




They may not have time machines or lightsabers, but they do have the Higgs-Boson and they’re looking for the most scalable framework with which to study it. At CERN, the problem of the day is scaling out their AliEn global file catalog and their plans may well involve ScyllaDB.
At ScyllaDB Summit 2017, software engineer Miguel Martinez Pedreira described his unique challenges setting up and running the distributed computing infrastructure meant to support A Large Ion Collider Experiment (ALICE), one of seven experiments on the Large Hadron Collider at CERN. In service to the activities of CERN, which range from understanding the constituent parts of matter and theorizing about the nature of matter during the first moment of the Big Bang to developing new technologies (the World Wide Web and pet-scans), there is clearly a need for a computing infrastructure that can scale massively.
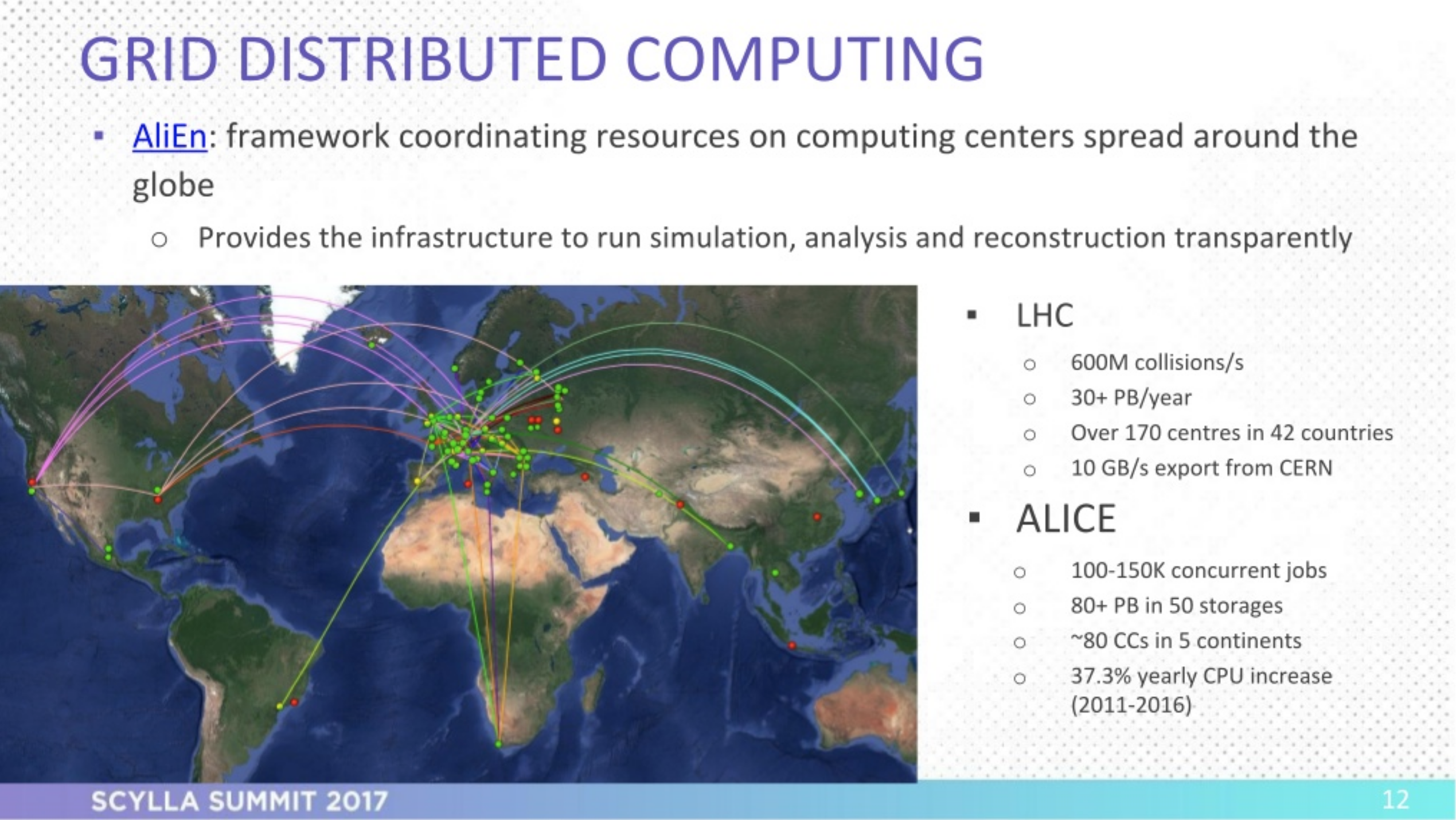
That computing infrastructure is called AliEn, and a key piece of it is the (currently) MySQL-based file catalog. At 12 Billion entries, the powerful database master (1.5 TB RAM, 4+ TB on disk) currently takes more than 4 hours to dump data and 2+ days to restore it.

What’s more, their MySQL infrastructure lacks the ability to scale horizontally. Miguel points out that their future needs will be far more extensive, requiring 5x more computing resources to sustain 10x more files in the near future. Although it would require a paradigm shift, the team is looking for a solution that is scalable by design.
On the premise that Apache Cassandra and ScyllaDB would fulfill some of their base requirements (high availability, no point of failure, horizontal scalability, performance, and tunable consistency), he and his team at CERN decided to test and compare both.
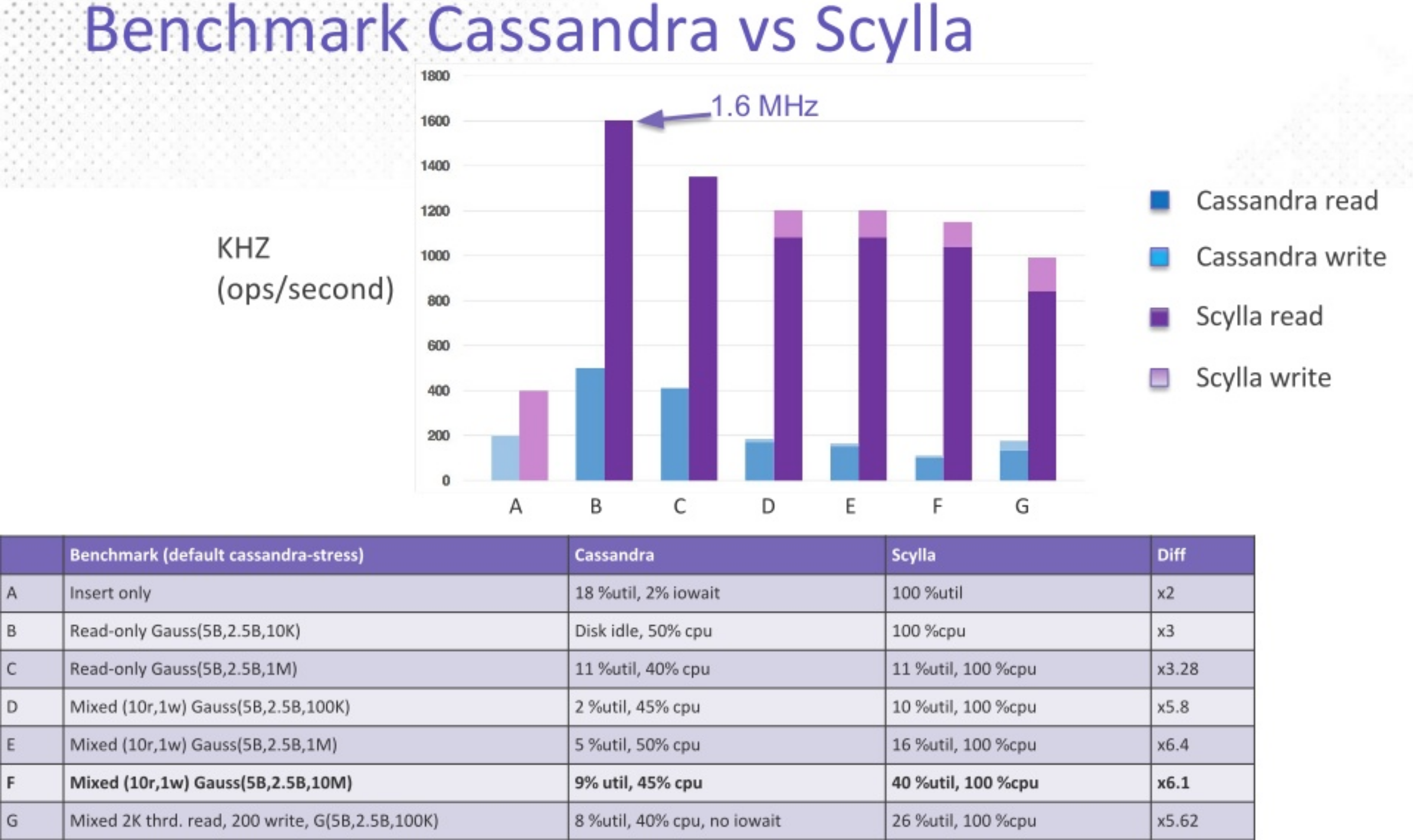
Some key takeaways? ScyllaDB offered up to 12x the throughput of Apache Cassandra while doing a better job to saturate resources. In the load test Miguel highlighted, ScyllaDB achieved 40% disk usage (compared to Apache Cassandra’s 9%) and 100% CPU usage (compared to Apache Cassandra’s 45%). Additionally, each operation they benchmarked (nodetool repair and adding/removing/replacing nodes) was significantly faster in ScyllaDB.
Promising to follow ScyllaDB’s evolution, Miguel concluded: “We have a complete promising model for a future-proof catalog.”
Want to learn more? Watch the video above or check out the slide deck below.
Want to try out ScyllaDB? Spin up a ScyllaDB cluster for a free test drive. Or, see our download page to learn how to run ScyllaDB on AWS, install it locally in a Virtual Machine, or run it in Docker.



