April 12, 2018 Voice of Experience: IBM Cloud’s Compose for JanusGraph Uncovers Advantages of ScyllaDB Tutorials
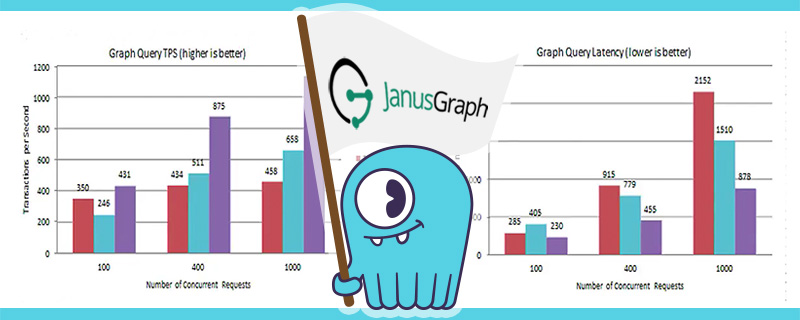
December 21, 2017 Performance Evaluation: ScyllaDB as a Database Backend for JanusGraph Featured, Tutorials, Performance, Integrations, ScyllaDB Open Source