




Introduction
Seastar provides a programming environment that abstracts away most of the problems of multi-threaded programming using a thread-per-core model. Locks, atomic variables, memory barriers, lock-free programming, and all of the scaling and complexity that come from them are gone. In their place, Seastar provides a single facility for inter-core communications. This is, of course, great for the developer, who can easily utilize many-core machines, but there is also another side: because Seastar takes care of all inter-core communications, it can apply advanced optimizations to these communications.
This article examines these optimizations and some of the complexity involved.
Seastar Inter-thread Communication Backgrounder
Most applications implement inter-thread communications by using locks. One thread takes a lock on a shared data structure, and this communicates to other threads that they may not access it. It then performs its accesses, and eventually releases the lock; this communicates to other threads that they are now free to access the data structure.
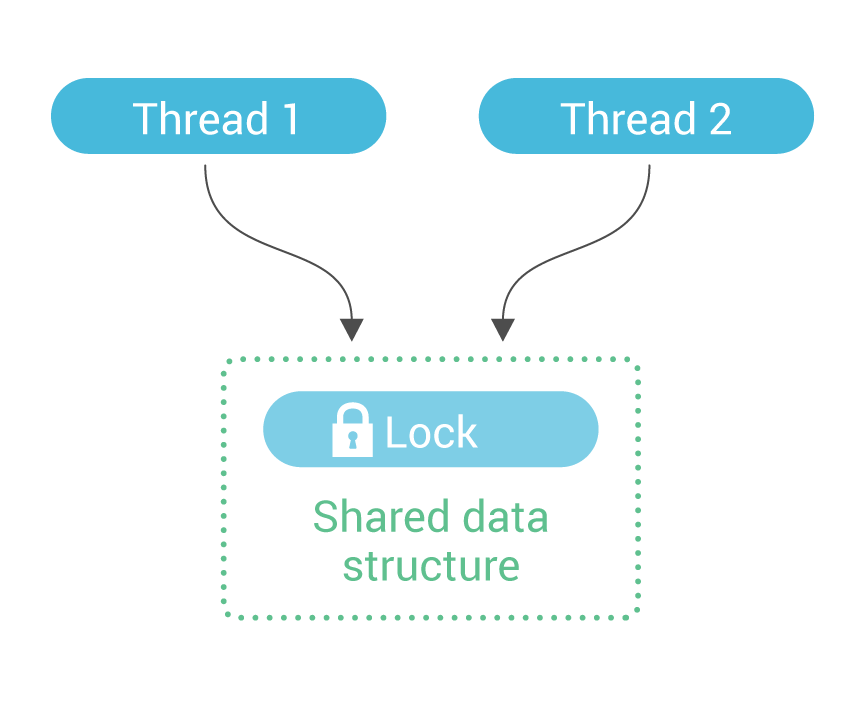
While this method works well for some applications, it suffers from scaling problems on data-intensive, many-core applications. The amount of effort needed to take and release locks grows as the server scales.
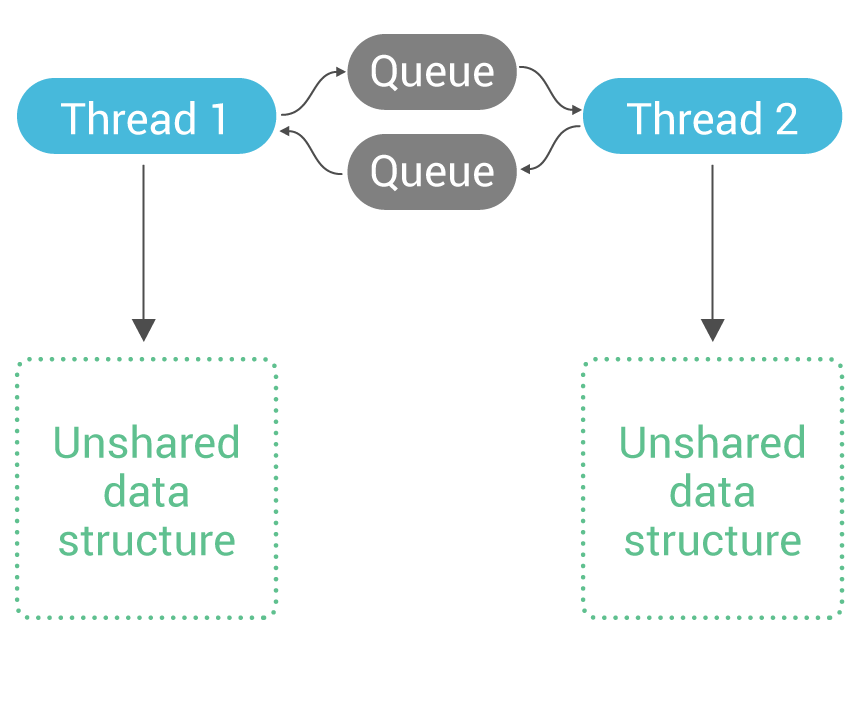
Because of Seastar’s focus on shared-nothing and asynchronous programming, it takes a different approach: a data structure is owned on a particular core (shard), and if a thread running on a different core wishes to access that data structure, it sends a message to the owner core with the details of the access. The access is now done by the owner core’s thread, and when it is complete, it posts the response as a message to the original requester.
Because only a single thread may directly access this unshared data structure, no locks are necessary to access it safely.
Basic Lock-free Single-producer/Single-consumer Queues
Single-producer/single-consumer queues were invented during the middle ages, so if you’re familiar with them you can skip this section. We use an array of messages, organized as a ring buffer, and two indexes into the ring: a head and a tail. The producer writes a few messages after the current tail, and then adjusts the tail to include the newly-written messages. The consumer looks at the difference between the tail and head to compute how many messages are available. It can then read some or all of these messages from the ring and adjust the head index to indicate where to start reading from next time.
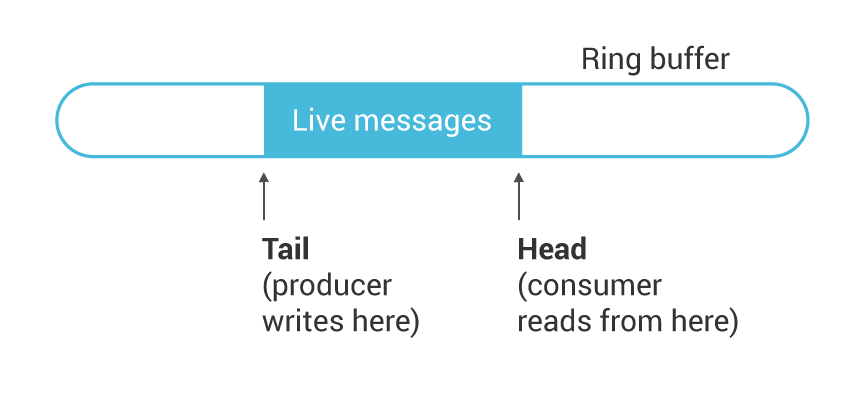
Notice that since the head and tail indexes are written by different threads, a message can be in the process of being written, waiting, or in the process of being read, but never read and written simultaneously. These preconditions allow us to implement the queue in a lock-free manner: there is no need to take some lock to arbitrate access among different threads.
There is, however, a great need to take care about memory ordering. Let’s look at the producer and consumer in pseudocode:
send_messages: write messages into the ring increase tail index by number of messages written receive_messages: read head and tail indexes available = tail - head if (available) read messages update head index
The problem here is that both the compiler and, more ominously, the processor, are allowed to reorder reads and writes to tail and head. If that happens, then the producer can indicate to the consumer that messages are ready even before they are not completely written, and the consumer may start reading messages before the producer indicated they are written.
The way to fix this problem is by introducing memory barriers. A release barrier tells the compiler and the processor to make sure any previous reads or writes are complete before the next write executes, and a consume barrier tells the compiler and processor that following reads depend on the value of a variable and should not be speculated.
With the correct memory barriers, our pseudocode now reads:
send_messages: write messages into the ring release memory barrier increase tail index by number of messages written receive_messages: read head index read tail index (with consume memory barrier) available = tail - head if (available) read messages update head index
The Complications of Sleeping
The lock-free single producer/single consumer queue works well, but it assumes the consumer is reading the tail index frequently. What happens if the consumer is asleep (i.e. in an epoll_wait system call)? We will have to wake it up. We don’t want to wake it up unconditionally (system calls are expensive), so we will wake it up only if it is sleeping.
From the producer side, everything is simple:
send_messages:
push messages into the queue
full memory barrier
if (consumer_is_sleeping)
wake it up
The consumer side is only interesting when we try to put the current thread to sleep:
try_to_sleep:
consumer_is_sleeping = true
full memory barrier
if (there are messages in a queue)
// We raced with a producer, abort sleep
consumer_is_sleeping = false
return
sleep until woken up by some event
consumer_is_sleeping = false
So, the producer adds a conditional wake when it sends messages to a potentially sleeping consumer. The consumer, when it wants to go to sleep, has to first notify producers that it is asleep, then check the queue for any messages posted before producers noticed the notification, and finally sleep.
But notice the full memory barrier lines. What are they for? Recall that both the compiler and the processor may reorder memory access instructions. In the producer’s case, if the consumer_is_sleeping read is moved ahead of the queue write, then the producer may miss a consumer that has just gone to sleep. Similarly, if the consumer’s checking whether a queue is empty or not is moved ahead of the write to consumer_is_sleeping, then a producer may think the consumer is still active when in fact it has decided to go to sleep.
The full memory barriers (in C++ terms, sequential consistency memory ordering, std::memory_order_seq_cst) prevent this reordering. In both cases, they prevent a later read from being executed ahead of an earlier write. Since delaying writes is a powerful optimization from the processor’s point of view, the barrier that prevents it (the MFENCE instruction on x86) is expensive.
Moving Work to Idle Cores
We don’t really mind an expensive barrier operation when we go to sleep; after all, if we decided to do that, we don’t have anything better to do. On the other hand, on the producer’s side, issuing a full memory barrier every time we send a message is not something we like, especially as on a busy system the read will always return the same result – the consumer is not sleeping. We are paying a high price in the fast path just to see that nothing needs to be done.
Can this be improved? It can – if we can move the expensive bits from the producer, who is doing work, to the consumer, who is just preparing to go to sleep. In fact, we’re prepared to make the act of sleeping significantly more expensive, because it is rare1.
To tie the costs of sleeping to the act of going to sleep, we will make the core that is going to sleep inject a memory barrier on all other cores. This way, a heavily loaded system, which rarely goes to sleep, will not incur the costs of sleeping. A lightly loaded system will need to do more work, but since it is lightly loaded, we don’t care much.
There is no single machine instruction that will cause other cores to issue a barrier, but we can cause another thread to execute code of our choosing by sending it a signal. The producer/consumer pseudocode now looks like this:
Barrier-free producer:
send_messages: push messages into the queue compiler memory barrier // prevents compiler from reordering code if (consumer_is_sleeping) wake it up signal_handler: full memory barrier mark barrier as complete
The consumer is now responsible for both its own memory barriers and the producer-side memory barriers:
try_to_sleep:
consumer_is_sleeping = true
full memory barrier
send signals to producer threads
wait for barriers to be marked as complete
if (there are messages in a queue)
// We raced with a producer, abort sleep
consumer_is_sleeping = false
return
sleep until woken up by some event
consumer_is_sleeping = false
We don’t know at what point the signal handler will execute on the producer, but wherever it is, we are safe:
- If the signal was executed before the producer pushed any messages into the queue, then the producer will notice that the consumer is sleeping (or trying to sleep)
- If the signal was executed after the producer checked consumer_is_sleeping, then the consumer will notice that messages were pushed into the queue and avoid sleeping
- If the signal was executed after the producer pushed any messages into the queue, but before it checked consumer_is_sleeping, then both the producer and the consumer will notice the race (with one sending an unneeded wakeup, and the other avoiding sleep)
At the cost of significant complexity, we unburdened the producer from issuing an expensive full barrier every time, and instead made this a rare event, albeit with much higher cost.
Injecting Barriers with mprotect()
The previous section used signals to inject a full memory barrier on other cores. Signals, however, are notoriously slow as they involve stopping the running thread and making it run a signal handler. We, therefore, used a different trick for barrier injection:
inject_barrier_init: // executed once in the program’s lifetime buffer = mmap(one page) inject_barrier: // instead of sending signals and waiting mprotect(buffer, PAGE_SIZE, PROT_READ|PROT_WRITE) mprotect(buffer, PAGE_SIZE, PROT_READ)
But wait, what does mprotect() have to do with injecting memory barriers on other cores?
To understand that, recall that page protection information is stored in the page tables, and can also be cached in Translation Lookaside Buffers, or TLBs. TLBs are on-chip caches that store virtual address translation and protection information. What’s important to note about TLBs is that they are not coherent: a change to a page table will not invalidate or update a TLB that caches it.
As a result, the operating system has to invalidate those TLBs itself. And since each core has its private TLB, the operating system has to send a message to each core to invalidate the TLB, and wait for all cores to acknowledge, before returning from an mprotect() system call that is reducing permissions on a memory range. As a side effect of receiving this message, the operating system generates a full memory barrier.
Sounds familiar? That’s exactly what we did in userspace except that slow signals are avoided, and instead, we get optimized kernel code paths.
Not So Fast
While our inject_barrier mprotect() hack is very fast, we sometimes observed tremendous slowdowns on many-core machines with medium loads. Low loads were fine. High loads were better. Medium loads tanked.
The problem turned out to be a well-known lock in Linux, called mmap_sem. This is a read-write semaphore and mprotect() holds it for write access. At high loads, we don’t sleep, so it was not called. At low loads, we rarely wake, so contention was likewise rare. In the sweet spot in between, we take the lock often enough to cause contention. The machine then has one logical core that is running mprotect() and 63 other logical cores fighting for the right to be next in line. It was so slow that by the time they managed to sleep, they were late waking up for the next request.
The solution for that was to protect the mprotect() calls with a try-spinlock. If we manage to grab the lock, we’re assured that there will be no contention on the kernel lock. If we don’t manage to grab the lock, we don’t attempt to sleep; we assume a message may have been sent to us, look for it, and attempt to try to sleep later. In pseudocode:
try_inject_barrier:
if try_spin_lock(mprotect_helper_lock):
mprotect(buffer, PAGE_SIZE, PROT_READ|PROT_WRITE)
mprotect(buffer, PAGE_SIZE, PROT_READ)
spin_unlock(mprotect_helper_lock)
return 1
else:
return 0
membarrier() to the Rescue
Does the above look like a hack piled on hack? Why yes, it does. In addition, it doesn’t work on ARM, which has hardware support for invalidating TLBs on other cores.
Fortunately, a relatively new Linux system call membarrier(), recently gained an even newer option called MEMBARRIER_CMD_PRIVATE_EXPEDITED. The system call does exactly what you would guess (and if you didn’t, have a look here): it causes a memory barrier to be issued on all cores that are running threads that belong to this process. Exactly what we need! It’s faster than mprotect() and works on ARM.
Our barrier pseudocode now looks like:
try_inject_barrier: if (MEMBARRIER_CMD_PRIVATE_EXPEDITED is supported): membarrier(MEMBARRIER_CMD_PRIVATE_EXPEDITED) return 1 else: fallback path with mprotect
The code is now faster, simpler, and more robust (well, except for the fallback paths).
Performance Evaluation
Unfortunately, most of the work detailed in this article was performed before blogs were invented, so we did not save measurements for posterity. However, under high messaging loads, the single instruction occupying the top of the profile was the MFENCE instruction in the producer fast path, which was eliminated as a result of this work.
Conclusion
This article shows that by directing all inter-core communications into a single path, that path can undergo extreme optimization. Operating system support for the optimization was lacking, but we hacked our way around it, and when the proper support arrived, Seastar was in a great position to take advantage.
1: Seastar ensures that sleeping is rare by polling for work for a short while before sleeping. This prevents moderate loads from entering the kernel to sleep, which is an expensive operation even without the tricks described in this article.
