ScyllaDB Open Source 3.0 is a landmark release for ScyllaDB: Materialized Views and Secondary Indexes are production-ready, and ScyllaDB Open Source NoSQL database (v 3.0) can now read and write the Cassandra 3.x SSTable (“mc”) format. In addition, ScyllaDB Open Source 3.0 provides a variety of performance improvements to existing functionality.
In this article we will explore the nature of a pair of those performance improvements, and the scenarios in which ScyllaDB users can expect to see a significant performance gain.
Streaming
When one ScyllaDB node needs to transfer data to another, it undertakes a process called streaming. This happens when a new node joins the cluster, when a node leaves a cluster, when data needs to be repaired, and so on.
In releases up to ScyllaDB Open Source 2.3, streaming was built on top of ScyllaDB’s Remote Procedure Call (RPC) mechanism. The RPC server is already present for other functionality and building data streaming on top of that is easy enough to get started. However, the RPC paradigm introduces a fair amount of overhead since the data has to be split into smaller messages with request / response.
In ScyllaDB Open Source 3.0, a specialized interface was introduced that is transparent to the developer and user. A stream is now opened between the nodes that will exchange data. Data is then continuously sent without the RPC request/response overhead. To evaluate the effect of that we populated two nodes with 2.8TB of data and a replication factor of 2 (RF=2) in both ScyllaDB Open Source 2.3 and ScyllaDB Open Source 3.0 on the same hardware. The schema is a key-value pair with 4kB values.
Once the ingestion quiesces, we then added a third node and measured the time it takes for the node addition to complete (data rebalancing) while the cluster is otherwise idle. The new node is then decommissioned, so it transfers its ranges back to the original two nodes with the cluster still otherwise idle, and after that it is added again— this time with a constant mixed workload running in tandem.
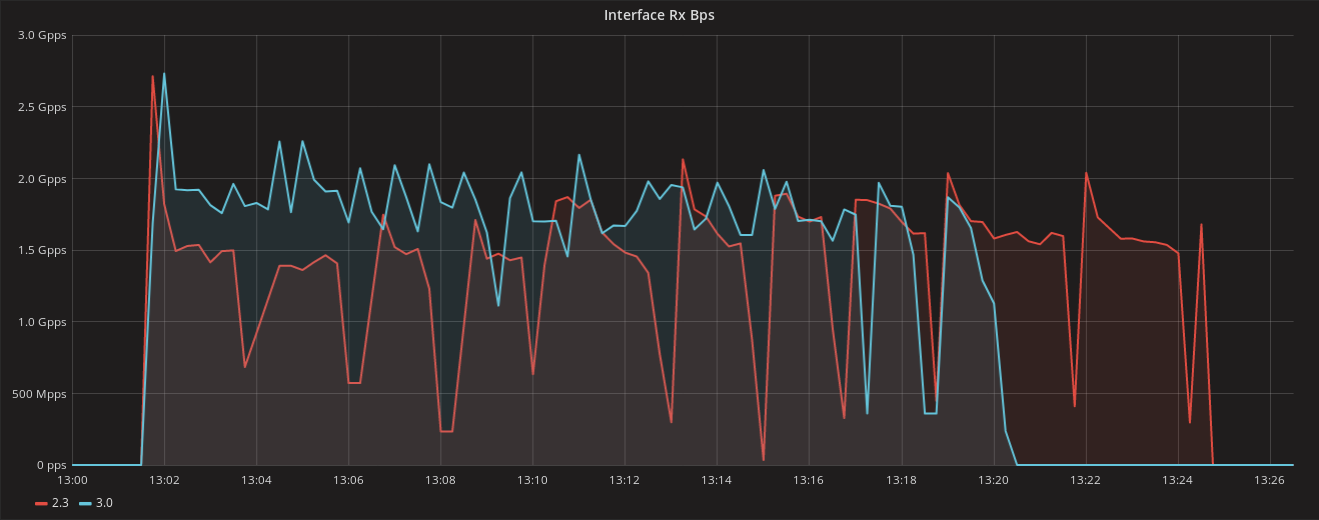
Figure 1: Network interface receive bandwidth in the node being added. ScyllaDB 3.0 (in blue) achieves faster network throughput in this operation and is therefore faster.
Results
| ScyllaDB Open Source 2.3 | ScyllaDB Open Source 3.0 | Difference | |
| Time to decommission a node, cluster idle | 895 s | 695 s | 22% |
| Time to add a node, cluster idle | 1472 s | 1236 s | 16% |
| Time to add a node, during load | 1834 s | 1592 s | 13% |
Table 1: Result of streaming operations in ScyllaDB Open Source 2.3 and ScyllaDB Open Source 3.0 (in seconds): ScyllaDB Open source 3.0 is faster than ScyllaDB Open Source 2.3 when streaming a total of 2.8TB of data, as a result of a new, specialized RPC interface.
Hinted Handoff
Hinted Handoff is not a performance feature per se, but it can have impact on performance, aside from its general utility. When a write is deemed successful but one or more nodes did not acknowledge the write, ScyllaDB will write a hint that will be replayed back to those nodes when they are back online.
This feature is useful for reducing the difference between data in the nodes when nodes are down — whether due to scheduled upgrades, or for all-too-common intermittent network issues. The biggest impact of this feature is reducing— not eliminating the amount of data transferred during repair. However, when requests are read from the database with QUORUM consistency level, the database, upon finding differences, will have to reconcile the differences on the spot.
Therefore, by having less differences between nodes, some performance improvement is also expected even on standard foreground workloads, outside of repair.
To analyze the impact of Hinted Handoff on performance, we inserted 120,000,000 keys into a 3-node cluster and ran a script in one of them that uses the iptables Linux utility to simulate intermittent network failures. The script can be found in the appendix at the end of this article.
After the insertion phase ends, we then issue a fixed-throughput QUORUM consistency read-only workload, reading at 50,000 ops. Because those are QUORUM reads, if ScyllaDB finds a discrepancy between the two nodes being queried it has to fix it right away. This will slow down some of the reads for which a difference is found.
This behavior can be clearly seen in Figure 2. While ScyllaDB Open Source 3.0 (in yellow) shows no reconciliations, meaning that the data can be served right away. ScyllaDB 2.3, in the absence of Hinted Handoff, will detect differences for the rows that failed to propagate during the time where the node was down. Note that as time passes these differences get lower as another background process, probabilistic read repair, manages to fix some of them.
The results are summarized in Table 2 below: the tail latencies get up to 60% better as the extra work of repairing the difference is avoided.
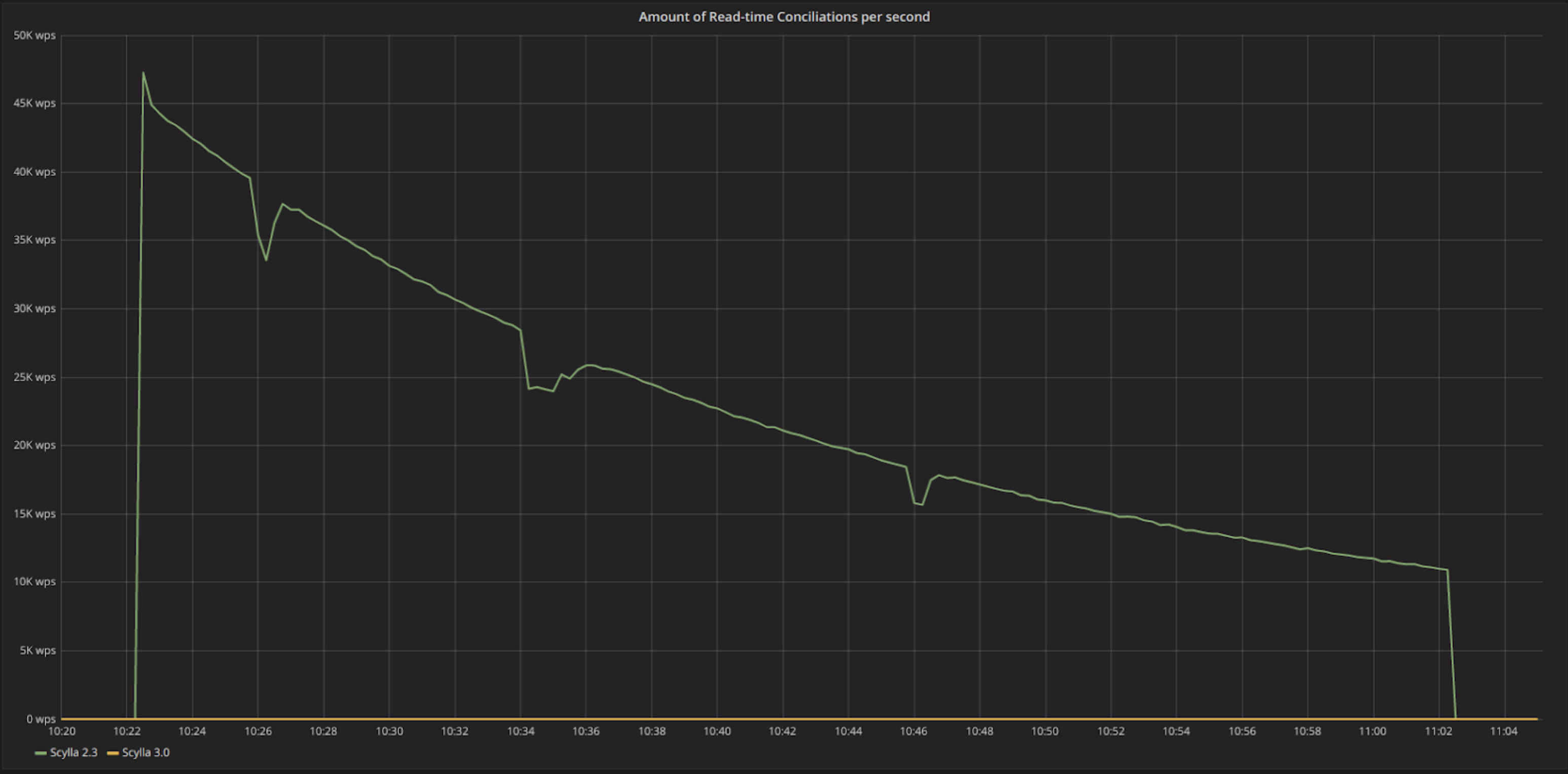
Figure 2: The rate in requests/s in which we see conciliation (read repair) operations during a read-only QUORUM consistency workload. ScyllaDB 2.3, in green, finds differences in the data during a QUORUM read workload, and the process of conciliating slow down the reads. In ScyllaDB 3.0, due to Hinted Handoff, there are no differences in the data.
Results
| ScyllaDB Open Source 2.3 | ScyllaDB Open Source 3.0 | Improvement | |
| 95th percentile | 5 ms | 2 ms | 60% |
| 99th percentile | 12 ms | 4.5 ms | 62% |
| 99.9th percentile | 38 ms | 34 ms | 10% |
Table 2: Improvements in tail latencies for a read-only QUORUM consistency workload in ScyllaDB Open Source 3.0 over ScyllaDB Open Source 2.3. ScyllaDB Open Source 3.0 ships with Hinted Handoff enabled, that among other benefits, reduces the need for reconciliation in QUORUM queries.
Conclusion
ScyllaDB Open Source 3.0 introduces many new features and improved core functionality such as Allow Filtering, SSTable 3.0 format support, and range (multipartition) scan improvements. It also promotes other features from experimental status to production-ready, such as Materialized Views, Secondary Indices, and Hinted Handoffs. Collectively these improvements unlock new types of data modeling and result in better workloads.
In this article, we have discussed two of those improvements that improve the performance of in the face of intermittent or permanent failures. Look forward to more upcoming blogs featuring the improvements found in ScyllaDB Open Source 3.0 in the coming days.
Appendix
Streaming
1. Populating Nodes
We used 4 nodes to populate data into the cluster. We splitted work equally between them by writing 175M keys each, within different sequences, adding up to 700M keys. The populating phase used the following logic to split data:
2. Load Simulation
We used read and write operations, running simultaneously. Each limited to 50k requests per second, adding up to 100k requests per second on the server. This procedure got us to 50% cpu usage.
Hinted Handoff
1. Populating nodes
2. Simulating network intermittent failures for Hinted Handoff
3. Hinted Handoff, reading from the nodes