




Update: For more on this topic, see our 2023 webinar, Replacing Your Cache with ScyllaDB
Recently AWS unleashed a managed cache solution, Amazon DynamoDB Accelerator (DAX), in front of its database. This blog post will discuss the pros and cons of external database caches.
Developers usually consider caching when the current database deployment cannot meet the required SLA. This is a clear performance-oriented decision. Caching may look like an easy and quick solution because the deployment can be implemented without lots of hassle and without incurring significant cost on database scaling or worse, database schema redesign or even a deeper technology transformation.
How are most cache deployments implemented?
Usually, cache deployments are implemented in the form of a side cache as illustrated on the left in the following figure referenced from DynamoDB. The cache is independent of the database, and the application is responsible for the cache coherency. The application performs double writes, both for the cache and for the database. Reads are done first from the cache, and only if the data isn’t there, a separate read goes to the database. As you can imagine, questions about coherency, high availability and complexity immediately arise.
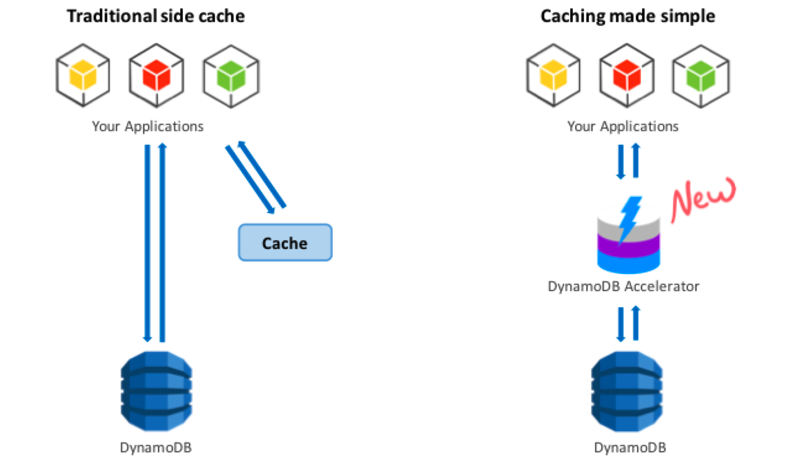
Figure 1: Caching Simplified
Figure 1 shows the advantages of a transparent cache like the DAX: It doesn’t require application changes and it is automatically coherent. DAX eliminates the major data coherency problem. But even a write-through cache implementation such as DAX has challenges in its internal implementation. For example, consider a parallel write + read requests case (Figure 2).

Figure 2: Concurrent rd/wr requests case
At t1, the client issues a write w1.
At t2, the client issues a read r1.
At t3, the client issues a write w2.
DAX requires following the exact locking and consistency scheme of DynamoDB, so the result of r1 will be consistent with Dynamo’s guarantees. When facing failures involving DAX caching nodes or DynamoDB’s data nodes, the result needs to be the same. The great news for DynamoDB users who suffer from latency issues is that they no longer need to be concerned about the application’s coherency or complexity.
But is this the best industry standard? Are databases doomed to have a cache in front of them? We at ScyllaDB believe these caches are inefficient, to say the least, and that users should refrain from using caches unless they have no other choice. Here are seven reasons why:
1. An external cache adds latency.
A separate cache means another hop on the way. When a cache surrounds the database, the first access occurs at the cache layer. If the data isn’t in the cache, then the request is sent to the database. The result is additional latency to an already slow path of uncached data. One may claim that when the entire dataset fits the cache, the additional latency doesn’t come into play, but most of the time there is more than a single workload/pattern that hits the database and some of it will carry the extra hop cost.
2. An external cache is an additional cost.
Caching means DRAM which means a higher cost per gigabyte than SSDs/HDDs. In a scenario when additional RAM can store frequently accessed objects, it is best to utilize the existing database RAM, and potentially increase it so it will be used for internal caching. In other cases, the working set size can be too big, some cases reaching petabytes and thus another SSD friendly implementation is preferred.
3. External caching decreases availability.
The cache’s HA usually isn’t as good as the database’s HA. Modern distributed databases have multiple replicas; they also are topology aware and speed aware and can sustain multiple failures. For example, a common replication pattern in ScyllaDB is three local replicas, and a quorum is required for acknowledged replies. In addition, copies reside in remote data centers, which can be consulted. Caches do not have good high-availability properties and can easily fail, or have partial failures, which are worse in terms of consistency. When the cache fails (and all components are doomed to fail at some point), the database will get hit at full throughput and your SLA will not be satisfied together with your guarantees to your end users.Although the DAX design and implementation are proprietary, I tend to believe that the DAX developers did not compromise availability but it’s hard to tell what happens in a case of three availability zones.
4. Application complexity — your application needs to handle more cases.
Complexity is certainly not the DAX case but it is applicable for standard external caches. Once you have an external cache, you need to keep the cache up to date with the client and the database. For instance, if your database runs repairs, the cache needs to be synced (or invalidated). Your client retry and timeout policies need to match the properties of the cache but also need to function when the cache is done. Usually, such scenarios are hard to test.
5. External caching ruins the database caching.
Modern databases have internal caches and complex policies to manage their caches. When you place a cache in front of the database, most read requests will only reach the external cache and the database won’t keep these objects in its memory. As a result, the database cache isn’t effective, and when requests eventually reach the database, its cache will be cold and the responses will come primarily from the disk.
6 External caching isn’t secure.
Again, security is not an issue with DAX. But naturally, the encryption, isolation and access control on data placed in the cache are likely to be different from the ones at the database layer itself.

7. External caching ignores the database knowledge and database resources.
Databases are very complex and impose high disk I/O workloads on the system. Any of the queries access the same data, and some amount of the working set size can be cached in memory in order to save disk accesses. A good database should have multiple sophisticated logic to decide which objects, indexes, and access it should cache. The database also should have various eviction policies (with the least recently used policy as a straightforward example) that determine when new data should replace existing older cached objects. Another example is scan-resistant caching. When scanning a large dataset, a lot of objects are read from the disk or touched in the cache. The database can realize this is a scan and not a regular query and chose to leave these objects outside its internal cache.The database automatically synchronizes the content of the cache with the disk and with the incoming requests, and thus the user and the developer do not need to do anything to make it happen.If for some reason your database doesn’t respond fast enough, it means that either a) the cache is misconfigured, b) it doesn’t have enough RAM for caching, c) the working set size and request pattern don’t fit the cache, or d) the database cache implementation is poor.
We at ScyllaDB put a lot of effort into making our internal embedded cache rock. This is where your RAM investment will shine the most. Our cache can span through the entire memory of the host from a mere 16GB to 1TB. There is no need to configure it, and we dynamically divide the RAM into several areas.
Because our malloc algorithm is log structured, the memory utilization is high—there is no need to fit memory into the size of two bulks. Allocations are copyable and we can compact the memory so it will not get fragmented over time. Allocation is append-only and thus fast. More details about the allocators can be found here. ScyllaDB does not rely on external caches such as the Linux page cache, so it can store the objects themselves without the overhead. In case data isn’t in the cache, ScyllaDB is aware and doesn’t incur a page fault; instead, it issues an async DMA operation to retrieve the data from the disk.
Henrik Johansson, a senior developer at Eniro, led the migration from Redis to ScyllaDB due to speed. “It is fast. We have started to get used to seeing latencies in the microseconds as opposed to milliseconds.”
Outbrain, the world’s largest recommendation engine, reduced the size of its Cassandra cluster, eliminated the memcache service in front of it, and even improved their latency in the process.
An example of effective caching can be found in our i2.8xl benchmark on AWS.
The following figure from the benchmark shows ScyllaDB’s disk and cache behavior during the small spread read test. Nearly all requests are served from ScyllaDB’s cache and there is no reason to place a cache in front, on the side or behind the database.

Figure 3: ScyllaDB’s disk and cache behavior
