





A couple of years ago, we published the first version of CarePet, an example IoT project designed to help you get started with ScyllaDB. Recently, we’ve expanded the project to make it useful for a larger group of developers by including new examples in Rust, Python, and PHP. Additionally, we also implemented a Terraform example that allows you to spin up a ScyllaDB Cloud cluster with the initial CarePet schema.
This blog post goes over the components of the project and shows you how to get started. In the GitHub repository, you can find examples in multiple languages:
The CarePet app allows tracking of pets’ health indicators. Each tutorial builds the same app with these three components:
- A virtual collar that reads and pushes sensor data
- A web app for reading and analyzing the pets’ data
- A database migration tool
The tutorials and other supporting material are in our documentation as well as GitHub
Keep in mind that this example is meant to be one of your first steps at trying ScyllaDB. It is not production ready and should be used for reference purposes only.
TL;DR High-Level Overview + Deploying to ScyllaDB Cloud with Terraform
To get your hands dirty and start building right away:
- Go to iot.scylladb.com
- Select your favorite programming language
- Follow the instructions in the documentation
If you have problems or questions while working on the app, feel free to post a message in our community forum and we’ll be happy to solve your problem or answer your questions.
Using the ScyllaDB Cloud Terraform provider you can interact with ScyllaDB Cloud – create, edit, or delete your instances – using Terraform. In the CarePet repository, you can find a starter Terraform configuration that sets up a new ScyllaDB Cloud cluster and creates the initial schema in the new database. If you want to complete the tutorial using ScyllaDB Cloud and Terraform, go to this documentation page and get started!
About This Tutorial
Now, a little more detail…
In this sample app tutorial, you’ll create a simple IoT application from scratch that uses ScyllaDB as the database. The application is called “Care Pet”; it collects and analyzes data from sensors attached to virtual pet collars. This data can be used to monitor a pet’s health and activity.
The tutorial walks you through a specific instance of the steps to create a typical IoT application from scratch. This includes gathering requirements, creating the data model, cluster sizing and hardware needed to match the requirements, and (finally) building and running the application.
Use Case Requirements
Each pet collar includes sensors that report four different measurements: Temperature, Pulse, Location, and Respiration. The collar reads the sensor’s data once a minute, aggregates it in a buffer, and sends measurements directly to the app once an hour. The application should scale to 10 million pets. It keeps each pet’s data history for a month. Thus, the database will need to scale to contain 43 billion data points in a month (60 × 24 × 30 × 10,000,000 = 43,200,000,000); 43,200 data samples per pet. If the data variance is low, it will be possible to further compact the data and reduce the number of data points.
Note that in a real world design you’d have a fan-out architecture. The end-node IoT devices (the collars) would communicate wirelessly to an MQTT gateway or equivalent, which would, in turn, send updates to the application via, say, Apache Kafka. We’ll leave out those extra layers of complexity for now, but if you are interested, check out our post on ScyllaDB and Confluent Integration for IoT Deployments.
Performance Requirements
The application has two parts:
- Sensors: Writes to the database, throughput sensitive
- Backend dashboard: Reads from the database, latency-sensitive
For this example, we assume 99% writes (sensors) and 1% reads (backend dashboard)
The desired Service Level Objectives (SLOs) are:
- Writes: Throughput of 670K operations per second
- Reads: Latency of up to 10 milliseconds per key for the 99th percentile
The application requires high availability and fault tolerance. Even if a ScyllaDB node goes down or becomes unavailable, the cluster is expected to remain available and continue to provide service. You can learn more about ScyllaDB’s high availability in this lesson.
You can also calculate what these requirements would cost using ScyllaDB Cloud vs. other providers using our pricing calculator.
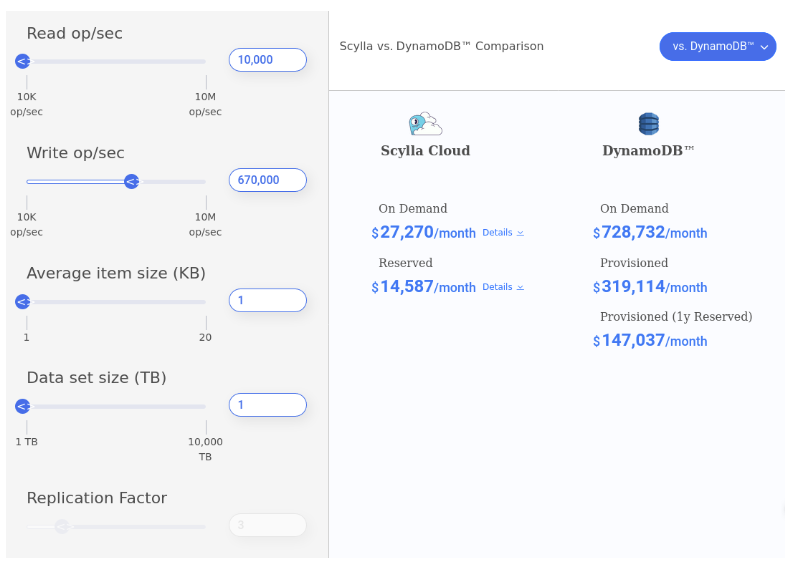
To satisfy the requirements of the example, ScyllaDB needs to be able to do 670K write operations per second and 10K read operations per second with 10ms P99 latency where the average item size is 1KB and the full data set is 1 TB. As you can see, ScyllaDB can provide not just great performance benefits but also huge cost savings in cases like this if you migrate from a different database like DynamoDB.
Design and Data Model
Now, let’s think about our queries, make the primary key and clustering key selection, and create the database schema. See more in the data model design document.
Here’s how we will create our data using CQL:
We hope you find the project useful to learn more about ScyllaDB. If you have questions or issues that are specific to this sample application, feel free to open an issue in the project’s GitHub repository.
Resources
Here’s what you need to get started with ScyllaDB:
- Install ScyllaDB (self-hosted)
- Install ScyllaDB (in cloud)
- Getting started with ScyllaDB
- Community forum
- CarePet documentation site
For a deeper understanding of ScyllaDB and to get answers to your questions, go to:
- ScyllaDB Essentials course on ScyllaDB University.
- Data Modeling and Application Development course on ScyllaDB University.
- Join the ScyllaDB Users Slack channel



