December 28, 2017 How to Ruin Your Performance by Choosing the Wrong Compaction Strategy Featured, Tutorials, Performance, ScyllaDB Open Source
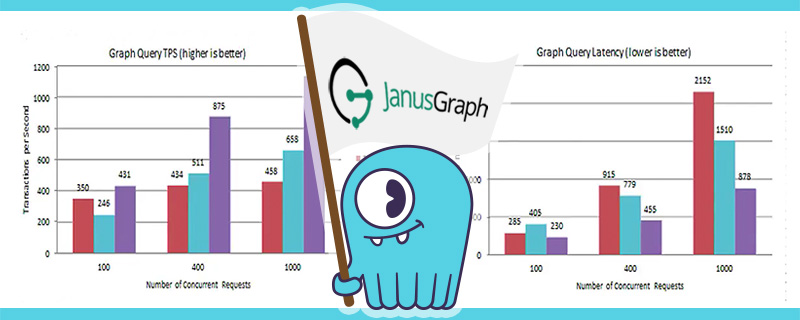
December 21, 2017 Performance Evaluation: ScyllaDB as a Database Backend for JanusGraph Tutorials, Featured, Performance, Integrations, ScyllaDB Open Source
November 29, 2017 Zenly: The Journey for a Database Replacement Featured, User Stories, ScyllaDB Open Source
August 31, 2017 mParticle shares their Journey from Apache Cassandra to ScyllaDB at DB Month Meetup Events, User Stories, ScyllaDB Open Source