August 2, 2023 What is an ML Feature Store and How Can ScyllaDB Help You Build One? Ecosystem, How To
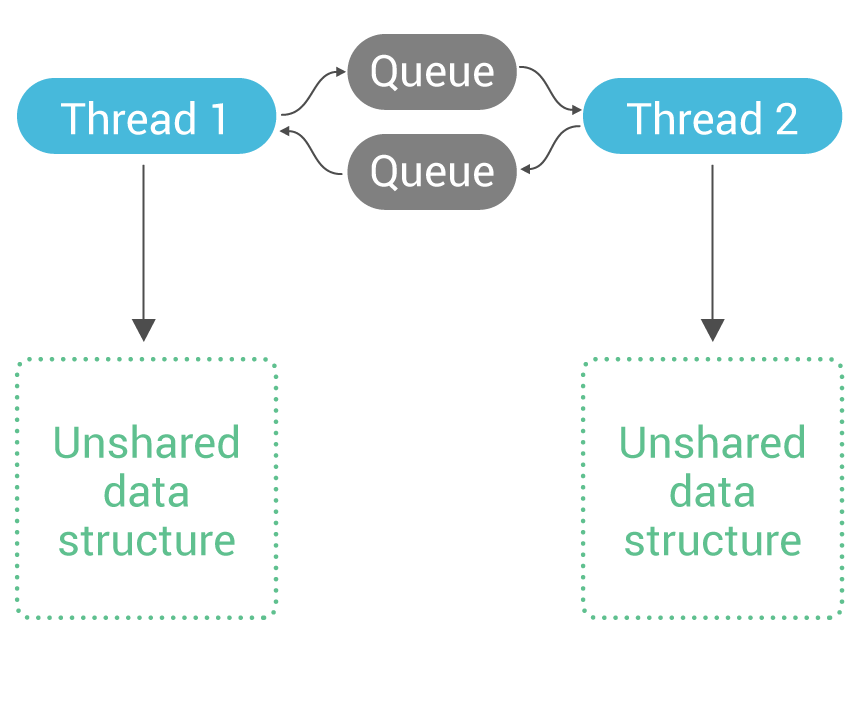
February 15, 2018 Adventures with Memory Barriers and Seastar on Linux Featured, Engineering, ScyllaDB Open Source, Seastar, Tutorials
January 18, 2018 Mutant Monitoring System (MMS) Day 2 – Building the Tracking System Tutorials, Featured
December 13, 2017 Stop Wasting ScyllaDB’s CPU Time by Not Being Prepared ScyllaDB Open Source, Tutorials, Featured