



In the context of graph databases, the performance of your storage backend is paramount. In the world of edges and vertices, graphs (and the data required to support them) can grow exponentially in a point-to-point fashion.
In their talk at ScyllaDB Summit 2017, Ted Chang and Chin Huang, both engineers at IBM, decided to add ScyllaDB to the mix of backends which has traditionally included Cassandra and HBase. They ran test scenarios which covered high volume reads and writes, and provided comparative test results for the three backends, along with lessons learned for each.
The group supports JanusGraph for Compose, with the Gremlin query language. A graph database typically consists of vertices (points) and edges (lines) connecting the points to show relationships between them. A graph is stored as a collection of vertices with their adjacency list. According to Wikipedia, an adjacency list is “…a collection of unordered lists used to represent a finite graph. Each list describes the set of neighboring vertices of a vertex in the graph.”
In their performance evaluation, the duo looked specifically at the following three scenarios:
- Inserting vertices – inserts – write operations
- Inserting edges – searches and updates – a mix of read and write operations
- Graph traversal – queries – read operations

According to Ted, “Our server is very powerful, more than the requirement of any database here.” At 28 cores, we don’t doubt that! The pair emphasized that they used Prometheus and Grafana specifically for monitoring ScyllaDB.
The topology of the setup consisted of JanusGraph connected to each database backend: a 3-node cluster of HBase, Cassandra, and ScyllaDB in turn. The tests were driven by a load injector designed by the pair; with test data read from CSV files, a REST API handled query load. JanusGraph’s own JAVA API was used for inserts and updates.

On the first test, ScyllaDB had the highest throughput at 272K Vertices inserted per second compared with 202K for HBase and 93K for Apache Cassandra. By their observations, ScyllaDB also did very well out of the box with very little tuning required. On ScyllaDB, the CPU was saturated at > 80%, compared to HBase’s ~15% and Apache Cassandra’s ~50%. Apparently, vertical scaling was attempted to improve throughput on HBase, but these hardware additions did not affect throughput.
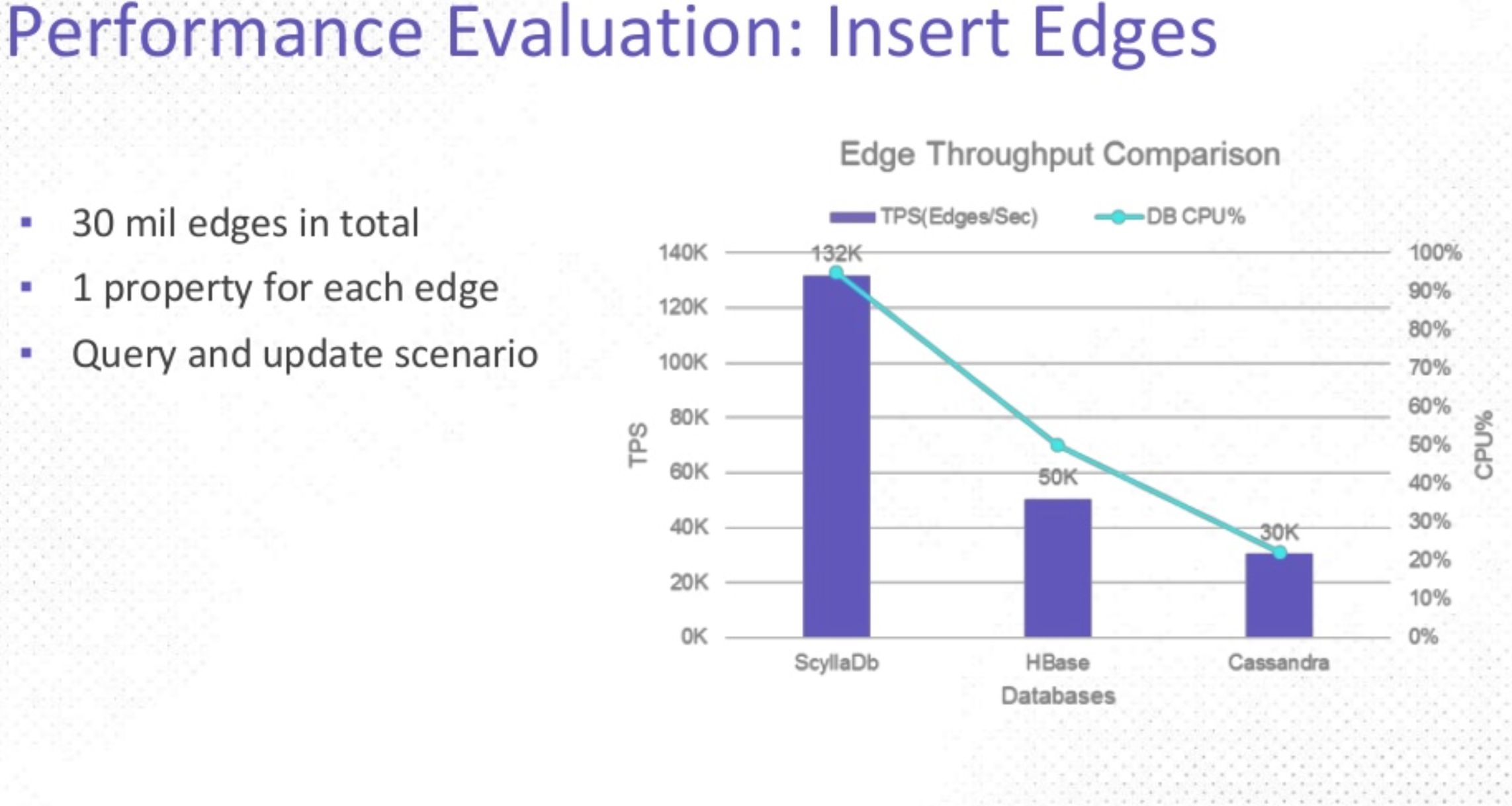
In the second test, ScyllaDB once again offered the highest throughput at 132K edges per second compared to HBase’s 50k and Apache Cassandra’s 30k. Similarly, ScyllaDB outperformed the other two in terms of CPU saturation, with ScyllaDB’s CPU achieving 90% compared with HBase at ~30% and Cassandra even lower.
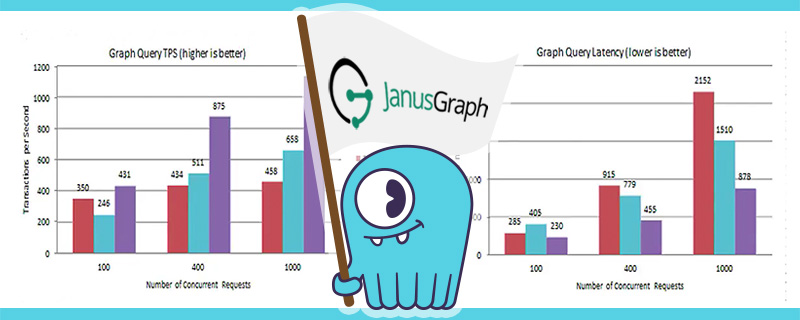
As the last trial, the graph traversal test used a different dataset than the first two tests, and had a slightly different objective: given a complex query, Chin said, “..let’s see what we can handle in terms of transactions per second.” With 100 users in the database, the goal is to find followers who have retweeted a tweet.
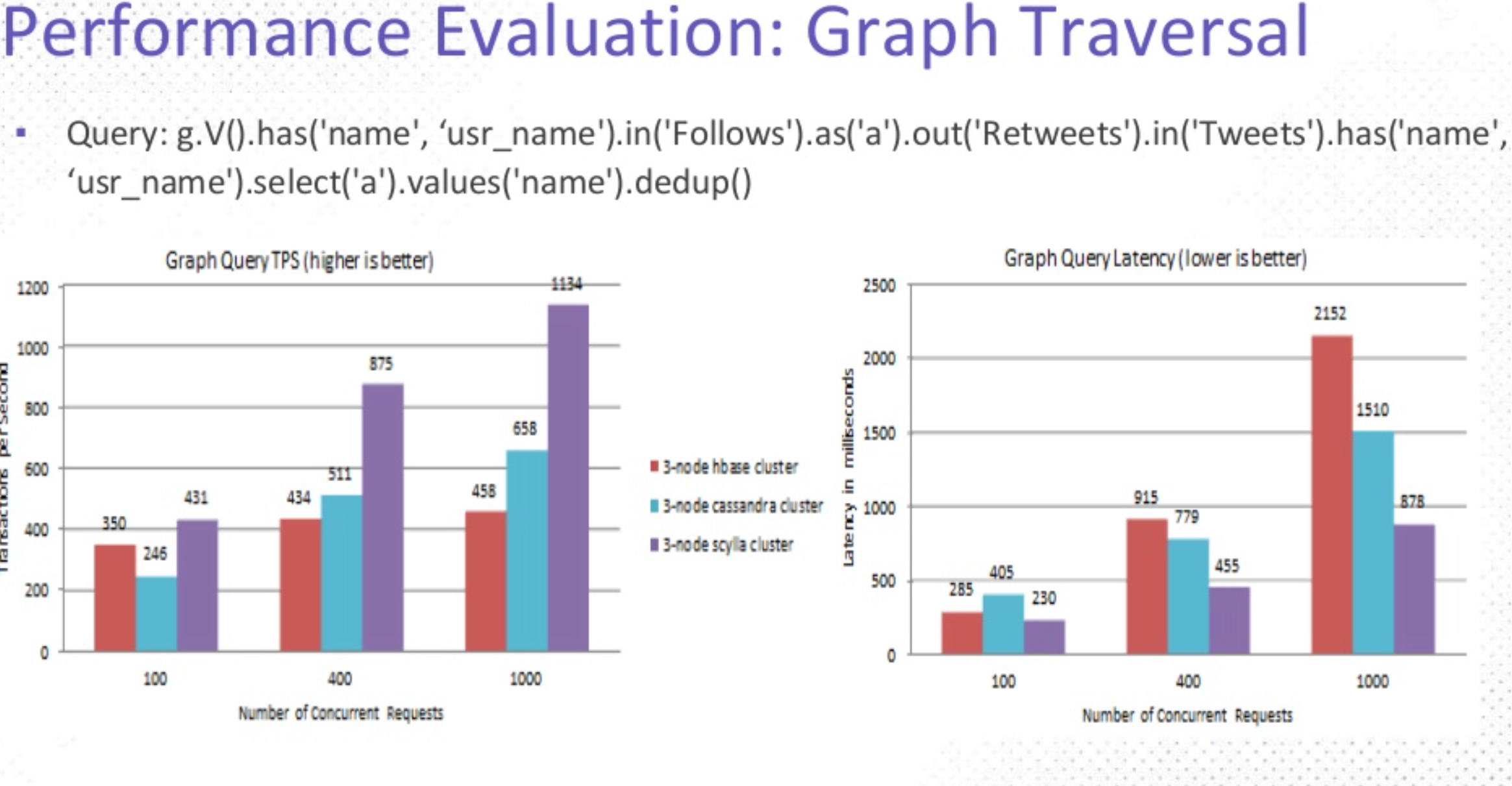
This trial resulted in two charts: on the left was throughput, measured in transactions per second, where higher is better; on the right was latency, where lower is better. On throughput, ScyllaDB on average, outperformed HBase by an order of 3 and Apache Cassandra by 2. However, when looking at latency, ScyllaDB predictably did almost the inverse, halving the latency measure of the other two backends, with only ⅓ of HBase’s latency at higher loads.
In Ted’s own words: “…ScyllaDB becomes the clear leader.” The pair concluded with some lessons learned.

Given that ScyllaDB is designed to saturate CPUs with the goal of efficiently using resources, our high CPU utilization under heavy load is actually what you’d expect!
Watch the video at the beginning of this post, or view the slides below to learn more:
Improve your backend performance!
Check out our download page to learn how to run ScyllaDB on AWS, install it locally in a Virtual Machine, or run it in Docker.



