




How do you quantify how effective your database system is in terms of throughput, latency and CPU usage? And what do you do when there is a risk to your SLA? These were the main questions explored in Lukasz Pachiarek and Szymon Szymanski of Allegro’s talk at ScyllaDB Summit 2017.
Allegro is currently the biggest e-commerce company in Poland and one of the biggest in Central and Eastern Europe. With 14 million monthly users, 750,000 items sold on the platform daily, and 47 million mobile searches monthly, they needed a system that could handle 250,000 operations per second with a read/write ratio of 8:2. Lukasz and Szymon, leading the database team, also began to question the hardware and maintenance requirements of their current 44-node Apache Cassandra cluster along with the question, “Does our latency meet our service level agreement?”
Being Java-based, Apache Cassandra showed issues with performance and latency that Lukasz and Szymon, both experienced database admins, believed risked violating their 100-millisecond latency SLA. For starters, garbage collector pauses on Apache Cassandra were causing very slow response times, but that’s not all. Maintenance tasks (restarts, repairs, joins, and cleanups) were dismally slow. These same operations often had serious and unpredictable impacts on cluster performance.
Java performance tuning also proved to be very time-consuming for the team. Although the group uses speculative execution, there were latency spikes that made planning and latency targets difficult.
Lukasz explains that Allegro’s users expect very fast response times and given that “Amazon found that every 100 milliseconds of added latency cost them 1% in sales,” they needed a better solution. In 2016, they attended their first ScyllaDB Summit and decided to give ScyllaDB a try.
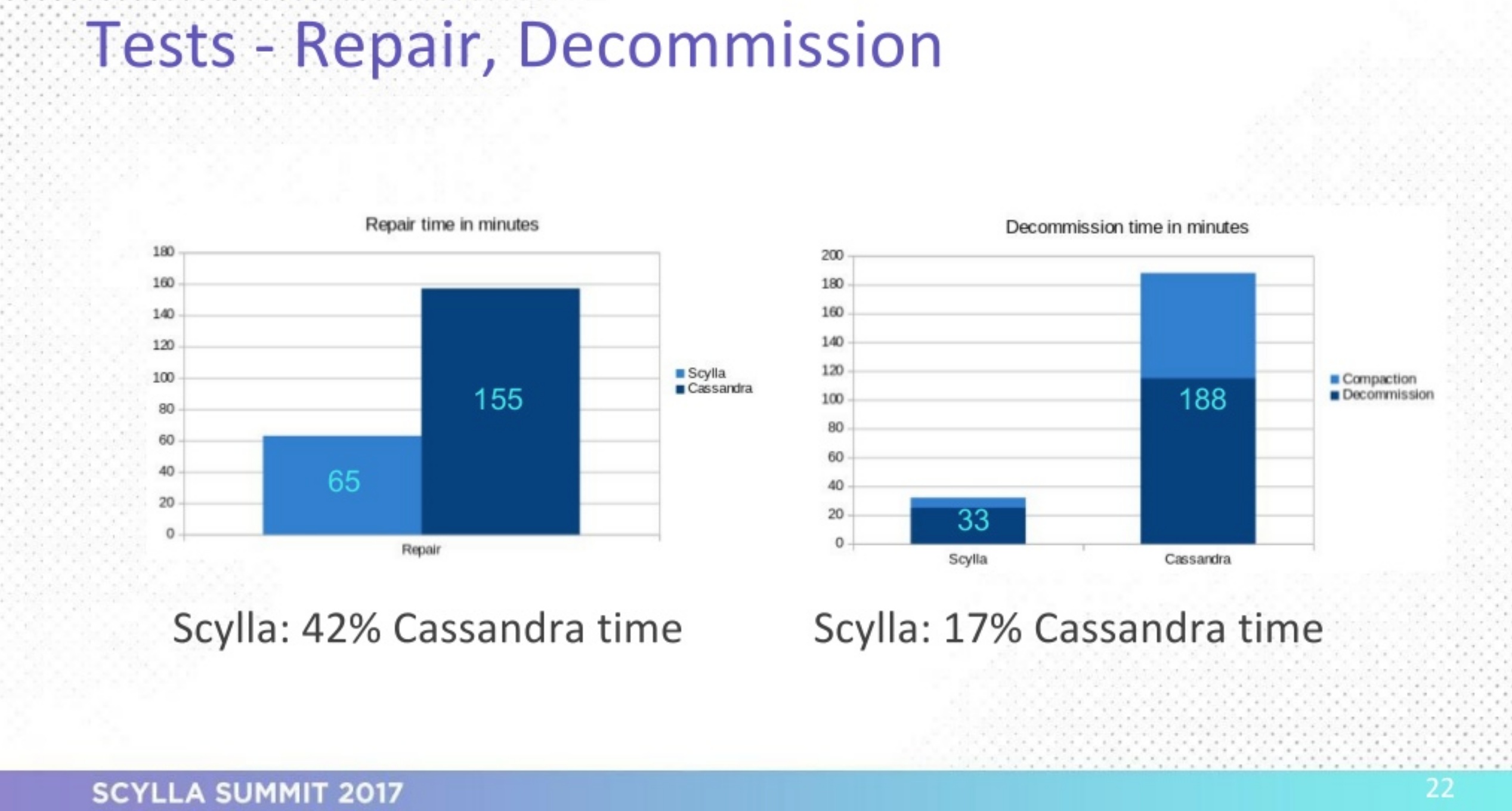
The pair decided to evaluate ScyllaDB based on maintenance task performance (node joining, node commissioning/decommissioning, cleanup, and repair) as well as production traffic. They also wanted to see if they could get better performance out of a ScyllaDB installation that was only half the size of an Apache Cassandra installation.
What they started to discover was quite remarkable:
- Cleanup and join: ScyllaDB took 66% as long as Apache Cassandra to run cleanup, and 23% as long as Cassandra to join new nodes
- Decommissioning nodes: When it came to decommissioning time for nodes, the difference was huge. Half an hour for ScyllaDB vs. over 3 hours for Cassandra
- Repair: ScyllaDB responded twice as fast as Cassandra
Using ScyllaDB, they got rid of latency spikes as well. Szymon points out, “If you look at the response time of ScyllaDB, it’s still a straight line. You cannot see those spikes.” In production traffic, ScyllaDB outperformed Apache Cassandra in almost every measure.

From these results, the team calculates a Hardware Reduction Plan (HRP) factor of three, meaning:
- Allegro can replace three Apache Cassandra nodes with a single ScyllaDB node
- Allegro can use a 16-node ScyllaDB cluster in place of their 44-node Apache Cassandra cluster
- Even with these reductions, Allegro can still get much better response time from the ScyllaDB Cluster
Want these same latency savings?
Spin up a ScyllaDB cluster for a free test drive. Or, see our download page to learn how to run ScyllaDB on AWS, install it locally in a virtual machine, or run it in Docker.



