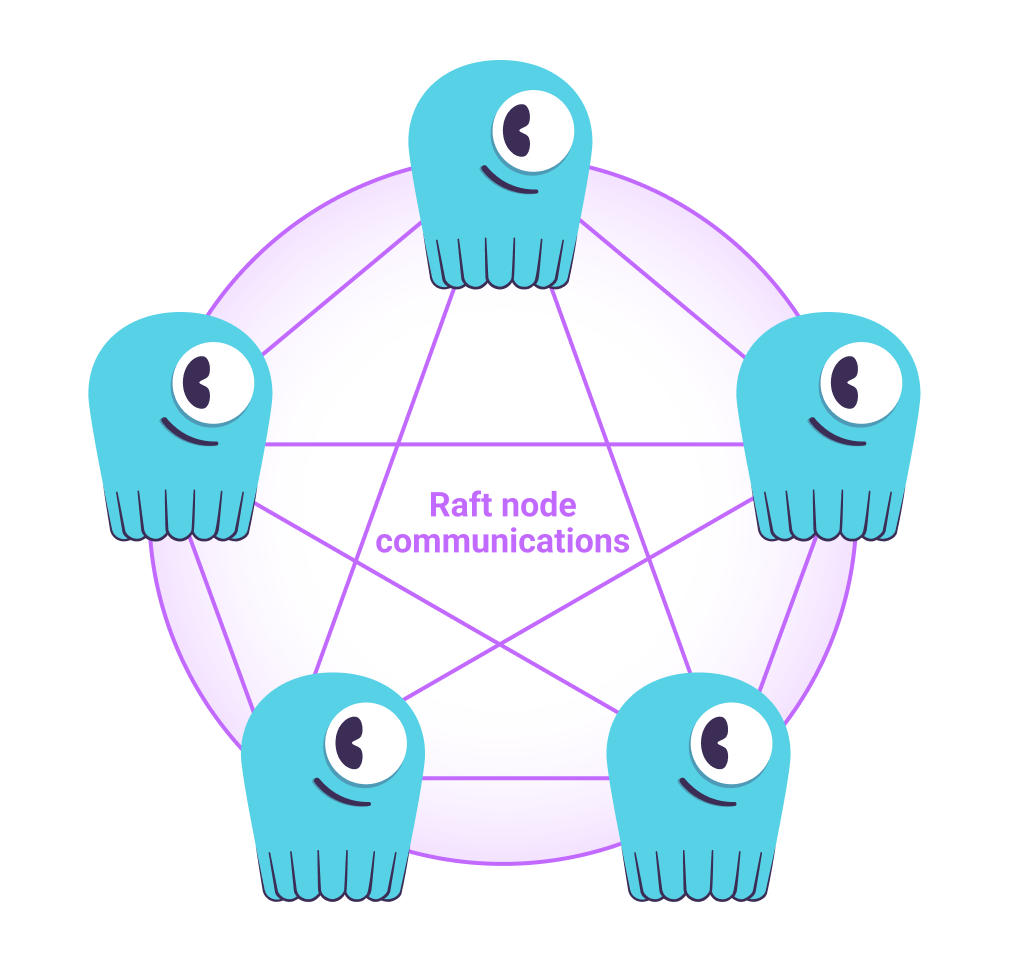
ScyllaDB has a symmetric, peer-to-peer architecture. There are no leaders or followers traditionally found in legacy NoSQL and SQL architectures (primaries with replicas), and the nodes remain identical within a zone, region, or globally, without additional external components to support replication. Until ScyllaDB 5.4 and 2024.1, ScyllaDB used the gossip protocol to discover peer nodes, establish the cluster, and communicate health and node status.
However, the Raft consensus algorithm has replaced the gossip protocol for topology changes, such as adding or removing a node or, in case of an unexpected node outage, providing resiliency, strong consistency, and parallel topology changes to a ScyllaDB cluster. Raft also replaces gossip protocol for Data Definition Language (DDL) schema changes.
Raft provides distributed, strongly consistent, replicated logs of all node states across all nodes without a performance penalty. It implements consensus by electing a distinguished leader and then giving the leader complete responsibility for managing the replicated log. The leader accepts log entries from clients, replicates them on other servers, and tells servers when it is safe to apply them to their state machines.
Automatic Data Replication
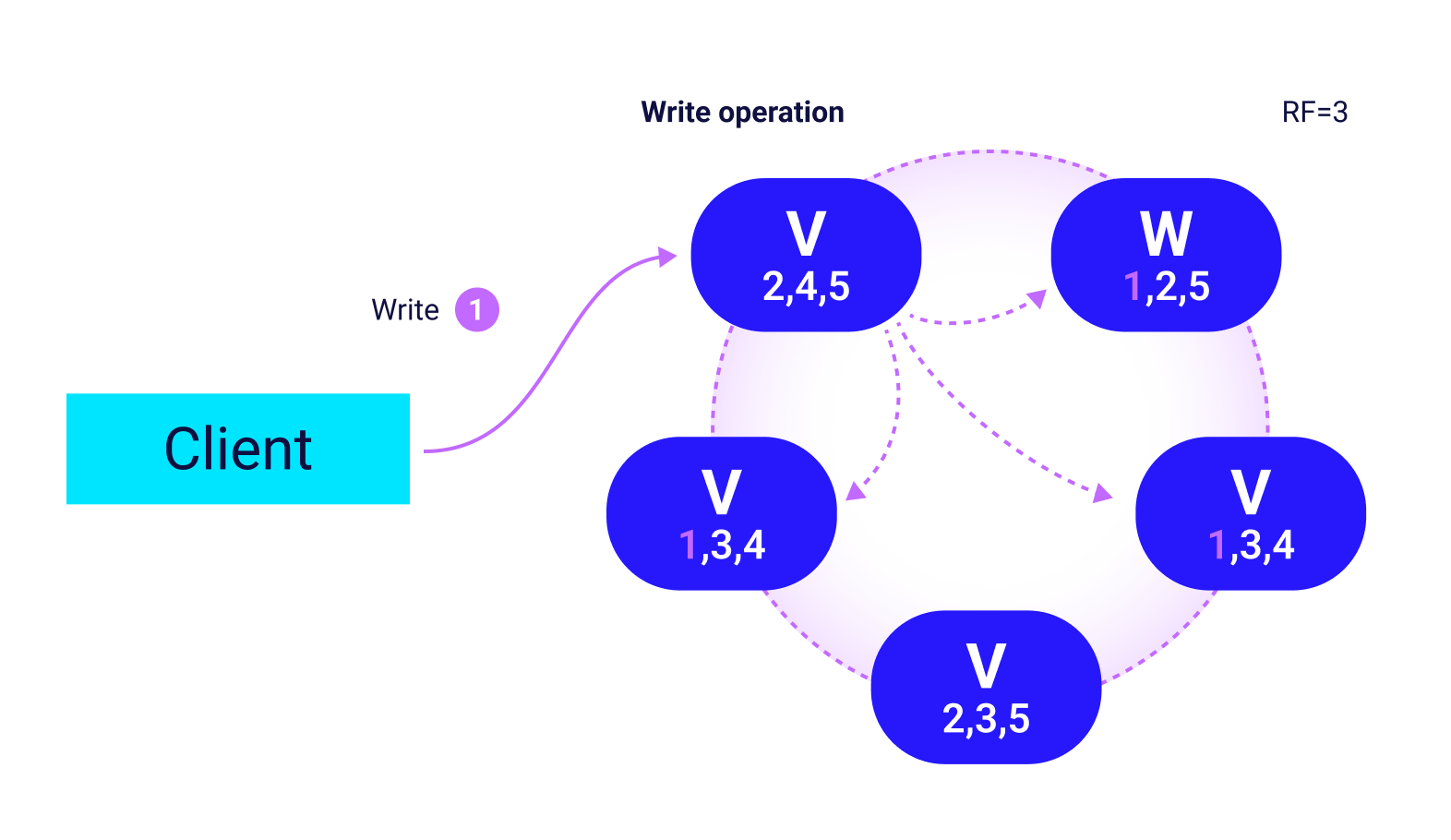
ScyllaDB allows users to set a replication factor (RF), meaning that multiple copies of the same data can be stored on multiple nodes across the cluster. In this way, even if a node is lost, the data still resides somewhere in the cluster.
In this write operation, an update to partition 1, the data is passed along from the coordinator node, V, to the three nodes where the data resides: W, X and Z.
Setting a replication factor of three (3) is sufficient for many high-availability use cases. In such cases, even if two of the three copies of the data are unavailable, the data will reside somewhere in the cluster.
With a properly set replication factor, zero downtime is achievable. Users can determine their own replication factor based on their use case. There are times when a replication factor of two may be sufficient and times when a replication factor of five or more may be called for. ScyllaDB automatically replicates the data in the background. You just set the replication factor, and the cluster handles the rest.
Tunable Consistency
Consistency in ScyllaDB is tunable — users can allow their transactions to have different degrees of consistency. Here are a few examples:
Consistency Level ONE
means successfully writing an update to any node is sufficient (the system will eventually replicate it to other nodes)
QUORUM
consistency
means a majority of replicas (based on the replication factor) need to acknowledge an update
Nodes, racks, and even whole data centers can fail, but your applications cannot. They must remain “always on.” That’s the goal for high-availability database systems. ScyllaDB achieves zero downtime through a few mechanisms, including rack and data center awareness and multi-datacenter (multi-zone and multi-region in public clouds) replication.
A ScyllaDB cluster can span data centers scattered across any geographic space (global replication). Data in ScyllaDB is automatically synchronized across data centers in a tuneably consistent manner without requiring users to create any sort of streaming or batch processing to ensure the clusters communicate changes. No add-on, costly components such as load balancers or external caches are required.
Rack and Datacenter Awareness ScyllaDB is topology-aware. It uses snitches to know which rack and data center a node belongs to. These allow you to spread your data across nodes in different racks in a data center or across different data centers, availability zones, and regions in public clouds. That way, your data is still available if a rack or even a whole data center goes out.
Multi-Datacenter Replication ScyllaDB clusters that span different data centers can employ the NetworkTopologyStrategy and set different replication factors for each data center. For instance, the primary data center may have an RF of 3 and a separate satellite data center may be set to an RF of 2. This allows you to determine the resiliency of your data per site.
Anti-Entropy
ScyllaDB is designed to operate even in the case of temporary node unavailability (when it eventually rejoins the cluster) or a node failure (when it has to be replaced). But when those situations occur, the system has to battle against entropy and bring the cluster back to full operation. The following processes and features are designed to mitigate that.
In the case of a temporary node outage (less than three hours), ScyllaDB uses a feature called Hinted Handoffs to keep track of what transactions occurred while the node was unavailable. When the node returns to service, the Hinted Handoffs allow the node to catch up on what transpired while it was offline. (You can think of it like a classmate who takes notes for you in case you miss a class or two.)
In case you had a more serious loss of availability of a node, ScyllaDB has a background repair process that allows you to get a new node up to speed. This process can be managed with a command-line interface, called nodetool repair, or from within ScyllaDB Manager, which can also restore data from backups.