ScyllaDB’s internal developer conference and hackathon was very informative and productive. Here we’ll share with you the project we came up with, which involves implementing Binary Large Object (“blob”) support in ScyllaDB along with the S3 API and integration with many interesting features.
Motivation
It started with simple ideas like how cool it could be to allow accessing ScyllaDB with an S3 API that is popular, simple and for which there are a lot of open-source tools that support it. Why can’t we store large objects in our database? Users sometimes want to store media files in the database. Could we implement that in a convenient way? It turned out we could.
From that moment the flywheel of our imagination started to spin faster. We dreamt about possible applications and consequences of that. It turned out that storing large objects plays perfectly well with the S3 API support. From that, we moved far beyond what we could imagine at the beginning. S3 enabled ScyllaDB to support browser access. Browser access pushed us to the idea of streaming live video streams right from the database via our S3 frontend and we came up with the necessity of ranged reads support.
Then it turned out we could expose our work as a filesystem via Filesystem in Userspace (FUSE) and we made it happen. At that moment we truly understood the potential of what we were doing. It was like a vision of boundless freedom, a fresh breath of imagination, a borderless world of what could be achieved. In that process of collective collaboration, a feeling of something big that we are doing, we came up with absolutely crazy ideas like why would we not create a new compaction strategy for our large objects? Or why can’t we expose CDC streams via S3 and connect ScyllaDB to Apache Spark as a Data Source?
It was like we were reinventing ScyllaDB from new perspectives and it was so appealing to look at how seamlessly everything integrated together.
Everything we do we do because we love what we are doing. This project happened because we were able to summon all of our passion, face the unknown, and build together via a process of creativity in which we all became something more than just by ourselves. The further we proceeded the more it felt like we were going in the right direction. We had fun. We felt passionate. It was inspirational and that’s how great things must be born.
The Team
Our team, clockwise from the upper left: Developer Evangelist
Ivan Prisyanzhnyy, Software Developer Raphael S. Carvalho (or at least
the top of his head), Distinguished Engineer Nadav Har’el,
Software Developer Takuya Asada (in silhouette) and Software Engineers
Marcin Maliszkiewicz and Piotr Grabowski.
Collectively our team represented some of the most senior engineering talent at ScyllaDB (Nadav, Raphael, and Takuya have both been with the company for more than seven years) and some of the most recently added (Piotr G joined in 2020). The team spanned the world from Brazil, to Poland, Russia, Israel and Japan.
One of our project authors suddenly found himself in a situation where he was not able to participate in the project right before the start. So the project was at risk of not happening at all.
But we still wanted to give the project a try and decided to move forward with it. We were surprised when on the first day of the Hackathon he came back to us sharing that everything was okay and the circumstances had changed and he was able to participate. It was the first and best news in the long queue of what followed.
Implementation
The implementation consists of 4 sub-projects:
- A Python proof of concept (PoC) that verifies that the data model works and the API is correct
- A production-grade implementation in C++ based on the Alternator source code fork,
- An Object-Aware Compaction Strategy, and
- Change Data Capture (CDC) S3 support.
The foundation for it is the data model that allows for efficient implementation of the required S3 API and exploitation of ScyllaDB internals.
Right next to it stands the organization of storage of large binary objects. It’s simple to imagine at least two approaches to store large objects: one is to split them into small pieces and another one is to store only the metadata in the database and data on the filesystem itself. There are different cons and pros for both. For the PoC we decided to go with splitting blobs into smaller pieces — chunks — and storing them right in the database.
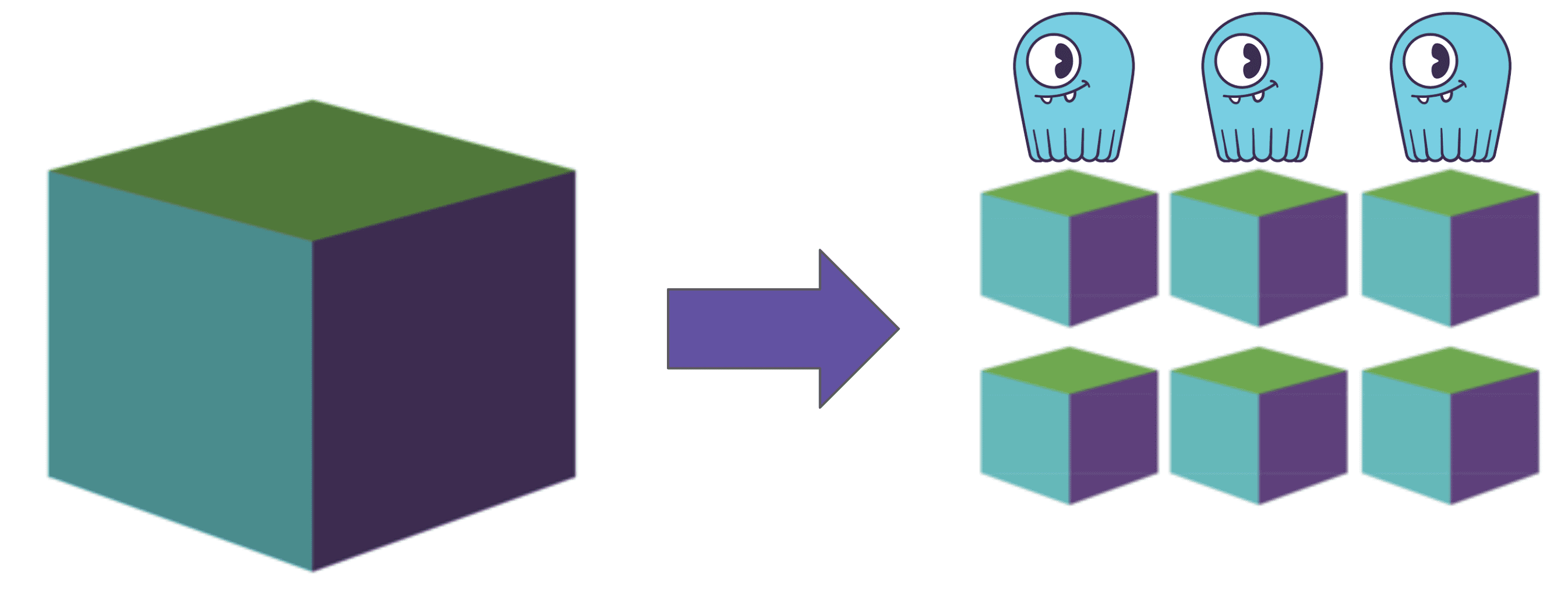
The process of splitting a blob into chunks is known as “chunkifying.”
No, we didn’t make that up.
When a user wants to upload an object we split it into many small pieces called chunks. Every chunk corresponds to a cell. Cells work best when small so we keep them around 128KB size. Then cells can be organized into a single partition of a larger size. For example, a partition can be 64MB. An advantage of that is that the partition can be read sequentially with a paging and a sufficiently large data piece will be served from a single node. This approach allows to efficiently balance cells and partitions sizes and connections to nodes distribution.
The key for a chunk can be calculated based on the chunk number in the blob. It makes it possible to access chunks without an additional index and allows greater parallelism in uploading / downloading.
When a user wants to read an object we just need to calculate the chunk to start from and start streaming data from the corresponding partition. It’s that simple.
Now knowing all those assumptions about the large object’s data that are usually a) immutable b) big c) stored in pieces that span continuously it is possible to reorganize the existing compaction strategy to make storage much more efficient for both reads and writes.
It’s somewhat obvious that STCS or LCS are not perfect for storing BLOBs (the object’s data). Using our knowledge about data we can reduce amplification factors by much. Basically, we can get rid of compaction in the old sense. Our new Object-Aware Compaction Strategy (OACS) has the following characteristics:
- It keeps pieces of a certain object together. SSTable stores pieces only of a single object such that it’s much simpler to locate the required partition. This makes writing, reading, and garbage collecting objects much cheaper than with other compaction strategies. A user specifies a column to tell the compaction strategy what parts belong to the same object.
- Flushing a memtable keeps different objects in separate SSTables from the beginning so no further sorting is required.
This approach gives the following advantages:
- It allows for optimal write performance, because compaction will not have to rewrite any given object over and over again.
- It allows for faster reads, because we can quickly locate the SSTable(s) which a particular object is stored at.
- It allows for more efficient garbage collection, because deleting a given object through a tombstone will not require touching the other existing objects.
As always that was not enough for us. We also implemented the multipart upload to support scenarios of working with very large objects. It’s a S3 feature which allows the user to upload up to 10.000 parts of an object, up to 5 terabytes in total size, in any order with ability to re-upload any part if something goes wrong. It’s worth to note that after finalizing the upload you need to stitch the parts together. To achieve that one can reshuffle the data chunks or keep using the auxiliary metadata information at the expense of extra database lookups. For the PoC we decided on the latter which means that the finalization step is very fast even for huge files.

Was it Enough?
We used the phrase “Was it enough?” so extensively in our final presentation that it became our slogan and went viral internally. It was emblematic of our team, repeatedly one upping our accomplishments and our goals during the hackathon.
We only had the length of the hackathon to do our work, but consider all that we accomplished in that short time. We made ScyllaDB S3 support that enabled following usage scenarios:
- Use ScyllaDB as a Large Binary Object storage (upload file up to 5TB size as in AWS S3)
- Use ScyllaDB via S3 API and tools like AWS S3 with MPU
- Use ScyllaDB as a file system via s3fs (FUSE)
- Access ScyllaDB data with a curl or browser
- Stream media content from ScyllaDB directly via the S3 frontend
- Use Hadoop or Spark to read data right from the ScyllaDB S3 API
- Use CDC log to write right to the ScyllaDB S3 API
- Connect ScyllaDB CDC log with Spark
While it’s still a long way off before our work shows up in a released version of ScyllaDB, here’s a sneak peek at what we were able to accomplish with our S3 API:
If you want to follow along with our current and future work, you can find the code on Github here: https://github.com/sitano/s3-scylla/tree/scylla.
If you have more questions, we invite you to ask us on our Slack channel, or contact us directly.
We’d also like to invite you to our upcoming ScyllaDB Summit, where you can learn about the other features we’ve been working on, and from your industry peers on how they’ve used ScyllaDB in their own organizations.