



Cassandra Cluster FAQs
What is a Cassandra Cluster and How Does it Work?
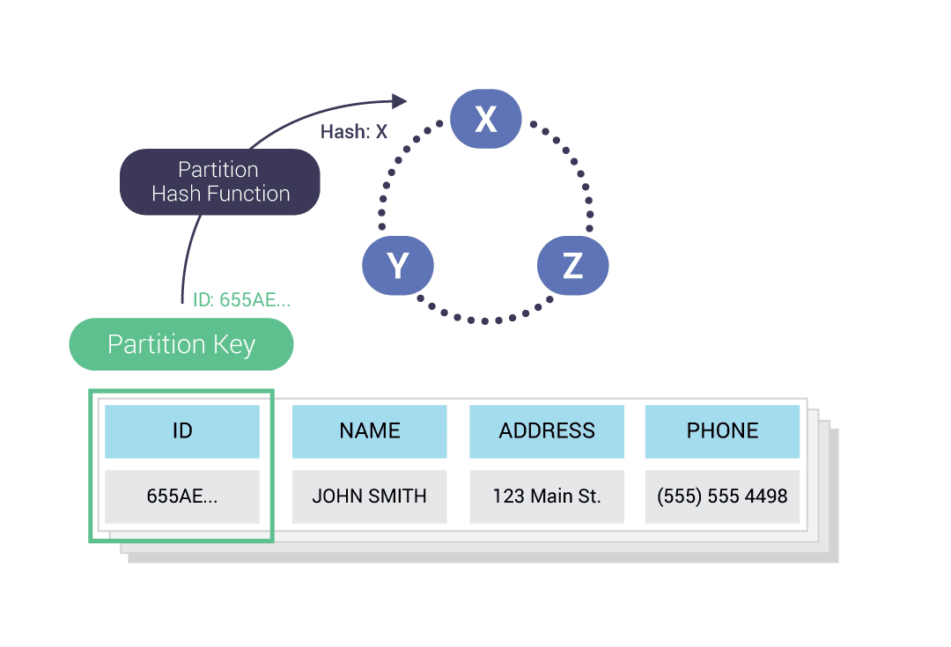
Given that Apache Cassandra features were architected with horizontal scalability in mind, Cassandra can scale to a theoretically unlimited number of nodes in a cluster, and Cassandra clusters can be geographically dispersed, with data exchanged between clusters using multi-datacenter replication.
In Cassandra a node is either a whole physical server, or an allocated portion of a physical server in a virtualized or containerized environment. Each node will have requisite processing power (CPUs), memory (RAM), and storage (usually, in current servers, in the form of solid-state drives, known as SSDs).
These nodes are organized into clusters. Cassandra clusters can be in physical proximity (such as in the same datacenter), or can be distributed over great geographical distances. To organize clusters into datacenters and then also across different racks (to ensure high availability), Cassandra uses a snitch monitor.
Cassandra uses a mechanism called multi-datacenter replication to ensure data is transferred and eventually synchronized between its clusters. Note that two Cassandra clusters could be installed side-by-side in the same datacenter yet employ this mechanism to transfer data between the clusters.
How Nodes in the Cassandra Cluster Communicate
Within a Cassandra cluster, there is no central primary (or master) node. All nodes in the cluster are peers. There are mechanisms, such as the Gossip protocol to determine when the cluster is first started for nodes to discover each other.
Once the topology is established, however, it is not static. This same Gossip mechanism helps to determine when additional nodes are added to the cluster, or when nodes are removed from the cluster (either through purposeful decommissioning or through temporary unavailability or catastrophic outages). (Read more here about Cassandra’s use of Gossip.)
How to Size a Cassandra Cluster
Cassandra cluster node sprawl is a problem in today’s datacenters. Also known as ‘wasteful overprovisioning,’ Cassandra node sprawl often reflects an effort to spend your way to low latency and high availability. Often, all the overspending on overprovisioning does not result in the performance requirements being met.
Overprovisioning can provide some level of cushion (albeit an expensive one) against traffic spikes, outages, and other problems. But this comes at the cost of more server failures and higher administrative overhead.
Learn how Comcast reduced Cassandra cluster size from 962 nodes to 78 nodes
Learn how Fanatics reduced their 55 nodes Cassandra cluster with a 6 nodes cluster
Learn strategies for sizing your own cluster more efficiently
How to Check Cassandra Cluster Status?
Among Cassandra cluster best practices are regularly checking Cassandra cluster health. Do this with Cassandra’s nodetool, a monitoring tool that helps perform routine maintenance tasks and monitor Cassandra clusters.
There are three important nodetool commands that relate to Cassandra cluster health to be aware of: nodetool status, nodetool info, and nodetool tpstats.
You can conduct a Cassandra cluster health check with nodetool status. Nodetool status commands allow you to check Cassandra cluster status and view things like data distribution among nodes, whether nodes are up or down, node states, node data loads, token numbers, and related information.
The nodetool info command offers node information, including active or passive gossip status, uptime, disk load, chunk cache information, times started (generation), heap memory usage, and more.
Finally, the nodetool tpstats command shows thread pool usage statistics at each stage.
What is Cassandra Cluster Management?
Cassandra Cluster Manager (CCM) is a tool and script/library for creating, launching, and removing multi-node Apache Cassandra clusters on local machines. It is ideal for rapid Cassandra cluster installation for testing and development, and is the foundation for dtests, distributed Cassandra tests. The goal of the tool is to make it easy to learn how to setup Cassandra cluster and manage or destroy a Cassandra cluster on a localhost for testing.
Does ScyllaDB Address Cassandra Clusters?
Yes. ScyllaDB is an alternative to Cassandra that delivers additional features and was rewritten completely in C++. It is API-compatible with Cassandra, with many similarities as well as important differences vs Cassandra. ScyllaDB offers both open source and enterprise options as well as a cloud-hosted (DBaaS) version. Learn more about why ScyllaDB is a better alternative to Cassandra.
ScyllaDB also offers ScyllaDB Manager for cluster management. It performs regular health checks on server nodes, ensuring awareness of any node degradation or downtime. It automates repetitive tasks such as node rebuilds and repairs, automates data backups, and enables faster troubleshooting.