Today we are releasing a new data integrity testing suite for the open source NoSQL database community. Those who will have the most direct utility for this software will be those testing ScyllaDB and Cassandra databases, or, more broadly, other CQL-compliant databases. This could either be software development QA teams working on their own software or for users performing acceptance testing (DevOps, SREs, etc.). The design pattern can also be of interest to others building software system testing suites.
To ensure database integrity and reliability in a distributed database, it is vital to test for data correctness or data loss. Writing a database is complicated. A distributed database with a rich API is an even more daunting task since there can be so many patterns of data access, lots of different failure patterns and the database can host enormous datasets with all kinds of schemas. As we add more features and functionality, a framework like Gemini allows us to proceed in a fast pace with a low data regression risk.
Let’s presume you want to make sure that there is no data integrity/loss or corruption when you develop a new ScyllaDB release. You just want to know that everything you believe you wrote actually got written and reads return identical answers. If there are errors detected, you can deal with fault isolation and root cause analysis later. This is where Gemini comes into play.
Readers familiar with the Jepsen suite will find it similar. Jepsen concentrates on database transactional guarantees and consensus systems behavior in the face of distributed failures. Gemini together with ScyllaDB Cluster Test (SCT) have a similar concept and chose to highlight on huge datasets and various fuzzy data operations. Gemini and SCT loop through data modification, event interruption and data validation steps in a loop.
Goal & Definitions
Gemini is a testing tool created by ScyllaDB engineers and used internally in our quality assurance processes to find hard-to-trigger bugs that can cause data corruption or data loss in our Enterprise and Open Source database releases. Gemini accomplishes this by applying random testing to a system under test and validating the results against a test oracle. While the primary goal for Gemini at ScyllaDB is to test our own database, more broadly it can also be used to test other CQL-compatible databases such as Apache Cassandra, or test two different CQL-compatible databases against each other (such as Cassandra and ScyllaDB) to ensure compatibility of behavior.
System Under Test
In our case, system under test (SUT) is the term for the ScyllaDB cluster that is being inspected. For example, it can be a development version of ScyllaDB that needs to be validated for a release. The goal of running the Gemini tool is to find bugs in the SUT.
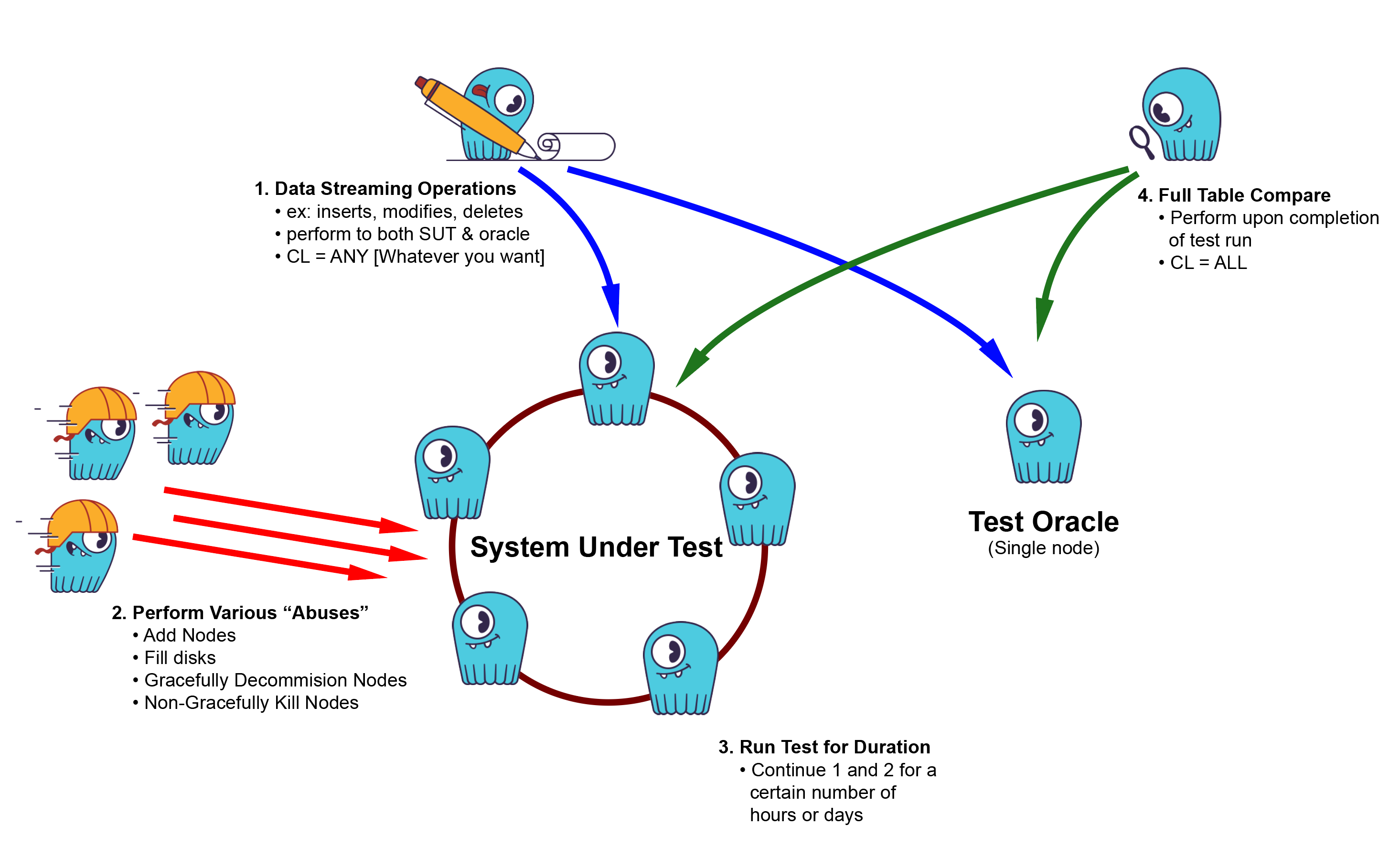
Topology for a typical Gemini test setup. Note that the test oracle is depicted here as a single node; it could also be a cluster.
Test Oracle
When you have a system under test, what do you compare it to? The comparative system is called the test oracle. (The term has nothing to do with that large Fortune 100 database company headquartered in Redwood City, California.) The test oracle will perform in an expected, predictable manner and is known to produce correct results.
For instance, start with a well-known, stable prior version of a product. It can be run on a small cluster, or topologically simplified to run on a single-node cluster (albeit a large one to handle the load), to isolate system components such as caches, sstables, and flushes.
Ideally, if you operate on both systems in the same manner, the system under test should produce the same exact results as the test oracle. If there is any difference in results between the system under test and the test oracle, for whatever reason, the test has failed.
Design
Gemini is a program that performs automatic random testing to discover bugs. The tool connects to the system under test and a test oracle using the CQL protocol. At high-level, Gemini operates as follows:
- Generates random operations using the CQL query language.
- Applies the operations to the system under test and the test oracle.
- Validates that the system under test and the test oracle are in the same state.
In the absence of bugs, the system under test and the test oracle are expected to be in the same client-visible state. That is, after mutating both databases in the exact same way (with INSERT, UPDATE, or DELETE), subsequent CQL queries (with SELECT) are supposed to return identical result sets. If Gemini detects a difference between the result sets from the two systems, there’s a difference in behavior between the two systems. As we assume the test oracle to behave correctly, the problem is in the system under test. Of course, in practice, test oracle can sometimes also be at fault, but even then, a difference in result sets is an indication of a problem that needs to be analyzed and addressed.
Gemini can also be run in an “oracle-less” mode, where you can just generate random workloads and throw abuses at a standalone system under test as quickly as possible to see if something breaks.
Implementation
Gemini is implemented with the Go programming language, using the gocql driver to connect to CQL clusters.
A Gemini run starts with the execution of the program. For a test run, Gemini needs a CQL schema (i.e. CREATE KEYSPACE and CREATE TABLE). The tool can generate one for you or users can specify the schema using an external file. Gemini uses the schema information to produce random values for every column in every table in the schema. There are various knobs in the tool to control the kind of data generated. Gemini is able to generate tables with small and large partitions, for example.
After schema creation, the Gemini assigns partition key ranges between N concurrent goroutines to only a single goroutine update and read a given partition at a time. The tool then starts to generate mutation operations or validation/check operations at random. A mutation operation changes the state of both databases and a validation/check operation queries both databases and that the results match. If there’s a mismatch, the tool reports an error to the user together with the CQL query that we detected a difference with.
At a high-level, the Gemini main loop looks as follows:
while (1) {
generate a random CQL operation
apply to both clusters
validate the data
}The generated CQL operation can either be a mutation or a read query. Mutations change the state of the systems and read queries are used to verify the state. During the while loop a nemesis disruption can be applied on the SUT.
A random read CQL operation can be, for example:
SELECT a, b FROM tab WHERE pk = ? AND ck = ?
SELECT a, b FROM tab WHERE pk = ? AND ck > ? LIMIT ?
SELECT b FROM tab WHERE token(pk) >= ? LIMIT ?
SELECT b FROM tab WHERE token(pk) >= ? AND c = ? LIMIT ? ALLOW FILTERINGwith many more variations trying to use indexes, ordering, etc.
The mutation CQL operations are somewhat simple: either an INSERT or a DELETE, decided at random. The validation/check operations are slightly more complex and allow variation between a single or multiple partition queries and clustering range queries.
We also run another program during the Gemini runs to perform non-disruptive nemesis operations. For example, the program forces the cluster to perform major compactions, repair, and so on, while Gemini is running. The idea is to exercise edge cases in the ScyllaDB code to find difficult-to-trigger bugs. ScyllaDB Cluster Test framework has many additional disruptive nemesis tests and we intend to apply most of them to the Gemini suite.
Data Generation
The data generated by Gemini is inherently random. Gemini generates data for all the CQL types as well as synthetically generated UDT. There are some limits on the size of the data imposed by the type system itself and for some types such as text we have introduced artificial limits to avoid some extreme sizes. Gemini generates randomly distributed partitions. That means that the data will be randomly affected by both writes and reads. This is often a good outset but sometimes you may want to test other things like for example how ScyllaDB behaves with hot partitions. To support this Gemini allows for the user to decide between 2 other distributions aside from the default random namely zipf and normal distributions.
Complications
There are some inherent complications in the validation procedure. The vast majority of queries executed on any ScyllaDB cluster is based on the partition key in one way or another. There is a reason for this and it lies at the heart of how the database is designed. We use this as a simple way to avoid concurrent updates to the same data by different workers. Each worker simply gets a range of partitions upon which it operates in isolation. This works well up to a point.
For example, queries using a secondary index can potentially hit all partitions and are thus subject to a logical race, since any of the matched partitions could be updated by another worker at any given time. This would lead to a perfectly valid state but a state that Gemini would recognize as faulty simply because the results from the SUT and the test oracle differ, a false positive.
Another matter that complicates things is the fact that ScyllaDB updates changes to indexes and materialized views asynchronously in the background. This means that there is a data race between when the two systems were updated and when they are fully in sync. Solving this is not easy and the only reasonable approach currently is to simply retry the validation a few times. If a valid state is found we are good, otherwise we try again until a maximum time has passed. This can still lead to false positives because we may simply give up too soon.
Examples of Found Bugs
Gemini has already found some issues in ScyllaDB in our internal daily runs. You can find some of the issues reported on ScyllaDB’s Github issue tracker by looking at issues with the label gemini.
Reactor stall is a serious quality of service problem in ScyllaDB. Task scheduling ScyllaDB is non-preemptive and cooperative, which means internal tasks run to completion unless the yield the CPU to other tasks. A reactor stall is a bug in the code, where an internal task takes a very long time to complete without yielding, which causes other tasks to wait. This waiting increases tail latency. Gemini has found multiple reactor stall bugs in ScyllaDB by generating CQL queries that trigger edge cases. For example, Gemini found a bug in ScyllaDB, where multiple IN restrictions (that cause the result set to be a cartesian product) would be processed without yielding (see issue #5010 for discussion).
Database crashes are another serious problem. Randomized testing really shows its power in finding edge cases in the code that are not covered by our other test suites (unit tests, functional tests, or longevity tests with nemesis testing). One common class of errors Gemini has found are “out of memory” errors, which can crash the database. You can find examples of such bugs in #4590 and #5014.
Summary
Gemini is a tool for automatic random testing of ScyllaDB and Cassandra clusters. It generates random CQL operations, applies the operations to a system under test and a test oracle, and verifies that the user-visible state is the same for the two systems. If there’s a mismatch in their states, the system under test has a bug that needs to be addressed. Gemini has already found some issues in ScyllaDB, and we continue to develop the tool further to discover even more issues.
The source code to Gemini is available on Github:
Please refer to the following document for a quick start on running Gemini:
For more information about Gemini’s architecture, please refer to this document:
You can also view the tech talk we gave at ScyllaDB Summit on Gemini, including the video as well as our slides.
Bonus: Gemini Wallpaper!
If you are a fan of thorough testing of open source like we are, you can show your love by downloading our new free starry night Gemini wallpapers, perfect for your laptop or mobile.