



NoSQL Latency FAQs
What are NoSQL Latency Requirements?
The latency requirements for NoSQL databases can vary depending on the specific use case and workload. For some applications that require near real-time processing, NoSQL low-latency databases with very low P99 or even P999 latencies are critical. In these cases, NoSQL databases may need to provide sub-millisecond or even sub-microsecond response times to meet the performance requirements of the application.
Other modern applications may be less latency-sensitive, but still require relatively fast access to data. For example, a web application that uses a NoSQL database to store user profiles or product information may require response times in the low tens or hundreds of milliseconds to retrieve data to provide a good user experience. Other NoSQL database use cases might prioritize throughput over latency (e.g., focusing on ingesting very large datasets as fast as possible).
Ultimately, latency requirements for a NoSQL database depend on specific application needs, the number of concurrent users and their expectations, the size and complexity of the data, and the predicted workload.
How Does Latency Differ Between SQL vs NoSQL Databases?
The latency characteristics of SQL and NoSQL databases can differ significantly, depending on the specific implementation and use case. However, there are some general differences in the way these two types of databases handle latency.
SQL databases, also called relational database management systems (RDBMS), are designed to provide highly structured, relational data storage and processing. They use a schema to define the structure of the data, and typically rely on SQL (Structured Query Language) to access and manipulate the data. SQL databases are often optimized for transactional processing, and they can provide fast and efficient access to data when the schema is well-designed and the data is properly indexed.
In contrast, NoSQL databases are designed to handle large amounts of unstructured or semi-structured data. They typically do not use a fixed schema, and they may use different data models (such as key-value pairs, graph, or document databases) to store and access data.
In general, NoSQL databases may have lower latency than SQL databases because they are typically designed for faster data access and processing. However, this may not always be the case; it depends on the specific database architecture as well as the workload.
Ultimately, the differences in SQL vs NoSQL latency highlight a solid range of choices for the specific requirements of any application and the characteristics of any sort of data being stored and processed there. [See how Distributed SQL and NoSQL latency compare]
Characteristics of Low Latency NoSQL Databases
Which type of database is best able to achieve low latency? There are several specific qualities of NoSQL databases that allow them to achieve low latency:
Distributed architecture. NoSQL databases are designed to be distributed across multiple servers, which allows them to handle large volumes of data, reduce the latency of data access, and provide faster response times.
Horizontal scaling. NoSQL databases can scale horizontally, meaning that additional nodes can be added to the cluster to increase its capacity and performance. This allows NoSQL databases to handle growing workloads and provide fast access to data even as the system scales.
High performance data models. NoSQL databases typically use data models that are optimized for high-speed data access and processing. For example, document-oriented databases store data in a format that is easy to read and modify, while key-value stores use a simple data model that is optimized for fast lookups.
Caching and in-memory processing. NoSQL databases often use caching and in-memory processing to speed up data access, reduce the latency of data retrieval, and improve overall system performance.
Eventual consistency. Many NoSQL databases use eventual consistency, which allows them to provide fast access to data even as updates are being made. Rather than waiting for updates to be fully replicated across the entire cluster, NoSQL databases can return a stored stale version of the data, which is acceptable for some use cases.
These qualities, along with other design choices and optimizations, allow databases to achieve low NoSQL latency and provide fast access to large amounts of data.
How Do Data Structures and Unstructured Data Affect NoSQL Latency?
Unstructured data and other data types can have both positive and negative effects on NoSQL latency, depending on how it is stored and accessed.
NoSQL databases are designed to handle unstructured or semi-structured data, and are often optimized for high-speed access to either type. By using flexible data models such as document-oriented databases, NoSQL databases can store and access unstructured data in a way that is fast and efficient.
However, unstructured data can also pose performance and scalability challenges for NoSQL databases. Data that is very large or complex may take longer to process and access, which can increase latency. Similarly, data that is not properly indexed or partitioned may also increase latency.
What are Common Challenges with Low Latency NoSQL
The premise of NoSQL is the ability to ‘scale out’ on cheap, commodity hardware. When more capacity is needed, administrators simply add servers to database clusters. This simplicity, however, evolved into a vulnerability. Clusters often grow out of control, resulting in a phenomenon called ‘node sprawl.’ The architecture of the first-gen NoSQL databases actively encourages larger clusters of less powerful machines. From the perspective of latency, this architecture virtually ensures poor p99 performance due to more context switches, disk failures, and network hiccups – all of which create latency outliers.
Is MongoDB a Good Solution for NoSQL Latency Challenges?
For example, the widely-used MongoDB NoSQL database is susceptible to poor long-tail performance due to its master/slave architecture. Once MongoDB is set up and the pipe is configured, throughput is essentially fixed. Once the database is running, the only remaining mechanism that is available for optimizing performance is sharding. Configuring sharding is a notoriously risky undertaking that often requires weeks of trial-and-error experimentation. [See MongoDB NoSQL latency comparisons]
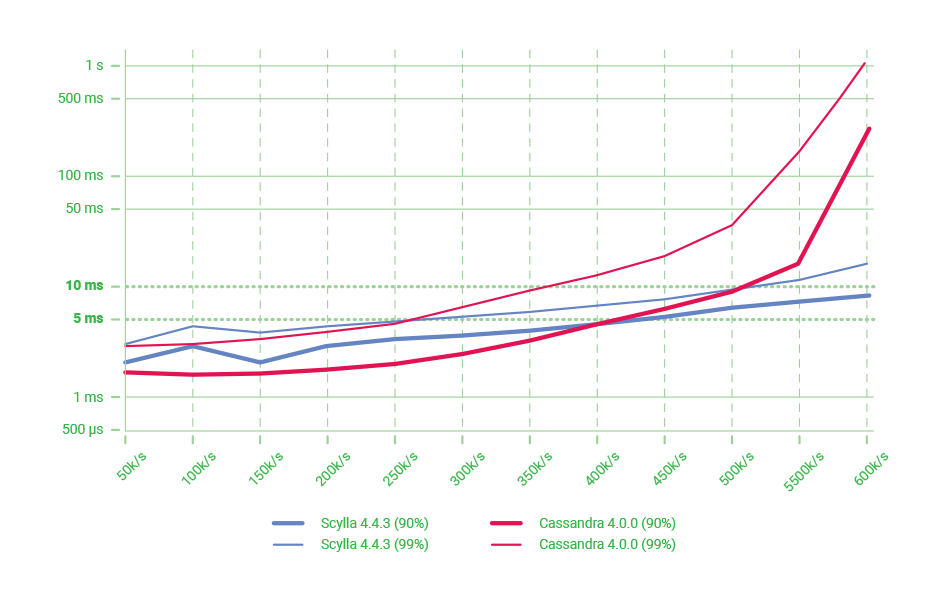
Is Apache Cassandra a Good Solution for NoSQL Latency Challenges?
Apache Cassandra, an open source NoSQL database, has a peer-to-peer architecture. But even without a master/slave approach, Cassandra has proven to have its own weaknesses with respect to NoSQL latency.
First, Cassandra is implemented in Java, making it vulnerable to the weaknesses of that platform. It is mainly susceptible to pauses caused by garbage collection (GC). Some monitoring teams even have a dedicated metric devoted to GC stall percentage. Compaction and repair operations, which become more onerous in larger clusters, add to the outliers that plague Cassandra deployments.
Second, Cassandra has limited ability to utilize modern hardware for compaction and streaming. Since Cassandra is an ‘append-only’ system, keeping data coherent for reads requires a compaction process. Servers with a high number of cores are available on IaaS and on-prem deployment. However, Cassandra is not able to scale the compaction process linearly with the increased number of available cores. This limitation results in higher read latency and a need for more servers to be deployed in the clusters.
During streaming, Cassandra limits the amount of data streamed from nodes to control the load on the sending and receiving servers. Modern servers utilizing 10GbE networks or higher, SSDs, and fast CPUs should not be limited by the software using these servers. Cassandra throttles the streaming process to 200 mbits/sec. Limiting streaming has a direct impact on latency. When rebuilding a node, your application is using reduced capacity. While repairing your cluster, your application might wind up waiting for server-side reconciliation of data discrepancy, contributing to higher read latency.
Lastly, some workloads have higher read characteristics that are specific to their use case. The system therefore must favor the read path of data, which involves external caches or waiting for media to fetch and deliver. Conversely, write workloads look for direct fast access to the persistent volume. After all, a database is built to persist data. Cassandra does not recommend that users leverage the built-in table caching system; this means reads are fetched from disk, regardless of whether the data was ever changed after the first insertion.
Since Cassandra has different settings for storage media, JVM heap cache, and concurrency on read and writes, the burden is placed on administrators to properly configure the system for specific workloads. When workloads are unpredictable and spiky, administrators must constantly tune the Cassandra cluster to match read and write latencies.
[See Cassandra latency comparisons]
Is an External Cache a Good Solution for NoSQL Latency Challenges?
Many IT organizations turn to external caches as a band-aid to insulate end users from the poor long-tail performance of their databases. But the limitations of external caches are well-documented. Caches are often used to enhance read performance, but write latencies derive little or no benefit. Transactional systems, which depend on real-time performance, cannot drop mutations, so caches offer no help. Transactional systems depend on low tail latency for writes as well as reads. If spikes are too frequent, the client experience deteriorates, becoming very sluggish. In the worst case scenario, data loss occurs.
Still, front end cache for reads is often a necessary evil, to the point where it is treated as obligatory. However, maintaining coherence between cache and persistent storage is a well-documented hassle that can easily bog down operations and negatively impact customers. The best approach is to identify a system that intrinsically combines cache and persistent storage in a way that optimizes performance and data integrity. [Learn more about the risks of external caches]
Is ScyllaDB a Good Solution for NoSQL Latency Challenges?
Yes, ScyllaDB features a close-to-the-metal design that squeezes every possible ounce of performance out of modern infrastructure. As a result, it is uniquely positioned to take full advantage of modern infrastructure. ScyllaDB delivers predictable single-digit millisecond latencies with millions of IOPS and is scalable to terabytes or petabytes storage.
ScyllaDB’s ability to tame long-tail latencies has led to its adoption in industries such as media, cybersecurity, the industrial Internet of Things (IIoT), AdTech, retail, and social media.
ScyllaDB is built on an advanced, open-source C++ framework for high-performance server applications on modern hardware. The team that invented ScyllaDB has deep roots in low-level kernel programming. They created the KVM hypervisor, which now powers Google, AWS, OpenStack, and many other public clouds.
Modern hardware is capable of performing millions of I/O operations per second (IOPS). ScyllaDB’s asynchronous architecture takes advantage of this capability to minimize p99 latencies. ScyllaDB is uniquely able to support petabyte-scale workloads, millions of IOPs, and P99 latencies <10 msec while also significantly reducing total cost of ownership.
What are some Examples of Low Latency NoSQL Use Cases?
Digital Media Low Latency NoSQL
A great example of the need for consistently low p99 latency is Comcast, one of America’s leading providers of communications, entertainment, and cable products and service. Comcast’s X1 Platform enables viewers to discover, play, pause, and save videos, and also to maintain a history so that viewers can easily access ‘last watched’ programs. As a provider of critical services that require real-time performance, the platform is highly sensitive to long-tail latency.
The X1 Platform has a massive user base. Over the course of seven years, the X1 platform has grown from 30,000 devices to 31 million set-top boxes. The X1 Scheduler processes a staggering 2 billion RESTful calls daily.
Comcast originally built their system against Cassandra. For the reasons that we have touched on in this paper, Cassandra was not meeting their needs for low long-tail latency, so the X1 team decided to research alternatives. Comcast evaluated their existing database, Cassandra, against ScyllaDB, the database for data-intensive apps that require high performance and low latency.
Comcast turned to ScyllaDB to achieve better long-tail latencies than with Cassandra. To compare the two databases, Comcast benchmarked the platform prior to deploying it in production. A key measurement for Comcast turned out to be p99, and even p99.9. As Comcast discovered, performance characteristics of different databases become even more starkly differentiated in these edge cases.
By paying close attention to long-tail performance, Comcast has been able to maximize real-time performance where it’s most important: the user experience. As a side-effect, Comcast was able to reduce node counts, and hence lower the overall TCO of their system.
Industrial Internet of Things (IIoT) Low Latency NoSQL
Companies working in IIoT have unique requirements when it comes to long-tail performance. First is the need to ingest huge amounts of data very rapidly. IIoT is based on sensor data and telemetry from industrial equipment and robots in the field and on the factory floor. This data is processed and analyzed to deliver real-time alerts as well as historical views over long time periods. The result is that IIoT companies often must deploy two fairly redundant data infrastructures: one for operational workloads (OLTP) and the other for analytics workloads (OLAP).
Augury, a leading AI-based Machine Health solution provider, provides a nice example of how low long-tail latency helps in IIoT use cases. Augury helps their customers perform timely maintenance by delivering real-time insights and historical analytics about the condition of machines on the manufacturing floor. Beyond alerting, Augury provides actionable suggestions on the root cause of faults, recommendations on which checks to perform, and where to best focus the maintenance that’s needed to keep machines running smoothly and avert catastrophic failures. The results are impressive — averages of 75% fewer breakdowns, 30% lower asset costs, 45% higher uptime.
Augury initially built their predictive services against MongoDB. Yet as the company began to grow and the dataset reached the limits of MongoDB, they realized the need for data infrastructure that could scale horizontally. Augury turned to ScyllaDB to achieve low long-tail latencies and analytics capabilities from a unified database infrastructure.
Cybersecurity Low Latency NoSQL
Cybersecurity firms are also highly sensitive to long-tail latency. Insights that can prevent breaches are derived in real-time from massive data sets that span devices, services, and endpoints. Low tail latency not only enhances the end user experience; it also helps to more quickly identify and prevent threats and hacks.
FireEye (now known as Trellix), a top cybersecurity company, provides a great example. FireEye’s Threat Intelligence application centralizes, organizes, and processes threat intel data to support analysts. Threat data is organized into a graph representing relationships among actors, such as hackers and criminal organizations, and threat vectors represented by URLs, email, IP addresses, and malware signatures.
FireEye discovered that a system is only as strong or as performant as its underlying database solution. By paying attention to long-tail latencies, FireEye was able to make the overall system 100x faster than before; a query that traverses 15,000 graph nodes now returns results in about 300ms.
As with Comcast, this is partially the result of a smaller infrastructure footprint. FireEye dramatically slashed the storage footprint, while preserving the 1000-2000% performance increase they had experienced by switching to ScyllaDB. Ultimately, they reduced AWS spend to 10% of the original cost.
Lookout is another cybersecurity provider whose mission is to protect data in today’s privacy-focused world. Lookout’s benchmark simulated 38 million devices generating 110,000 messages per second. The results were average latencies in milliseconds with the ScyllaDB cluster running at very high levels of utilization (between 75% and 90%). Best of all, however, Lookout found that ScyllaDB delivered consistent single-digit millisecond p99 latencies.
What are some guidelines for improving NoSQL Latency?
Here are some general guidelines that your organization can follow to improve master long-tail latency with NoSQL.
- Design a system that ensures p99 latency based on your organization’s throughput targets.
- Do not ignore performance outliers. Embrace them and use them to optimize system performance.
- Minimize the possibility of outliers by minimizing infrastructure. For a start, avoid external database caches. Shrink database clusters by scaling vertically on more powerful hardware.
- Adopt database infrastructure that can make optimal use of powerful hardware.
- Adopt a peer-to-peer database architecture.
- Minimize the vectors needed to resize the system. Ideally, limit vectors to system resources, such as CPU cores.
- Avoid databases that add complexity. Look for databases with a close-to-the hardware architecture.
- Take into account the price-performance of your database. You do not need to break your IT budget to achieve real-time long-tail performance.