




Delve into the fundamentals of ML feature stores and explore why and how ScyllaDB can be a critical part of your feature store architecture.
Machine learning (ML) feature stores have been attracting attention and usage for business-critical applications ever since Uber introduced the concept with Michelangelo in 2017. In this blog post, we will delve into the fundamentals of ML feature stores and explore why and how ScyllaDB can be a critical part of your feature store architecture.
In order to understand what feature stores are, it’s important to first understand what features are.
What is a feature?
In Machine Learning, a feature is a set of data points that can be used to teach a model and make predictions about the future based on historical data. For example, our feature store sample application lets you make predictions regarding flight delays based on historical flight records.
Features are the result of complex data processing and transformation pipelines. Massive amounts of feature data enables accurate predictions and successful machine-learning projects.
What is a feature store?
A feature store is a central database in your machine learning architecture that contains your real-time and historical features. Feature stores allow your data engineers and data scientists to use the same central repository to discover, monitor, and analyze features.
What does a feature store architecture look like?
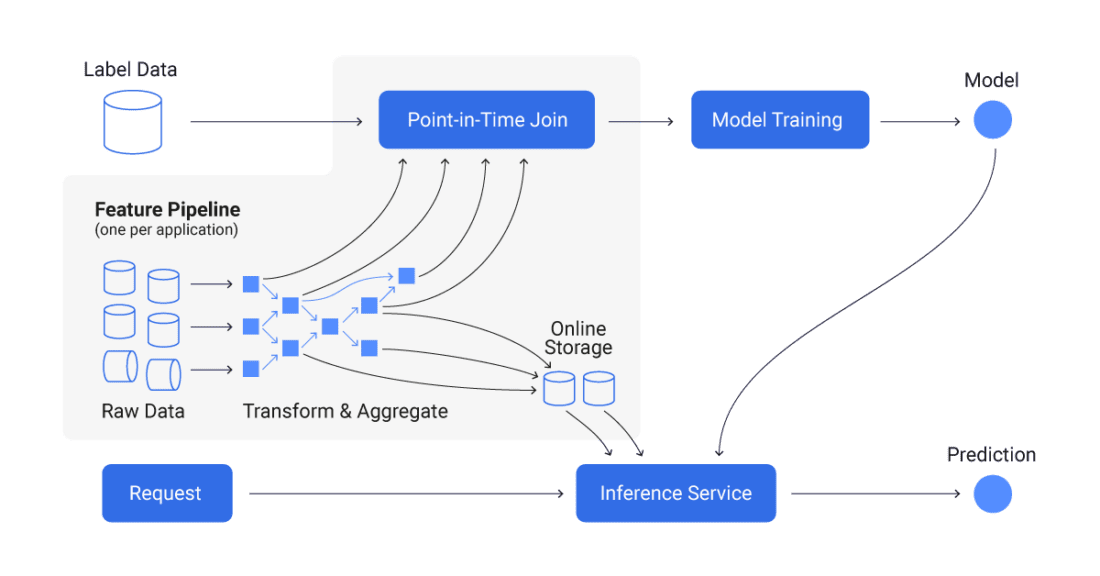
Online and offline databases in the feature store
When we talk about feature stores, users usually differentiate between two kinds of databases in their architecture. On one side, they use an online database and on the other, they might also have an offline database. These databases serve different purposes.
Offline database: This kind of database stores historical processed features, usually ingested in batches. Offline databases have feature data covering a large time frame from history hence they are useful for working with a set of features in a specific period in history.
Online database: This database might contain data from real-time data streams anmad the offline database as well. Online storage is used to serve the production model and other real-time applications with the most up-to-date feature data. Performance and low latency really matter here. If your database is not capable of delivering real-time features fast enough, then your model might use outdated or inaccurate data to make predictions.
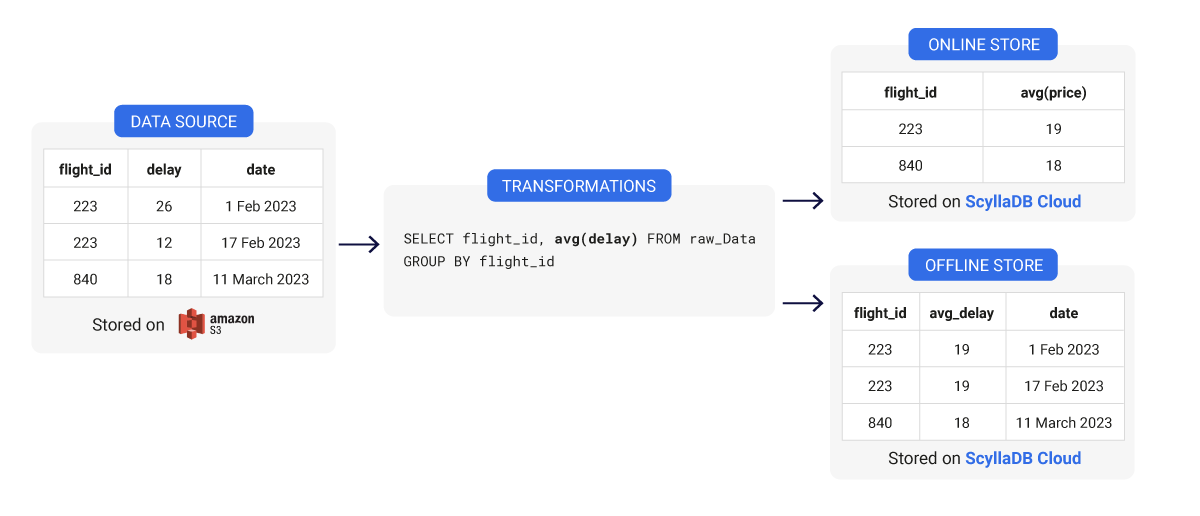
Feature store data modeling: wide vs narrow table design
When you are designing the data model within your feature store, be it an offline or online store, you can decide between two types of table designs: wide and narrow. Each has its own benefits and drawbacks. Let’s see actual examples for both and why they might or might not be the best for your use case:
Wide table design
The wide table design includes separate columns for each feature. The more types of features you want to store in the table the more columns you have to create.
Wide table layout example:
This kind of layout can be easy to get started with but it also becomes more complicated to maintain over time and hard to make changes to. Whenever you want to introduce a new feature (or drop an existing one) you need to modify the schema which can be complicated.
Narrow table design
Narrow table designs are simple and easier to maintain. This is because the number of columns are not meant to increase or decrease in the future even if you add or remove features.
Narrow table layout example:
Using this layout, you can get away with using only two fix columns long term to store features. One for the name of the feature (e.g.LATE_AIRCRAFT_DELAY) and one for the value of that feature.
In general, narrow tables might require casting the data types when retrieving data because it’s not in the correct form (e.g. the column type is FLOAT but in reality, the data value is an INTEGER. Fortunately, when we talk about feature stores, online and offline stores already have the data in proper clean number (FLOAT) format and all values have the same data type which means this is not a drawback in the case of feature stores.
What is ScyllaDB and how can it be used in your feature store architecture?
In order for machine learning teams to build real-time inference applications, they need databases that can return features at scale with low latency. ScyllaDB is a high-performance low-latency NoSQL database that can handle high volumes of read and write operations. Furthermore, ScyllaDB is a trusted database for mission-critical feature store workloads at companies like GE Healthcare or ShareChat due to its high availability and fault tolerance, It can do the heavy lifting in your infrastructure where performance and reliability matter.
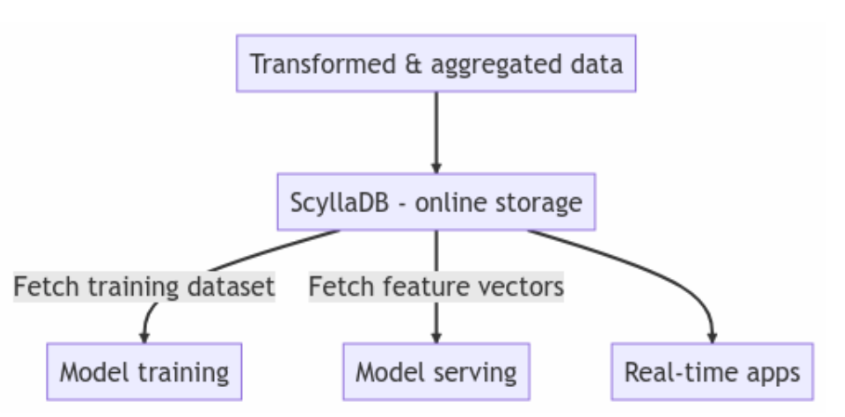
Aside from leveraging ScyllaDB as the online store in your feature store architecture, ScyllaDB is also used as an online/offline hybrid storage solution (see how Instacart implemented ScyllaDB as their hybrid feature store database). With this approach, you can lessen the maintenance burden on your team by having a single database to serve all your feature store workloads.
Users often place ScyllaDB in the center of their architecture to persist and retrieve features and feature store metadata. In this case, ScyllaDB acts as an online store. Other users also use ScyllaDB as their online/offline hybrid storage. Performance is a key requirement in order to speed up model development, and ScyllaDB’s read and write performance consistently meets or exceeds user expectations.
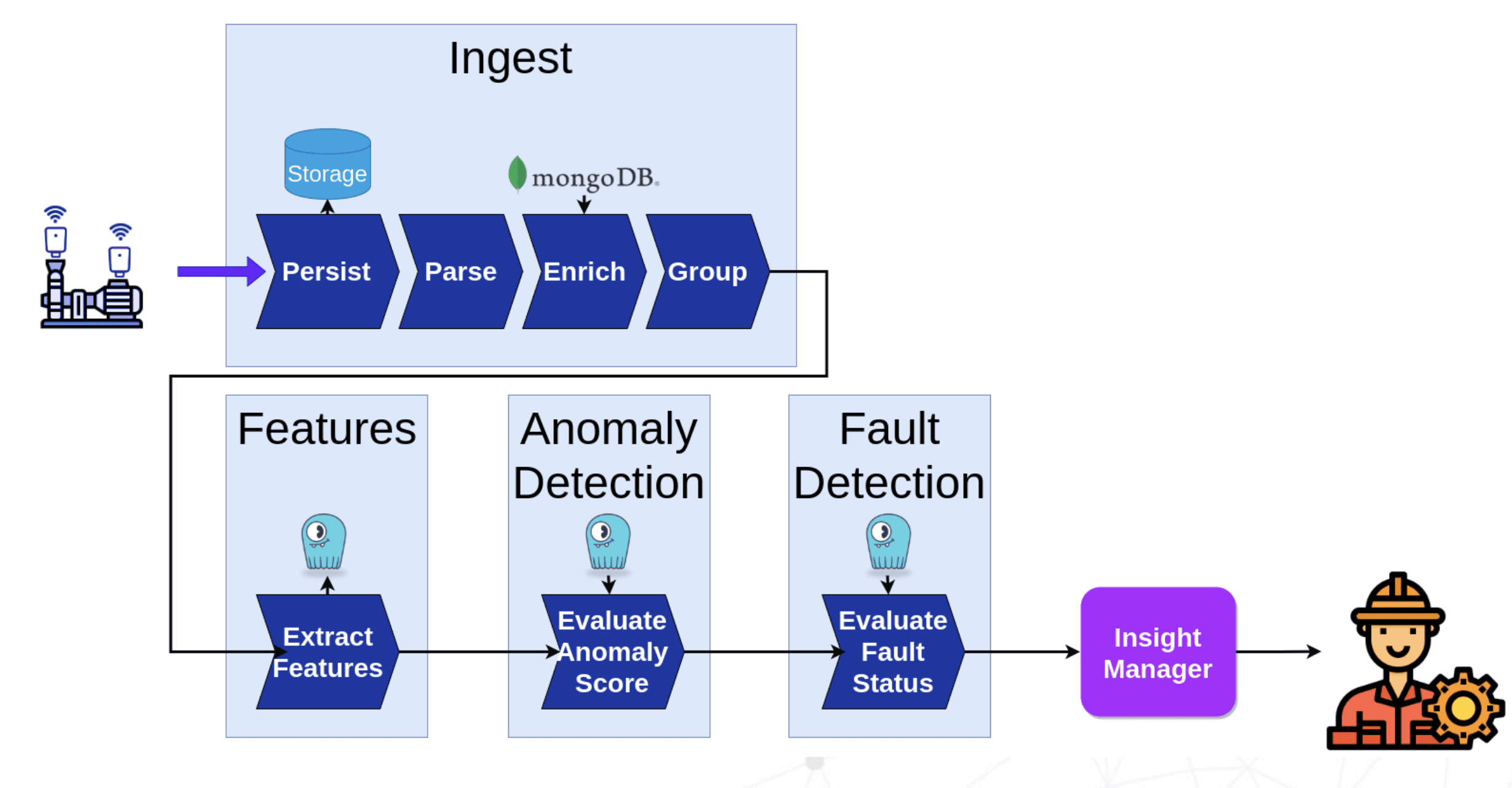
Image from: https://www.scylladb.com/2020/03/12/augury-insights-into-industrial-iot-time-series-data/
In fact, some users found that ScyllaDB could replace multiple databases and serve as a single central store for all their machine learning data needs. For example, ScyllaDB can replace Redis (online store) and PostgreSQL (offline store) – making infrastructure maintenance less expensive and simpler.
ScyllaDB shines in use cases where you require low latency and high performance. Furthermore, ScyllaDB is compatible with Cassandra and DynamoDB which means if you already use one of these databases, you can seamlessly migrate without having to change your queries.
Tutorial: ScyllaDB online store
To help you get started with ScyllaDB as your online store, we’ve created a sample application (also available on GitHub).
- Clone the repository: `git clone https://github.com/scylladb/scylladb-feature-store.git`
- Sign up for ScyllaDB Cloud or install ScyllaDB locally
- Create the schema:
cqlsh “node-0.aws_us_east_1.xxxxxxxxx.clusters.scylla.cloud” 9042 -u scylla -p “password” -f schema.cql - Connect to the instance with cqlsh and import a sample dataset
cqlsh “node-0.aws_us_east_1.xxxxxxxxx.clusters.scylla.cloud” 9042 -u scylla -p “password”
scylla@cqlsh> COPY feature_store.flight_features FROM ‘flight_features.csv’;
This command ingests a sample flight dataset:
Visit the documentation to continue the tutorial.
ScyllaDB + Feast
ScyllaDB, the fastest distributed database, also integrates with feature store tools like Feast. Feast is a popular open-source feature store for production ML. You can use several databases as your online feature store when using Feast, including ScyllaDB.
To set up ScyllaDB as a Feast online store, you need to edit the configuration file of Feast and add your ScyllaDB credentials. ScyllaDB is Cassandra-compatible so you can use Feast’s built-in Cassandra connector.
You can try ScyllaDB and Feast in action using our tutorial.
Wrapping up
Feature stores are necessary to feature engineering and building machine learning models. If you’re building a real-time feature store infrastructure, you need to consider performance carefully. Low-latency, high-performance, and high-throughput requirements make NoSQL databases a perfect candidate as an online storage solution in your feature store.
Here’s a look at how some teams use ScyllaDB as part of their feature store architecture:
- GE Healthcare on Enabling Precision Health with the Edison AI Platform
- ShareChat’s Path to High-Performance NoSQL with ScyllaDB
- Insights into Industrial IoT Time-Series Data
Learn more about ScyllaDB:



