





If you were forced to choose just one thing that would prompt you to move your mission-critical functionality to a new database, what would it be? Better performance? Worries about future scaling on your existing platform? Easier time for your DevOps? What about awesome support from the company itself? At ScyllaDB Summit 2017, mParticle’s Nayden Kolev explained how all of the above factors started the group one year ago on a fruitful collaboration with ScyllaDB in production.
As the systems architect and production operations lead at mParticle, Nayden found himself in a quandary: how could he overcome scalability and performance challenges and take new Amazon Machine Images (AMIs) and hardware into use, while growing the system to support 3 times the capacity in a single year, while still meeting mission-critical SLAs?
mParticle is an API and platform for integrating the customer data pipeline—“for every screen”—to orchestrate the entire marketing stack. As a data platform geared towards mobile, mParticle makes it easier for marketers to ingest data from a variety of sources, segment it, enrich it with data such as identity information, and send it along to third parties. In doing so, marketers can improve insights into customer utilization while brands can enhance analytics and optimize acquisition, engagement, and monetization.
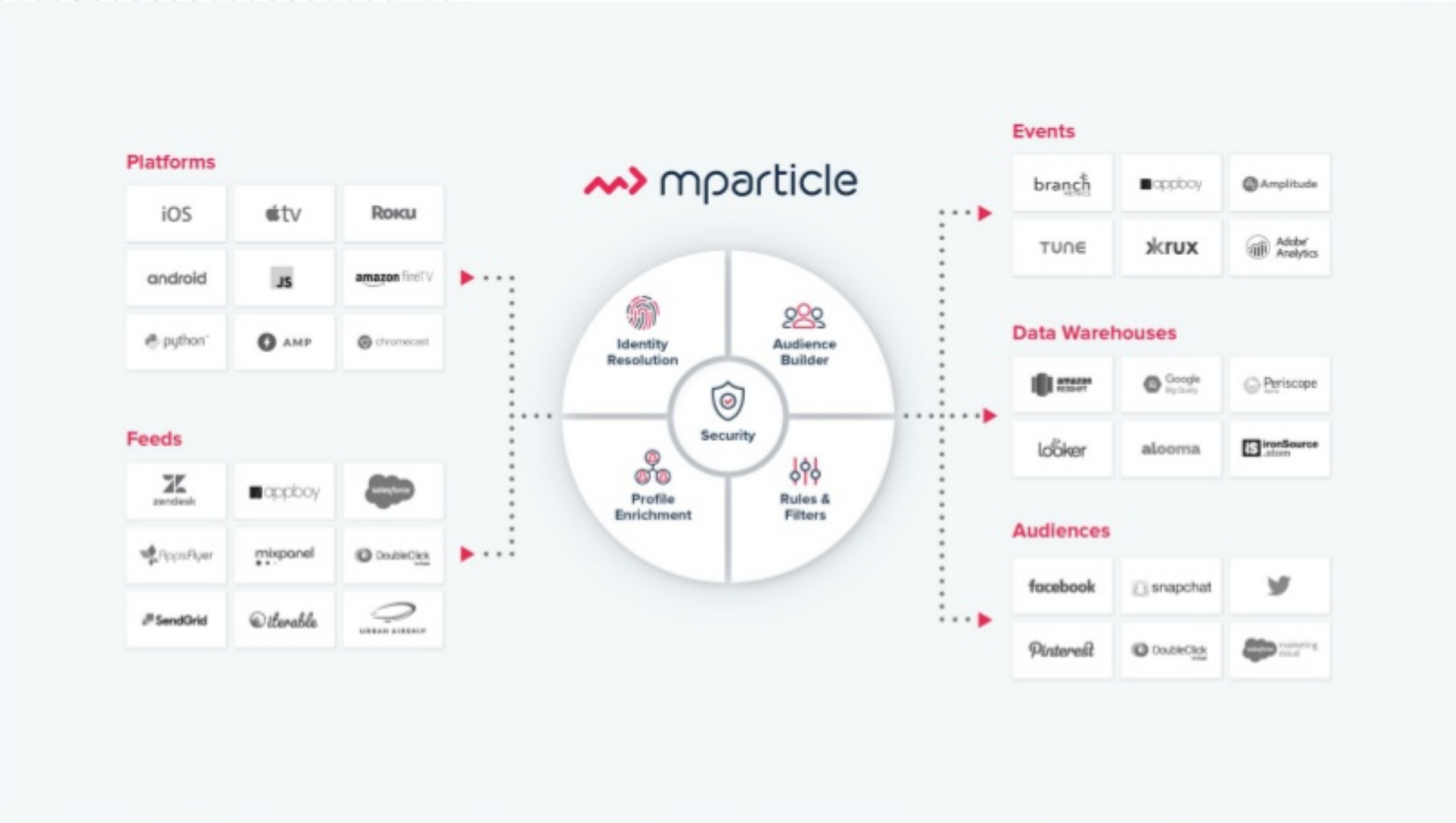
mParticle’s varied and discerning customer base includes massive brands such as Airbnb, Spotify, Electronic Arts, NBC, and Turner. To support the more than 120 (and counting) integrations amidst 1.35 billion unique mobile users monthly, the system must stand up under 50 billion messages a month and provide near real-time SLAs for each and every mobile user.
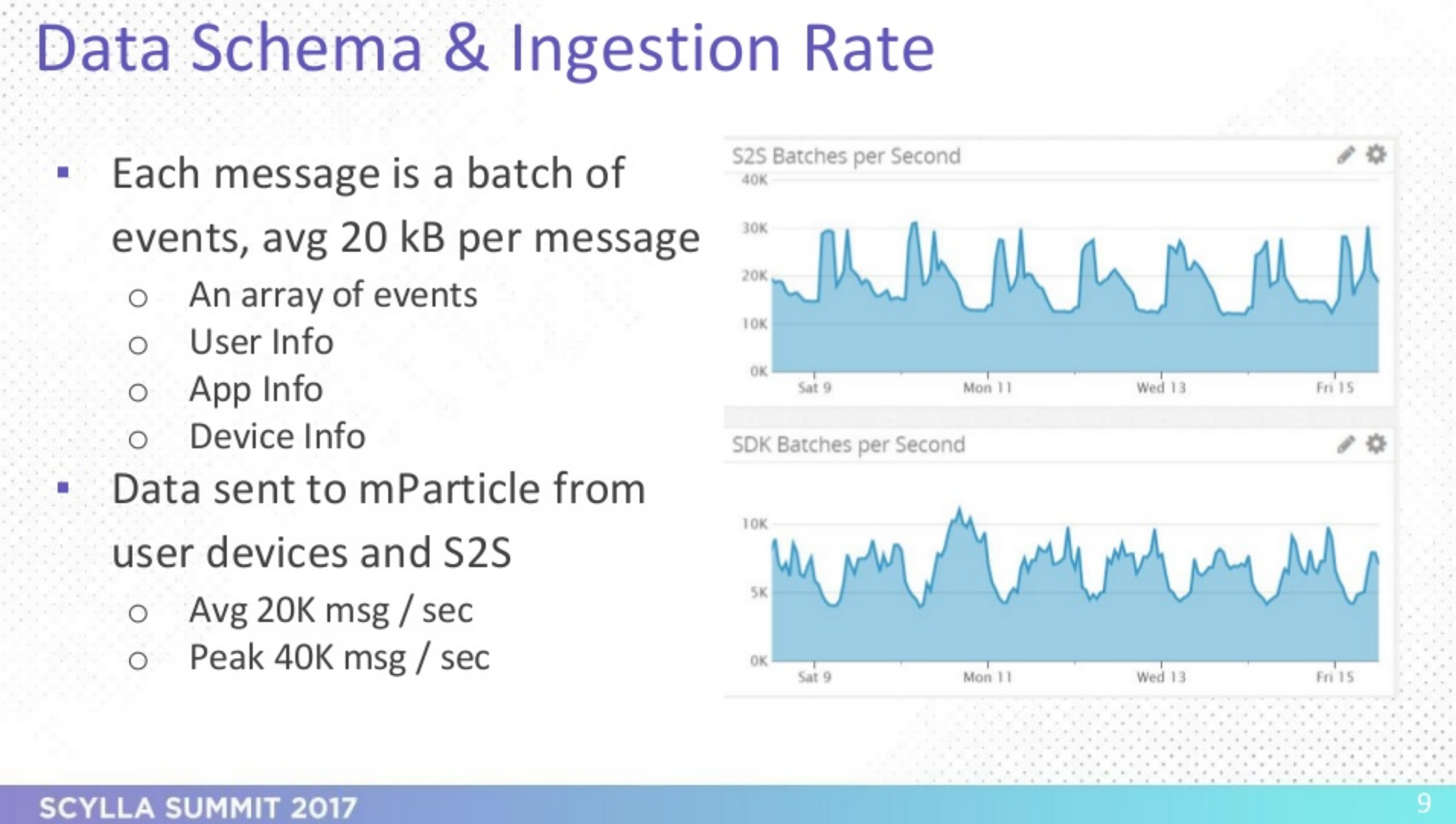
The company’s monthly data volume breaks down to 50 billion batches or 100 billion events at 150 TB of binary data added to Amazon S3, which translates to 10,000 – 40,000 messages per second. In order to effectively process all events through mParticle’s rules engine, the SLA requires that:
- All data must stream in and out of mParticle in real time;
- mParticle must handle various types of data load;
- mParticle remains fully available;
- Each brands’ data pipeline must be supported at all times by extremely low read/write latency – with no backlogs.
In addition, whenever the rules engine changes, all historical data is queried and reprocessed, creating an additional load.
With high read and write throughput, horizontal capability, wide adoption, and a proven track record, Nayden found that Apache Cassandra fit the bill at the time, so, with low startup costs, the team used Apache Cassandra through Q4 of 2016.
However, some pain points quickly became evident. First, compactions, which needed to be run with increasing frequency over time, created a bottleneck and a death spiral.
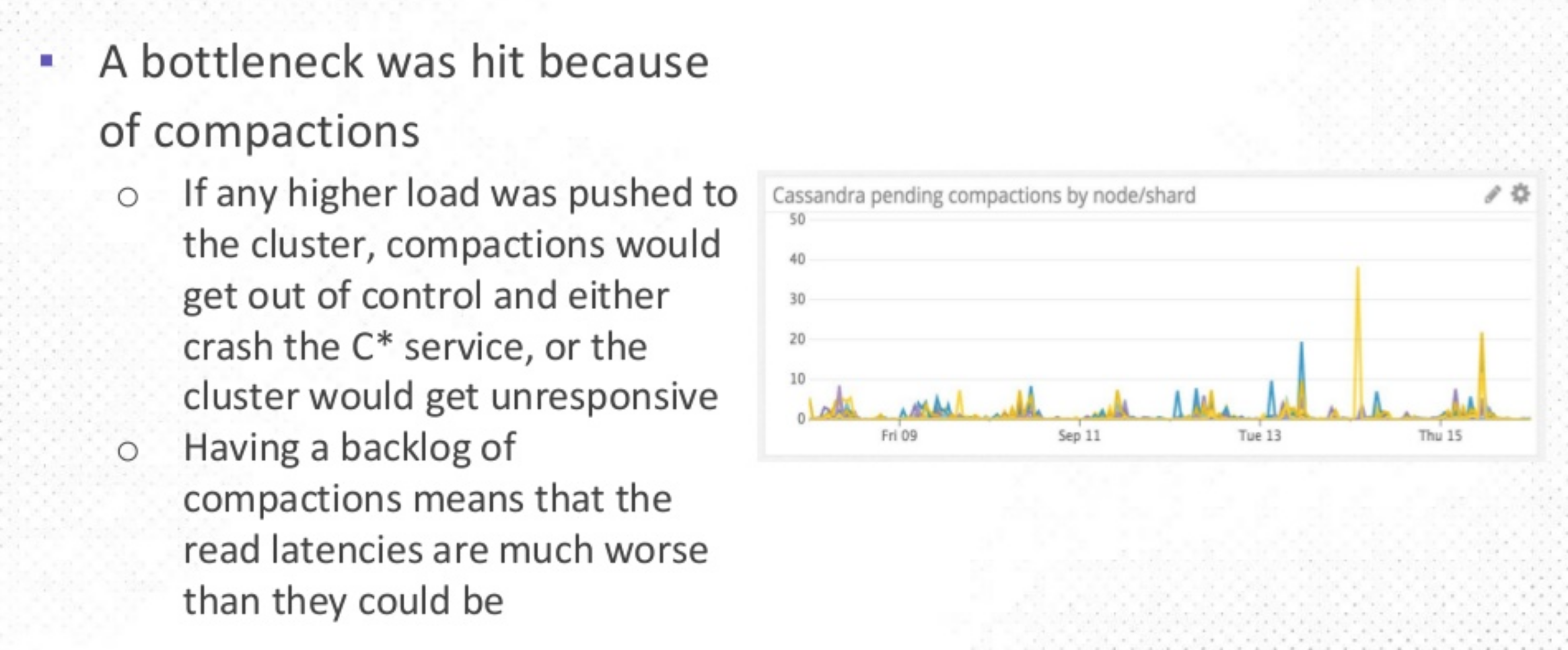
Over time, the more often compactions needed to be run, the more latency and availability were impacted, until eventually, the SLA was unsupportable. One customer’s 2-3 hour batch load ended up taking 20 hours (on a good day).
There were other problems as well. Nayden explained that a lot of human labor was required for constant JVM tuning, and with a lack of affordable support, the team ended up with an overcomplicated setup that was nearly impossible to modify and scale. Anticipating a 3x growth with customers not yet onboard, something needed to be done.
Enter ScyllaDB. Months previously, a member of the team attended a previous ScyllaDB summit and was very impressed with the product.
The team decided to engage ScyllaDB as soon as version 1.0 was released. Real data was tested on the same hardware on both ScyllaDB and Apache Cassandra. What they found was:
- ScyllaDB is compatible with Apache Cassandra, requiring no code or schema changes.
- ScyllaDB is written in C++. Nobody likes tuning a JVM.
- ScyllaDB is extremely easy to configure, and self-tuning during installation.
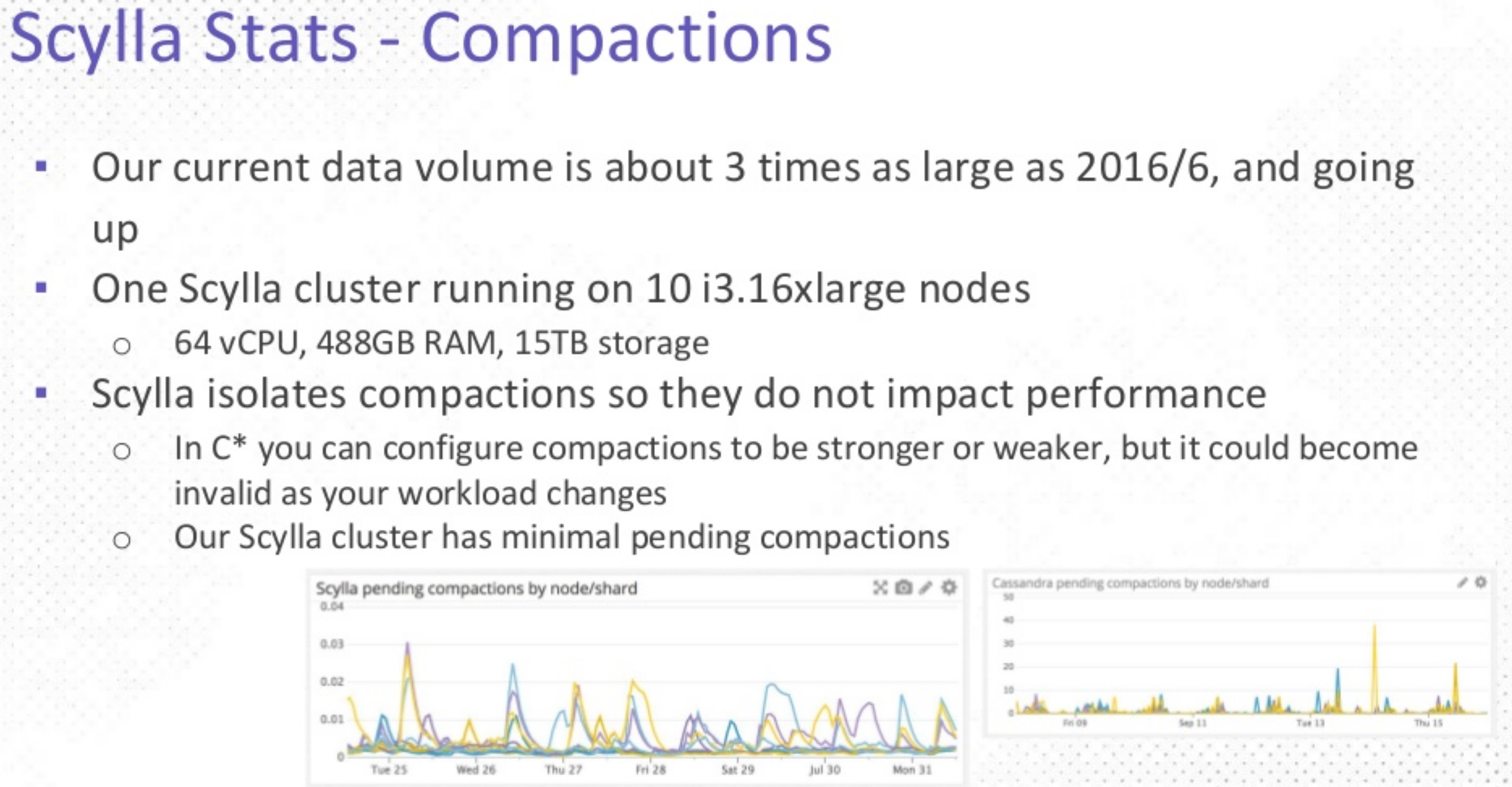
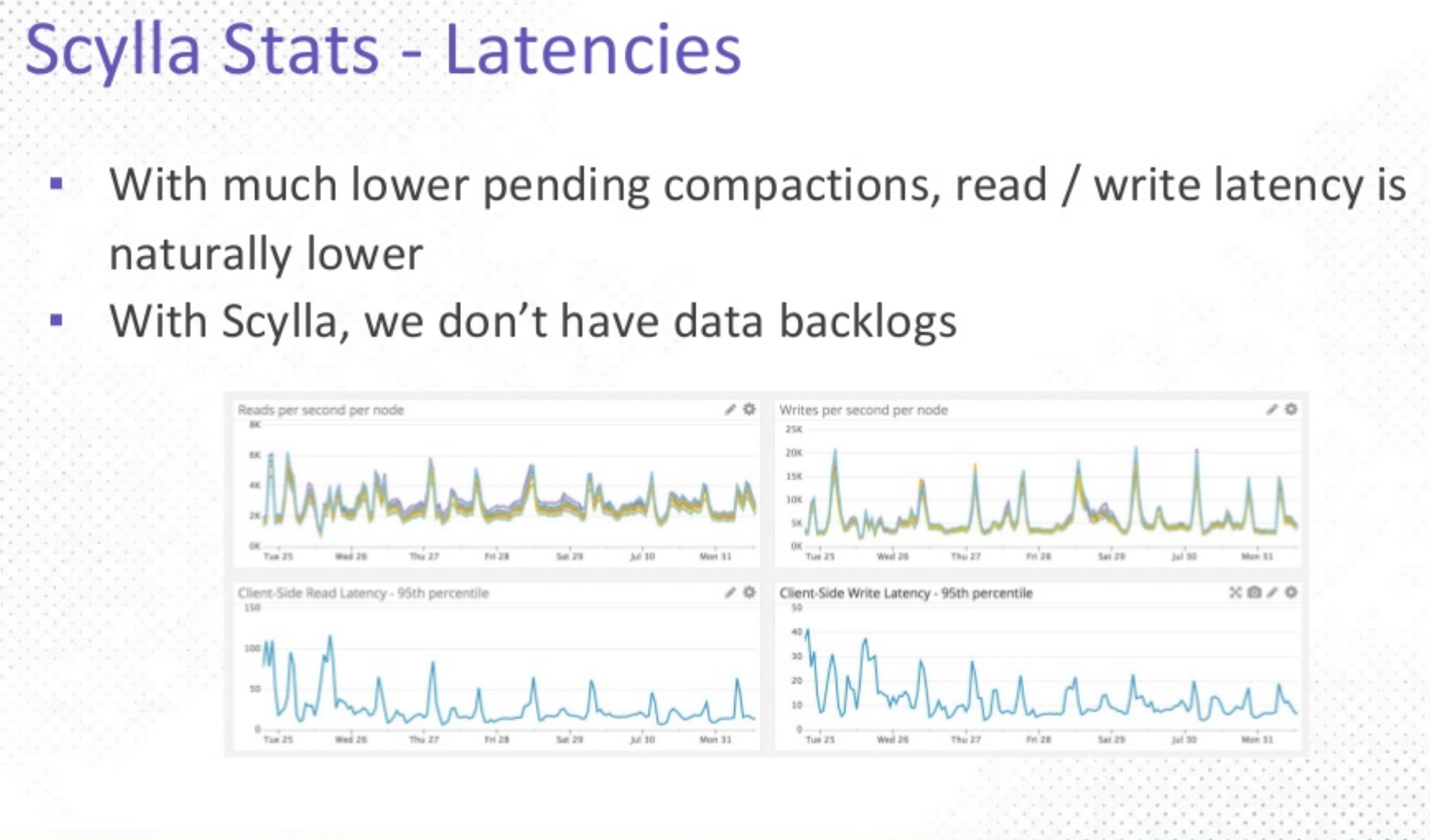
- ScyllaDB supports a near-zero compaction backlog with mParticle’s requirements.
- ScyllaDB comes with highly responsive and knowledgeable support.
Finally, Nayden offered a few words about ScyllaDB’s support, which was with the team all the way. ScyllaDB support provided “…100% each of product competency, underlying infrastructure proficiency, with professionalism and dependability.” While tuning ScyllaDB and the underlying OS to squeeze every little bit of performance out of the cluster, mParticle never heard the words “that’s not our problem.” With “fierce dependability and dedication,” Nayden points out that ScyllaDB support team was “…one of the reasons we were so happy to migrate to ScyllaDB—nothing but outstanding support.”
Watch the video at the beginning of this post, or view the slides below to learn more:
Which mission-critical functionality do you want to improve?
Check out our download page to learn how to run ScyllaDB on AWS, install it locally in a Virtual Machine, or run it in Docker. Or, spin up a ScyllaDB cluster for a free test drive.


