





Why ScyllaDB completely bypasses the Linux cache during reads, using its own highly efficient row-based cache instead
ScyllaDB is built on the Seastar framework – and Seastar is the main component driving the database’s shard-per-core and shared-nothing asynchronous architecture. Seastar provides additional benefits for real-time and latency-sensitive applications, such as a dedicated userspace I/O scheduler, scheduling groups for workload isolation and prioritization, and more. You can learn more about this framework and ScyllaDB’s shard-per-core architecture in Dor Laor’s recent P99 CONF keynote.
However, one critical component of ScyllaDB’s architecture is not part of Seastar: our specialized cache. ScyllaDB completely bypasses the Linux cache during reads, using its own highly efficient row-based cache instead. This approach allows for low-latency reads without the added complexity of external caches, as discussed in this blog and recent talk. Taking this approach provides us the control needed to achieve predictable low latencies (e.g., single-digit millisecond P99 latencies for millions of OPS). It also allows us to offer users full visibility into details like cache hits and misses, evictions, and cache size so they can better understand and optimize performance from their side. Our specialized cache often enhances performance to the point where users can replace their external cache.
Let’s take a high-level look at why we took this path for ScyllaDB’s cache, then go a bit deeper into the technical details for those who are curious.
Why Not Use the Linux Page Cache?
Since ScyllaDB is designed to be fully compatible with Apache Cassandra (as well as DynamoDB), it takes advantage of the best elements of Cassandra’s design. Cassandra’s reliance on the default Linux page cache is not one of those “best elements.” The Linux page cache, also called disk cache, is a general-purpose type of cache. Although it can be tuned to better serve database workloads, it still lacks context over key database-specific needs.
Linux caching is inefficient for database implementations for a few reasons. First, the Linux page cache improves operating system performance by storing page-size chunks of files in memory to save on expensive disk reads. The Linux kernel treats files as 4KB chunks by default. This speeds up performance, but only when data is 4KB or larger. The problem is that many common database operations involve data smaller than 4KB. In those cases, Linux’s 4KB minimum leads to high read amplification.
Adding to the problem, the extra data is rarely useful for subsequent queries (since it usually has poor ‘spatial locality’). In most cases, it’s just wasted bandwidth. Cassandra attempts to alleviate read amplification by adding a key cache and a row cache, which directly store frequently used objects. However, Cassandra’s extra caches increase overall complexity and are very difficult to configure properly. The operator allocates memory to each cache. Different ratios produce varying performance characteristics and different workloads benefit from different settings. The operator also must decide how much memory to allocate to the JVM’s heap as well as the offheap memory structures. Since the allocations are performed at boot time, it’s practically impossible to get it right, especially for dynamic workloads that change dramatically over time.
Another problem: under the hood, the Linux page cache also performs synchronous blocking operations that impair system performance and predictability. Since Cassandra is unaware that a requested object does not reside in the Linux page cache, accesses to non-resident pages will cause a page fault and context switch to read from disk. Then it will context switch again to run another thread, and the original thread is paused. Eventually, when the disk data is ready (yet another interrupt context switch), the kernel will schedule in the original thread.
The diagram below shows the architecture of Cassandra’s caches, with layered key, row, and underlying Linux page caches.
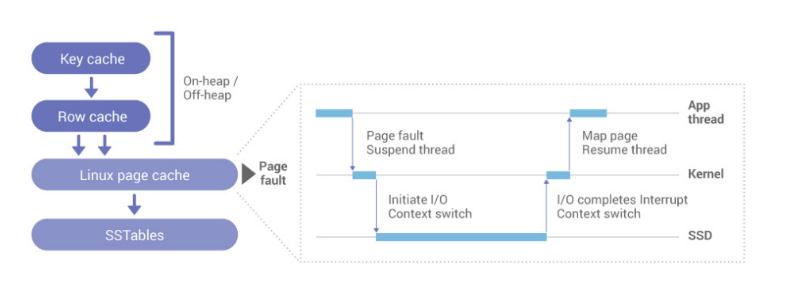
A look at the Linux page cache used by Apache Cassandra
Achieving Better Performance (and Control)
We recognized that a special-purpose cache would deliver better performance than Linux’s default cache – so, we implemented our own. Our unified cache can dynamically tune itself to any workload and removes the need to manually tune multiple different caches (as users are forced to do with Apache Cassandra). With an understanding of which objects are being cached, we can carefully control how items are populated and evicted. Additionally, the cache can be dynamically expanded or contracted in response to different workloads and under memory pressures.
Upon a read, if the data is no longer cached, then ScyllaDB will initiate a continuation task to asynchronously read from disk. The Seastar framework that ScyllaDB is built on will execute the continuation task in a μsec (1 million tasks/core/sec) and will rush to run the next task. There’s no blocking, heavyweight context switch, or waste.
This cache design enables each ScyllaDB node to serve more data, which in turn lets users run smaller clusters of more powerful nodes with larger disks. It also simplifies operations since it eliminates multiple competing caches and dynamically tunes itself at runtime to accommodate varying workloads. Moreover, having an efficient internal cache eliminates the need for a separate external cache, making for a more efficient, reliable, secure, and cost-effective unified solution.
Deeper Into Our Cache Design
With that overview, let’s go deeper into the details of ScyllaDB’s cache implementation. To start, let’s examine the data flow from the replica side.
When a write arrives at a replica, it first goes to an in-memory data structure – the memtable, which lives in RAM. For the write to be considered successful, it must also go to the commitlog for recovery – but the commitlog itself is not relevant here.
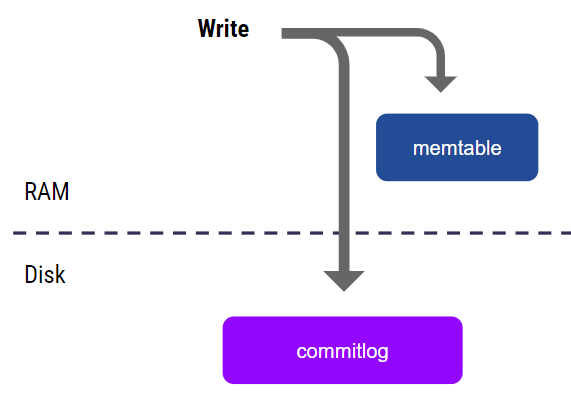
When the memtable grows large enough, we flush it to an SSTable (an immutable data structure that lives on disk). At that point, a new memtable gets created (to receive incoming writes), the flushed memtable contents are merged with the cache, and then the memtable is removed from memory. This process continues, and SSTables accumulate.
When a read comes in, we need to combine data from the memtable and all the accumulated SSTables to get a consistent view of all the existing writes.
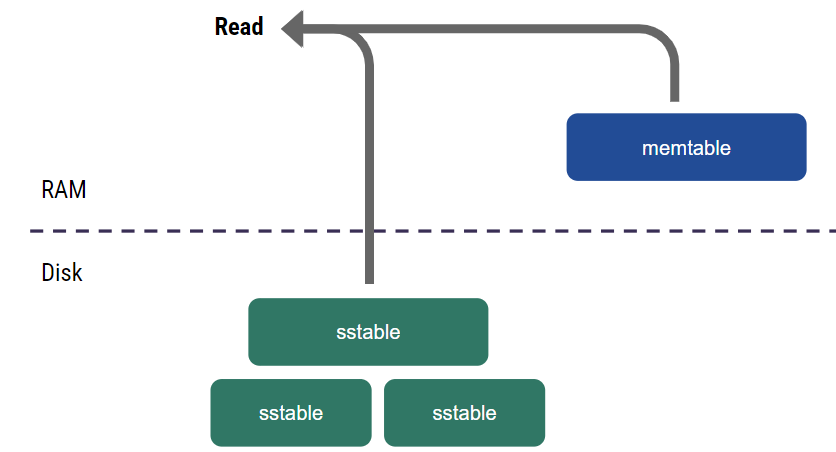
Read consistency is relatively simple to achieve here. For example, it can be achieved by taking a snapshot of memtables and pinning them in memory, taking a snapshot of SSTables, and then combining the data from all the sources. However, there’s a problem: it’s slow. It has to go to disk every time, and it reads from multiple parts. A cache can speed this along.
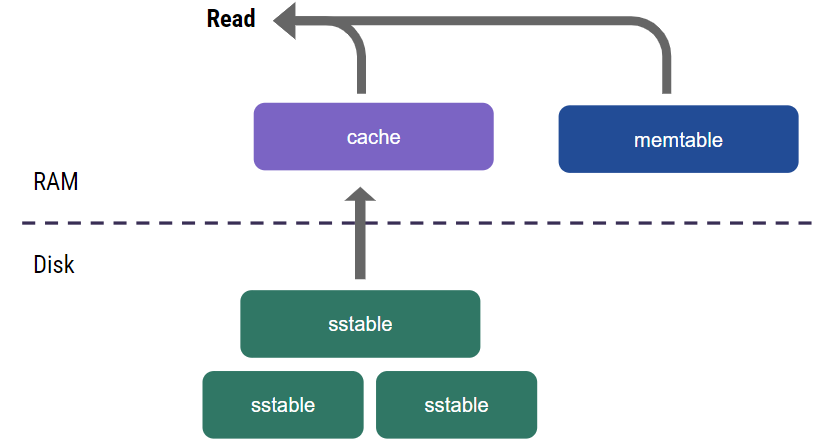
To avoid reading from disk every time, we use a read-through cache that semantically represents everything on disk (in SSTables) and caches a subset of that data in memory. The traditional way to implement that would be to use a buffer cache, caching the buffers we read from the SSTable files. Those buffers are typically 4 KB, which is what you would get if you used the Linux page cache.
Why Not Use a Buffer Cache?
As alluded to earlier, there are some problems with this approach (which is why ScyllaDB doesn’t use it).
Inefficient Use of Memory
First, it leads to inefficient memory use. If you want to cache just a single row, you need to cache a full buffer. A buffer is 4 KB, but the row can be much smaller (e.g., 300 bytes). If your data set is larger than the available RAM, access locality is not very likely, and this leads to inefficient use of memory.
Poor Negative Caching
This approach also affects negative caching very poorly. Since you don’t have a key, you need to cache the entire data buffer to indicate absent data. This further undermines memory efficiency.
Redundant Buffers Due to LSM
More problems with this approach: since the read might need to touch multiple SSTables, caching the row might require caching multiple buffers. This leads to inefficient memory usage again, and also to increased CPU overhead.
High CPU Overhead for Reads
When a row is cached across multiple buffers, data from those buffers must be merged on each read – and this consumes CPU cycles. Adding to the CPU overhead, storing buffers requires us to parse those buffers. The SSTable format isn’t optimized for read speed; it’s optimized for compact storage. You have to parse index buffers sequentially to interpret the index, and then you have to parse the data files. This can eat up even more CPU resources.
Premature Cache Eviction due to SSTable Compaction
SSTable compaction (which rewrites SSTables because they may contain redundant or expired data) can lead to premature cache eviction. The compaction process writes a new SSTable and deletes the old files. Deleting the old files implies that the buffers must be invalidated, which essentially invalidates the cache. Read performance suffers as a result because the reads result in cache misses.
Using an Object Cache Instead
Clearly, there are many problems with the buffer cache approach in this context. That’s why we opted to take a different path: implement an object cache. This specialized cache stores actual row objects, like memtables, that are not associated with files on disk. Think about it as another tree that holds the rows.
This data structure doesn’t suffer from the host of problems detailed above. More specifically, it’s optimized for fast reads and low CPU overhead. There’s a single version of a row, combining data from all relevant SSTables. And the caching is done with row granularity: if you want, you can keep only a single row in cache.
Memory Management
We don’t use the Linux page cache at all. We reserve the vast majority of each node’s available memory for ScyllaDB; a very small reserve is left for the OS (e.g., for socket buffers). ScyllaDB’s portion of the memory is mostly dedicated to the cache. The cache is assigned to use all available memory and then shrink on demand when there’s pressure from other parts of the system (like memtables or operational tasks). We have implemented controllers to ensure that other pressures never steal too much memory from the cache.
CPU Sharding
Another important design element has to do with sharding. With our shard-per-core architecture, every CPU in ScyllaDB is responsible for a subset of data and every CPU has separate data structures to manage the data. So, every CPU has a separate cache and separate memtables – and those data structures can be accessed only from the CPU that owns them.

Thread-Per-Core Architecture
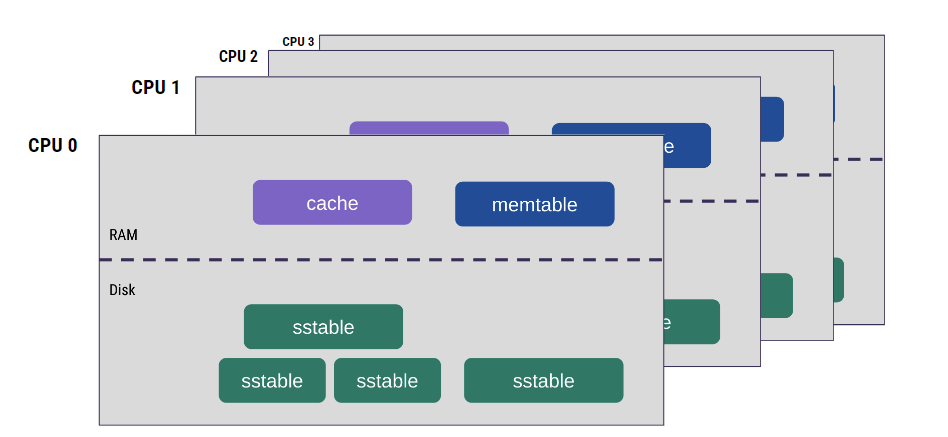
Thread-per-core is another important component of this design. All processing is done in a single thread per CPU. Execution is divided into short tasks that are executed sequentially with cooperative preemption, which means that our code can precisely control the exact boundaries of the tasks. If there’s a preemption signal (which comes from a timer), then the task has to yield cooperatively. It’s not preempted in any place; it can determine the possible preemption points.
Cache Coherency
All of this allows us to have complex operations on data within the task – without having to deal with real concurrency (which we would face if we used multi-threading and accessed data from multiple CPUs). We don’t have to use locks, we avoid lock contention, and we don’t have to implement complex lock-free algorithms. Our data structures and algorithms can be simple. For example, when we have a read, it can access cache and memtable lookup in a single task, and have a consistent view on both. That’s achieved without involving any synchronization mechanisms. That means that everything works fast and performance is quite predictable.
Range Queries and Range Deletion
Supporting our query language and the data model is a potential problem with an object cache. ScyllaDB isn’t a simple key-value store. We support more complex operations such as range queries and range deletions, and that impacts how caching is implemented. This can lead to complications with an object cache that aren’t an issue with a buffer cache.
For example, consider range queries. You have a query that wants to scan a set of rows. If your cache was just key-value, you wouldn’t be able to use it to speed up your reads because you would never know if there was other data stored on disk in between the entries in the cache. As a result, such a read would have to always go to disk for the gaps.
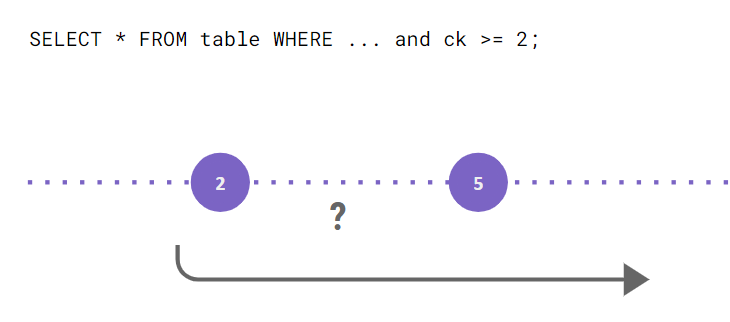
Our cache is designed to handle this case. We store information about range continuity: indicating that a given range in cache is complete (and there’s no need for the read to check if the disk contains additional entries). If you repeat the scan, it won’t go to disk.
Also, range deletions require special handling. Due to ScyllaDB’s eventual consistency model, deletion is not just about removing data. It also leaves a marker for future reconciliation. That marker is called a tombstone, and the cache needs to be able to store this marker. Our cache is prepared to handle that; it piggybacks on the range continuity mentioned above – basically annotating the range continuity information with the tombstone.
Two Other Distinctive Caching Elements
Before we close, let’s look briefly at two other interesting things we’ve implemented with respect to ScyllaDB caching.
Cache Bypass
The fact that ScyllaDB is a read-through type of cache means that – by default – every read you perform will be populated to the cache and then served by the users. However, this may not always be what users want. For example, if you are potentially scanning tons of data, or occasionally need to query data that probably won’t be read again in the future, this could invalidate important items from your existing cache.
To prevent this, we extended the CQL protocol with the BYPASS CACHE extension. This tells the database that it should NOT populate the cache with the items it reads as a result of your query – thus stopping it from invalidating important records. BYPASS CACHE is also often used in conjunction with ScyllaDB’s Workload Prioritization on analytics use cases that frequently scan data in bulk.
SSTable Index Caching
SSTable Index Caching is a relatively new addition to ScyllaDB. Since the 5.0 release, we also cache the SSTable index component to further speed up reads that have to go to disk. The SSTable Index is automatically populated on access; upon memory pressure, it’s evicted in a way that doesn’t affect cache performance.
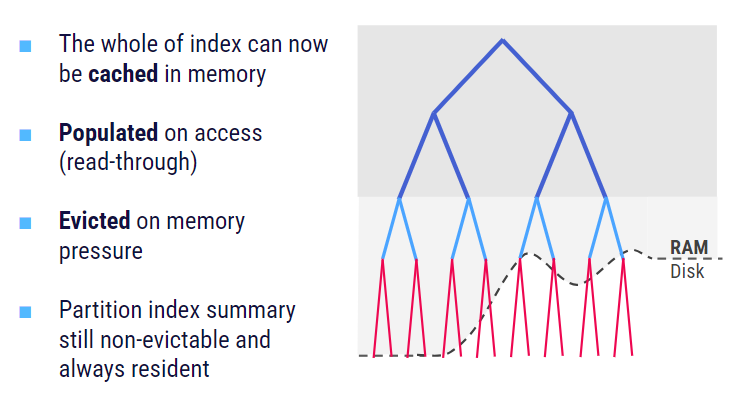
One advantage of SSTable Index caching is its impact on large partition performance. Below, you can see our before and after measurements with large partitions directly reading cold data from disk. Note that the throughput more than tripled after we introduced SSTable indexing, making on-disk lookups even faster.

Summary
In summary, ScyllaDB has a fast cache that’s optimized for speeding up reads. It is highly efficient because the data and cache are colocated on the same CPU. And it upholds all the semantics of the query language and the data model, as well as ScyllaDB’s consistency guarantees.

