ScyllaDB Summit 2018 was quite an event! Your intrepid reporter tried to keep up with the goings-on, live-tweeting the event from opening to close. If you missed my Tweetstream, you can pick it up here:
It’s impossible to pack two days and dozens of speakers into a few thousand words, so I’m going to give just the highlights and will embed the SlideShare links for a selected few talks. However, free to check out the ScyllaDB SlideShare page for all the presentations. And yes, in due time, we’ll post all the videos of the sessions for you to view!
Day One: Keynotes
Tuesday kicked off with ScyllaDB CEO Dor Laor giving a history of ScyllaDB from its origins (both in mythology and as a database project) on through to its present-day capabilities in the newly-announced ScyllaDB Open Source 3.0. He also announced the availability of early access to ScyllaDB Cloud. Go to ScyllaDB.com/cloud to sign up! It’s on a first-come, first-served basis.
Dor was followed on stage by Avi Kivity, CTO of ScyllaDB. Avi gave an overview of ScyllaDB’s newest capabilities, from “mc” format SSTables (to bring ScyllaDB into parity with Cassandra 3.x), to in-memory and tiered storage options.
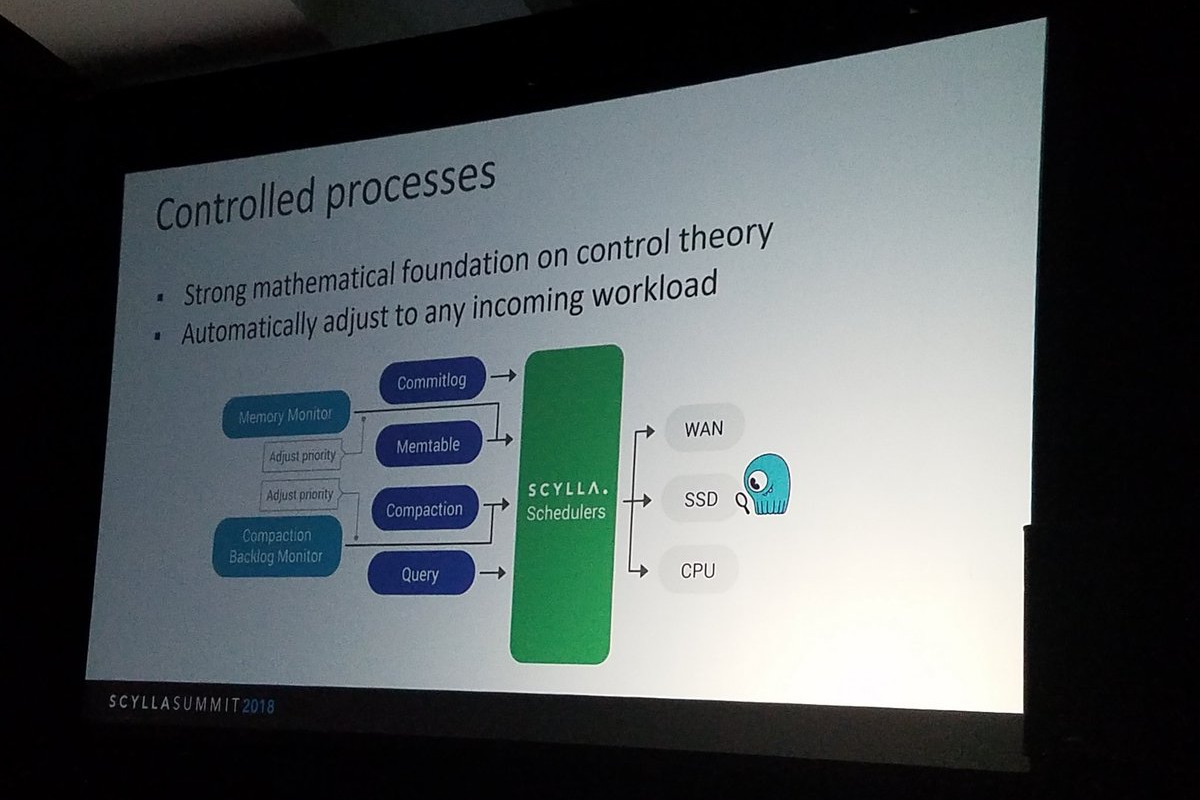
If you know anything about Avi, you know how excited he gets when talking about low-level systemic improvements and capabilities. So he spent much of his talk on schedulers to manage write rates to balance synchronous and async updates, on how to isolate workloads, and on system resource accounting, security, and other requirements for true multi-tenancy. Full-table scans, which are a prerequisite for any sort of analytics. CQL “ALLOW FILTERING” and driver improvements. Each of these features were featured at ScyllaDB Summit with their own in-depth talks — Avi just went through the highlights.
Customer Keynotes: Comcast & GE Digital
Tuesday also featured customer keynotes. We were honored to have some of the biggest names in technology showcase how they’re using ScyllaDB.
First came Comcast’s Vijay Velusamy, who described how the Xfinity X1 platform now uses ScyllaDB to support features like “last watched,” “resume watching,” and parental controls. Those preferences, channels, shows and timestamps are managed for thirteen million accounts on ScyllaDB. Compared to their old system, they now connect ScyllaDB directly to their REST API data services. This allows Comcast to simplify their infrastructure by getting rid of their cache and pre-cache servers, and improved performance by 10x.
GE Digital’s Venkatesh Sivasubramanian & Arvind Singh came to the stage later in the morning to talk about embedding ScyllaDB in their Predix platform, the world’s largest Industrial Internet-of-Things (IIoT) platform. From power to aviation to 3D printing industrial components, there are entirely different classes of data that GE Digital manages.
Glauber Costa, VP of Field Engineering at ScyllaDB also had a keynote discussing ScyllaDB’s new support of analytics and transaction processing in the same database. The challenge has always been that OLTP relies on a rapid stream of small transactions with a mix of reads and writes, and where latency is paramount, whereas OLAP is oriented towards broad data reads where throughput is paramount. Mixing those two types of loads in the past has traditionally caused one operation or the other to suffer. Thus, in the past, organizations have simply maintained two different clusters. One for transactions, and one for analytics. However, this is extremely inefficient and costly.
How can you engineer a database so that these different loads can work well together? On the same cluster? Avoiding doubling your servers and the necessity to keep two different clusters in synch? And make it work so well your database in fact becomes “boring?”
ScyllaDB’s new per-user SLA capability builds on the existing I/O scheduler along with a new CPU scheduler to adjust priority of low-level activities in each shard. Different tasks and users can then be granted, with precision, shares of system resources based on adjustable settings.
While you can still overload a system if you have insufficient overall resources, this new feature allows you to now mix traffic loads using a single, scalable cluster to handle all your data needs.
Breakout Sessions
Tuesday afternoon and Wednesday morning were jam-packed with session-after-session by both users presenting their use cases and war stories, as well as ScyllaDB’s own engineering staff taking deep dives into ScyllaDB’s latest features and capabilities.
Amongst the highest-rated sessions at the conference:
Again, there’s just too much to get into a deep dive of each of these sessions. I highly encourage you to look at the dozens of presentations now up on SlideShare.
The Big Finish
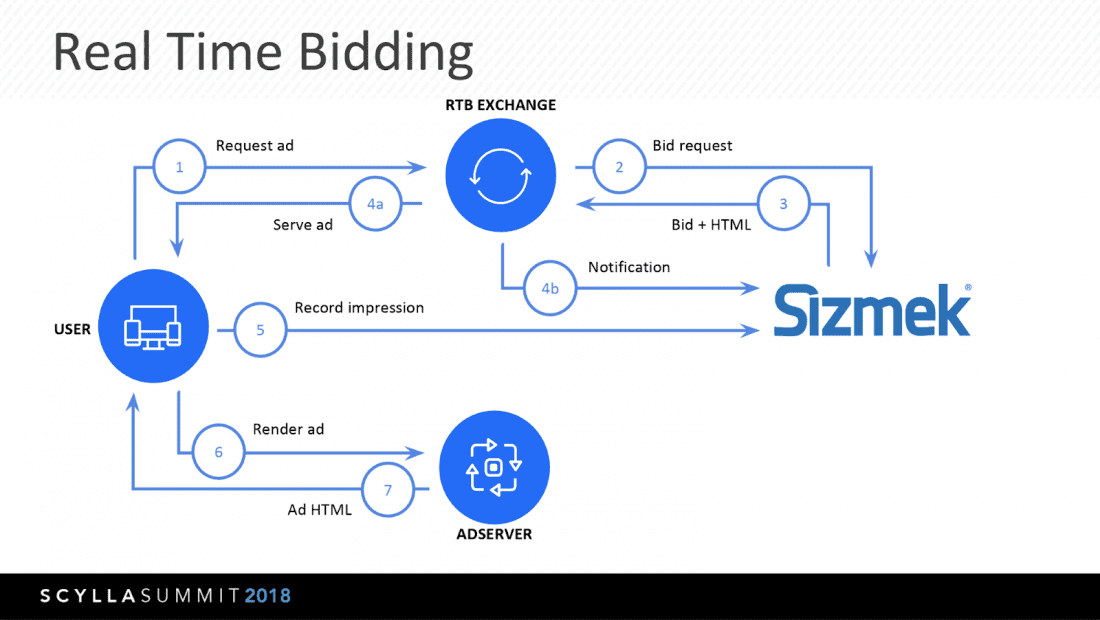
Wednesday afternoon brought everyone back together for the closing general sessions, which were kicked off by Ľuboš Koščo & Michal Šenkýř of AdTech leader Sizmek. Their session on Adventures in AdTech: Processing 50 Billion User Profiles in Real Time with ScyllaDB was impressive in many ways. They are managing ScyllaDB across seven datacenters, serving up billions of ad bids per day in the blink of an eye in 70 countries around the world.
Sizmek were followed by ScyllaDB’s Piotr Sarna, who delivered an in-depth presentation on three weighty and interrelated topics: Materialized Views, Secondary Indexes, and Filtering. Yes indeed, they are finally here!
Well, in fact, Materialized Views were experimental in 2.0, and Secondary Indexes were experimental in 2.1. We learned a lot and evolved their implementation working with customers using these features. With ScyllaDB Open Source 3.0, they are both production-ready, along with the new Filtering feature.
There is a lot to digest in his talk, from handling reads-before-writes in automatic view updates for materialized views, and applying backpressure to prevent overloading clusters, to hinted handoffs for asynchronous consistency. Why we decided on global secondary indexes and how we implemented paging. Piotr also gave guidance on when to use a secondary index versus a materialized view. On top of all of that, how to apply filtering to narrow-down on the all the data you need and yet only get the data you want. When we publish it, this will definitely be one of those videos you want to digest in full.
Grab’s Aravind Srinivasan talked about Grab and ScyllaDB: Driving Southeast Asia Forward. Grab, beyond being the largest ride-sharing company in their geography, has expanded to provide a broader ecosystem for online shopping, payments, and delivery. Their fraud detection system is not just important to their business internally; it is vital for the trust of their community and the financial viability of their vendors.
Technologically, Grab’s use case highlighted how vital the combination of Apache Kafka and ScyllaDB was for his internal developers. Such a powerful tech combo was a common theme to many of the talks over the two days. Indeed, we were privileged to have Confluent’s own Hojjat Jafarpour speak about KSQL at the event.
We ended with an Ask Me Anything, featuring Dor, Avi and Glauber on stage. It was no surprise to us that many of the questions that peppered our team came from Kiwi’s Martin Strycek and Numberly’s Alexys Jacob! If there were any questions we didn’t get to answer for you, feel free to drop in on our Slack channel, mailing list, or Github and start a conversation.
We want to thank everyone who came to our Summit, from the open source community to the enterprise users, from the Bay Area to all parts from around the globe. We also have to give our special thanks to our many speakers who brought to us their incredible stories, remarkable achievements, and incredible solutions.