




Editor’s note: This tutorial was developed and published independently by Javier Ramos (see the original on his blog). ScyllaDB is republishing it here with Javier’s permission.
This article is the first part of a series (see part 2 & part 3) of articles where I will show real-world use cases implemented using Rust alongside some other key technologies. The goal is to prove that Rust can be used safely for production workloads and that doing so is relatively simple. I hope that at the end of the series, you will be comfortable using Rust alongside other technologies such as ElasticSearch, Kafka, Pulsar, S3 and many more, so you can introduce Rust in your current company. Just by doing so, you can gain 3–5x performance boost and reduce the number of bugs while keeping costs at a minimum!
In this article I will walk you through a real-world example of a full-blown application (microservice) that showcases the following capabilities:
- Creating ultra-fast REST APIs using the Actix Web Framework in Rust.
- Reading and parsing big data files from AWS S3.
- Fast data ingestion from S3 into ScyllaDB (a Cassandra-compatible super fast NoSQL database).
- Graph data modeling in a NoSQL database.
- Writing highly asynchronous concurrent applications using Tokio.
- Best cloud native practices: multi-stage docker build, Kubernetes, microservices, etc.
The source code for this article is located here. I recommend that you check out the project to properly follow along with the article.
NOTE: This is not a Rust tutorial. It will be too tedious to explain every detail, line by line, and it will be too boring. That is why I recommend that you check out the code and follow along. I will try to explain how the code works at the general level and provide links to the libraries used. But, if you are new to Rust, you may find some concepts difficult. If that’s the case, check out the Rust resources links at the end of the article. Finally, this is a production-grade application but not a production-ready one; error handling and other areas need to be improved.
What are we building?
To test the power of Rust, we are going to build a fast data ingestion API which reads data from a data lake in S3 and stores it into a fast NoSQL database, in our case ScyllaDB. We will use the Rust Tokio library to allow asynchronous computing using many threads to speed up the ingestion process.
To complicate a bit the use case and make it more realistic, we will use hierarchical data. We will model graph data using NoSQL so we can run very fast traversals using many threads taking advantage of the power of Rust. In particular, we will see how we can run recursive code using multiple threads. This is very dangerous in other languages, but Rust makes it very safe.
Finally, we will use the fast Actix Web Framework to create an API to trigger ingestion jobs and also query the data.
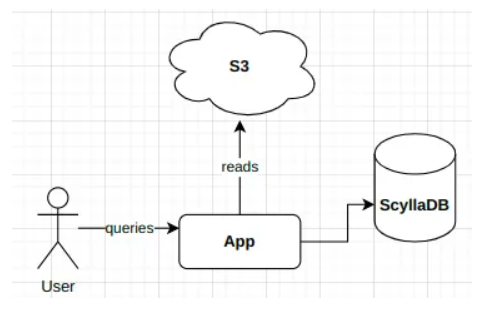
This is a very common use case:
- Data will land in your data lake from various sources such as Kafka.
- Data will be processed and move to a massive scale database where it can be queried much more efficiently than the data lake.
We will use cloud native best practices to make it compatible with orchestration tools such as Kubernetes by using environment variables for configuration. Kubernetes manifest files are included in the repo.
ScyllaDB
ScyllaDB is a Cassandra-compatible database written in C++ which provides better performance and ultra-low latency. It is probably the fastest database on the market. It is open source but some of the features require the enterprise edition. It can run on-prem or in the cloud. The dynamic scheduler provides optimizations for both OLAP and OLTP queries in the same cluster, making it a great database for all types of queries and tasks.
We chose ScyllaDB because it has an amazing and surprisingly fast Rust driver.
Watch ScyllaDB’s Rust workshop
Why are we building this?
The internet is flooded with TODO list examples of Rust but no real-world applications that use other technology. Recently, I became very interested in ScyllaDB and its amazing performance. When I heard they have a very fast Rust driver, I decided to test it and I was really impressed.
My hope with this article is to show you how to build a production-grade application using several frameworks and do it in a way that is highly performant, taking full advantage of the Rust safety features to build a highly concurrent application that will outperform any other language.
Data Model
We are going to model hierarchical data in order to showcase Rust and ScyllaDB capabilities when dealing with this type of data. As you know, hierarchical data is complex and traditional SQL databases or other databases such as ElasticSearch do not handle it easily and the performance is not great. The main reason is that it is hard to write concurrent code when you have a graph because you need to do recursion which does not play nicely with multi-threading. We will show how to solve this with Rust.
Compared with SQL databases, ScyllaDB can run millions of queries in parallel across many CPUs parallelizing the workload; this plays nicely with Rust’s massive parallelization features using Tokio. We will take advantage of this in our program to run the ingestion using thousands of threads working in parallel.
You need to think of ScyllaDB more like a storage engine than a full-blown database. ScyllaDB and other NoSQL databases do not provide many features such as joins, but they are extremely good at writing data very fast, which is our goal. In our application, we will just read and write data based on the partition key; that’s it. We just read individual keys and write to it. That’s why I say that is closer to S3 than to a SQL database.
In our demo application, we will have data nodes and relations. Each node will have some attributes such as name or type and also some tags which is a nested object. We also have relations between the objects.
Input Data
The data read from S3 will contain two types of data: nodes and relations. Nodes will have children and it is a highly nested structure; each file can have many nodes and each node many children. Then, we can define other relations between nodes besides the parent/child relation.
This is an input data example:
As you can see, we have a few nodes with children and also some relation between children. Relations have a specific type between the source and target.
ScyllaDB Model
We could write several articles about NoSQL data modeling and even more about graph data modeling, but this is not the purpose of this article. In NoSQL, you model the data around your queries. It is based on the use you are going to have for the data. The model proposed here may not suit your needs if you have different use cases.
In our case, we want to write data fast, so we do not want any read before writes and we want to read data in parallel. When we get a node, we also want to get the relations, but we want an option to just get the nodes.
To achieve this in an efficient way, we will use the node UUID (primary key) as the partition key and a few sorting keys in order to easily search relations. The idea is to store the node and its relations in the same table where the node will be the first row and the relations the adjacent rows using an adjacent list. This way the relations are co-located.
We are going to use a highly de-normalized model where relations will be duplicated, so parent nodes will have the children relations and the children also the parents, something similar to a doubly linked list. This uses more space but it will speed up the process. Remember that table scans are very inefficient in NoSQL; we want to always search by key. If we want to look for a node’s children, we cannot simply scan the whole table looking for nodes whose parent ID matches our query. The same applies to looking for children. So, we want to store both relations in a node: incoming relations into the node (from parent) and outgoing relations out of the node (to children).
To do this we will have a direction sorting key column that will tell us the direction of the relations. We will also have the relation type and finally the ID of the related node. So, the primary key will be:
PRIMARY KEY (id, direction, relation, relates_to)
The id is the partition key and the rest are the sorting keys. To store a node, we set the sorting keys to null, or in the case of ScyllaDB, just an empty string. This indicates that the row is a node. For relations, we add all the attributes to indicate the direction (inbound or outbound), the type and the id.
This is the DDL:
The ingestion_id is used to identify a single batch ingestion. The url field is auto generated during ingestion and it has the full node path of the hierarchy, from the parent to the node.
The tags are stored as a frozen list of tuples as a key/value pair.
During ingestion, we will store nodes and relations at the same time in parallel. Rows with the same node id will be co-located, which means that a node and its relations will be in the same shard. A node will have the sorting keys set to the empty string.
To get a node and its relations, we just need a super fast look up by ID
SELECT * FROM graph.nodes WHERE id = ?
The first row returned will have the node name, type and tags; the other rows will be the relations (in this case, the relation type and tags). We also de-normalize further and reuse the name column in relations to store the target node name; so the relates_to field has the ID and the name the target node name. This way we can display the data in a single lookup without doing extra queries to get the display name.
If we want to get just a node:
SELECT * FROM graph.nodes WHERE id = ? and direction = ''
If direction is empty it means it is the node.
To get the node and only one direction, such as the children we will use:
SELECT * FROM graph.nodes WHERE id = ? and direction in ('',?)
The first clause in the in will include the node row and the second one the passed relation type.
If you are coming from the relational world and find this confusing, I really recommend this video regarding NoSQL data modeling.
Implementation
In this section, we will review the repo and provide a general guide on how to build microservices in Rust. Again, the goal is not to explain line by line but instead give a general overview of the project.
Setup and Dependencies
First, you would need to install Rust and Cargo package manager.
curl https://sh.rustup.rs -sSf | sh
Then, create the project:T
cargo new rust-s3-scylladb
Now, open cargo.toml file and add the following dependencies:
Project Configuration, Error Handling and Environment Variables
In order to build cloud native applications, we should rely on environment variables to pass configurations such as S3 credentials. To do so, we use the config library to handle configuration.
To read environment variables, we use the dotenv package.
For error handling, we use the eyre library which makes error handling and error propagation much easier.
To make sure we follow the best cloud native practices, we use the tracing library for structured logging. This library can be also used for tracing.
Create a new config folder and add the mod.rs file:
The Config object contains our application configuration such host the desired port, the S3 region and the DB credentials.
The init_tracer method initializes the tracer that we use for logging. Note how we use the macro #[cfg(debug_assertions)] to detect if the build was done for production to use JSON structured logging or use regular logging in dev for easy debugging.
Reading Data from S3
We use the rust-s3 library to read data from S3 which is extremely easy. It also works for other cloud providers such as GCP.
Create an s3 folder with the mod.rs file and then a s3.rs file with the following contents:
In this file, we have a simple read_file method which reads a single file from S3. This will be used by the main program.
Using best practices, the credentials are read from env vars using the S3 lib built in method. Note how we use the ? operator to handle errors in a clean way returning a Result with the File object containing the nodes and relations.
We use serde_json to serialize the JSON data from S3 into our object.
We use structure logging throughout the project. To read from S3, we need to create a Bucket struct passing the bucket name, region and credentials. We use the URL library to get the name from the file URL.
The model is located in the data folder in the source_model.rs file:
ScyllaDB
We will create a new folder called db . In here, we will store the internal Database model and the ScyllaDB Service.
The model.rs file will look like:
DbNode is the internal representation of the node which, as we have seen, can be also a relation, so this model defers from the main model where we have separate objects for nodes and relations as we will see in the next section. We use the Option type for optional values. We use a vector to represent the tags; this will be mapped to the right structure by the ScyllaDB driver.
DbNodeSimple is just a simplified version of a node only (no relations) and no tags. Note: It is a better practice to use structural composition to not duplicate attributes of objects like I did here.
DbRelation represents relation rows and it is used for graph traversal to get the next set of children given a node.
DbNode can be a node or relation. We have helper methods to get a DbNode from relations or to create a new one from a relation.
The get_id_from_url method is used to generate always the same UUID for the given URL and ingestion_id. This way, we can replay an ingestion in case of failure. The url is generated during ingestion by concatenating the names of the parents creating the url.
The service for ScyllaDB contains the following methods:
- new(): Which initializes ScyllaDB connection and creates the service.
- get_node(): Gets a node by ID. It can get just the node or the nodes and relations.
- get_node_traversal(): To traverse a given node and get all the children.
- save_nodes(): Given a list of
DbNodeit will persist the nodes and relations using many threads set with the parallelism level. This property is passed when creating the service.
The scylladb.rs file contains the service and looks like this:
Let’s break it down. First we define the service:
This struct will contain these properties and we will implement the 3 methods described on this struct.
You may be wondering why we don’t define the service as a trait. The problem is that, at the time of writing, Rust does not support async traits, although an alpha feature is already implemented, so it should be available really soon. For more information see this thread. We use async methods when saving nodes.
The struct stores the max level of parallelism passed when creating the service and then holds references to the DB session and a few prepared statements. We use Arc since it is a thread safe reference counting to keep a reference to the heavy database session that can be shared safely among threads.
Then, we have the list of queries. After that, we have the service with the 3 main methods.
The new() method starts by defining the DC token aware policy for load balancing. Then, we create the session:
We use LZ4 compression.
Then, we read the schema from a file and create the schema in the database:
Finally, we initialize the prepare statements. This allows the ScyllaDB driver to perform query optimizations and improve the speed of the queries considerably.
We set a low consistency level for faster performance. You will have to choose the right consistency level for your use case.
To get a given node, we call the following method:
As mentioned, we can pass parameters to get just the node or also the tags and relations. We use the ScyllaDB Rust driver to map the rows to our model.
To get the node relations, we use the get_node_traversal method:
It can get the relations based on the direction (inbound/outbound) and also by specific relation type.
Finally, we have the save() method, which uses a shared session and many threads to concurrently write to the cluster distributing the load across all the CPUs in the cluster — making the ingestion process very fast.
We get a big list of nodes/relations and we insert them one by one concurrently, using many threads. A decent sized ScyllaDB cluster can handle thousands of requests per second. So, we can have hundreds of threads writing in parallel.
The code looks like:
We use a semaphore to limit the number of spawn tasks in Tokio to control the throughput and to make sure our application does not overload the cluster. This is passed as an environment variable, and it will depend on the cluster size.
For each item, we spawn a new task in Tokio that will run the prepared statement. You may be wondering if this will be very expensive. But, tasks in Tokio are green threads and are extremely lightweight, so they are very cheap to create and destroy. You may be also wondering why we do not use batching. The answer is that ScyllaDB prefers individual queries. The Rust driver is shard aware and can do many optimizations to distribute the load properly, making sure the cluster is utilized properly. If we use batching, it bypasses the token-aware load balancing and requests will be sent randomly (and will not be optimized).
We can see how, thanks to Rust and Tokio, we can utilize the power of ScyllaDB to have a very small application running many green threads executing thousands of queries in parallel. This approach is very highly performant and outperforms any SQL database by several orders of magnitude. This approach is also extremely faster than a data lake and not that expensive.
I hope this section was not too difficult. If you are not familiar with ScyllaDB or NoSQL, I recommend heading to the amazing ScyllaDB University which has many courses for free and will help you understand the concepts better. ScyllaDB or Cassandra are quite complex databases which require some time to master. And as always, check the repo for more details.
Main file with the REST API
Finally, we have arrived at the main file which contains the REST API to trigger the ingestion and to get or traverse a node.
You can find the main file here.
Let’s start with the main method where we initialize the application:
We use the Actix Web macro #[actix_web::main] to tag it as the main method which also enables the Tokio runtime.
We read the config, get the values and initialize the ScyllaDB service:
let db = ScyllaDbService::new(config.db_dc, config.db_url,
db_parallelism, config.schema_file).await;
Actix is fully asynchronous. Each request will be handled by a different task concurrently, using Tokio under the hood. To share the state safely between threads, we define the state as follows:
struct AppState {
db_svc: ScyllaDbService,
semaphore: Arc,
region: String
}
We store the ScyllaDB service there and the S3 region in the state object so it can be passed to the S3 read_file method. We also have a semaphore. This is used to block the Actix dispatcher in case we get too many ingest requests. Remember that in the ScyllaDB service, we have the max parallelism level to not overload the DB, but this setting is per request. If we get many requests, we may bring down the database so we need to also set a max level of concurrent requests. This way, we know the total maximum of in-flight requests that we can get at a given time and make sure they do not exceed the cluster’s maximum capacity.
At the end of the main method, we initialize the HTTP server and we pass the state:
The service method is used to add the handlers for each HTTP request. We have 3 of them.
Our model is defined as follows in the data/model.rs file:
A Node has the node attributes and the relations. This is the business model. It has the ScyllaDB implementation details where we merge nodes and relations into a single table. In here, they are clearly separated. The fact that a node has relations is clearly defined.
The Traversal Node is an object used for data traversal that tracks the depth of the tree.
Let’s move to the ingest HTTP POST request.
The request will look like this:
{
"ingestion_id": "test",
"files": [
"s3://rust-s3-scylladb/data_example.json"
]
}
We pass an ingestion id and a list of files to ingest. In the repo, I have included a small Python job that will read all the files from the bucket and call this end point for each file to parallelize the ingestion. You probably now understand why we need the semaphore to limit the number of requests running concurrently and block the requests. Just make sure that clients have a high timeout so the request does not time out since requests may be queued and blocked while others are running if the max level of parallelism is reached.
This is the POST method. We use Actix macros to define the request type:
We create one task per file in the request and then we wait for them to finish.
For each file, we execute the following:
We read the file from S3 using the read_file method previously described. As we mentioned in the data model, the file contains nodes and relations. First, we call process_relations to map the relations to our model.
Then we call process_nodes to flatten the hierarchy into a list of DbNodes to be persisted in the DB. We pass the relations since nodes will be created from the relations as well. We use recursion to flatten the nodes:
We generate urls as we go through the hierarchy.
This covers the ingestion process. Let’s check the get_by_id() method:
In this case, we use a get request where we pass the node ID to get. The Query Parameters are:
- get_tags: If true it will also return the tags.
- get_relations: If true it will also return the relations.
Finally, let’s see the traversal_by_id() method:
In this case, we want to traverse the graph in one direction and have the possibility of only traversing on relation type. You could add any other filter to search the graph.
Query Parameters:
max_depth:The maximumdepthyou want to explore.direction: The direction you want to explore. SelectOUTfor outbound relations leaving the node. SelectINfor inbound relations coming into the node. In a tree,INwould be to go from children to parent andOUTto go from parent to children.relation_type: Besides direction, you can add an additional filter by relation type. Use this to filter for specific relations.
The traversal of the tree is recursive like many other traversal algorithms. We will use breath first search (BFS), where we get all the children and then for each child we spawn a new task that will do the same thing recursively. For large graphs, this approach is very efficient since the traversal will be parallelized among many threads. And, since the Rust driver load balancer is token aware, the queries will be distributed across all the nodes and CPUs on the cluster — making this more efficient than Spark and many other tools, and making this a very efficient way to traverse large graphs. It can search 1 million nodes in less than one second. The main thing is that, thanks to the high parallelism, the deeper we go, the more threads we use to run the search in parallel. This means that it scales efficiently and going deeper does not make it exponentially slower — solving the scalability issues that SQL databases have.
This is how the recursive method is implemented:
As you know, in Rust the borrow checker must know the size of the different types at compile time. This is complex with recursion, so we need to introduce an indirection by using a BoxFuture.
Then, for each node, we get the value from the database which also includes the relation ids, that is, the children. For each of them, we spawn a new task that calls the function again with an increased depth. This is safe and checked by the borrow checker at compile time. We now have a safe and efficient way to traverse the graph. Note that doing this in a SQL database will be much more inefficient since it cannot handle so many individual concurrent requests, but ScyllaDB can handle this easily. If your graph depth is large, you may want to introduce a semaphore to limit the number of spawned tasks.
Run the Project
I’ve included a handy Makefile to use to run the project. First, you need to edit the .env file and enter your AWS credentials:
AWS_ACCESS_KEY_ID=
AWS_SECRET_ACCESS_KEY=
After this, upload the sample request to your S3 account in your bucket.
Then, start the ScyllaDB Docker container by running make db.
In a new terminal, run make run to start the application.
Check the logs and make sure everything is correct:
2023-01-01T12:49:50.103433Z INFO rust_s3_scylladb_svc::db::scylladb: Schema Created!
2023-01-01T12:49:50.103471Z INFO rust_s3_scylladb_svc::db::scylladb: ScyllaDbService: Schema created. Creating preprared query...
2023-01-01T12:49:50.107340Z INFO rust_s3_scylladb_svc::db::scylladb: ScyllaDbService: Parallelism 10
2023-01-01T12:49:50.107400Z INFO rust_s3_scylladb_svc: Starting server at http://localhost:3000/
2023-01-01T12:49:50.150189Z INFO actix_server::builder: Starting 16 workers
2023-01-01T12:49:50.150300Z INFO actix_server::server: Actix runtime found; starting in Actix runtime
Now use your favorite REST tool such as Postman to trigger the ingestion. Send a POST request to http://localhost:3000/ingest:
{
"ingestion_id": "test",
"files": [
"s3://rust-s3-scylladb/data_example.json"
]
}
Use your bucket name instead. This will trigger the ingestion. Check the logs in the app terminal:
2023-01-01T12:55:49.225769Z INFO rust_s3_scylladb_svc: Ingest Request: ["s3://rust-s3-scylladb/data_example.json"]
2023-01-01T12:55:49.225879Z INFO rust_s3_scylladb_svc: Processing File s3://rust-s3-scylladb/data_example.json for provider test. Reading file...
2023-01-01T12:55:49.225897Z INFO rust_s3_scylladb_svc::s3::s3: Reading file: s3://rust-s3-scylladb/data_example.json
2023-01-01T12:55:49.225990Z INFO rust_s3_scylladb_svc::s3::s3: bucket creation. Took 81.86µs
2023-01-01T12:55:49.311423Z INFO rust_s3_scylladb_svc::s3::s3: read_file. Took 85.47ms
2023-01-01T12:55:49.311500Z INFO rust_s3_scylladb_svc: File Read. Processing Relations..
2023-01-01T12:55:49.311689Z INFO rust_s3_scylladb_svc: process_relations Took 164.45µs
2023-01-01T12:55:49.311716Z INFO rust_s3_scylladb_svc: Relations processed, size: 4. Persisting Nodes..
2023-01-01T12:55:49.311729Z INFO rust_s3_scylladb_svc: process_nodes: test
2023-01-01T12:55:49.312257Z INFO rust_s3_scylladb_svc: process_nodes Took 512.67µs
2023-01-01T12:55:49.312290Z INFO rust_s3_scylladb_svc: Nodes processed, nodes size: 52.Persisting...
2023-01-01T12:55:49.312308Z INFO rust_s3_scylladb_svc::db::scylladb: ScyllaDbService: save_nodes: Saving Nodes...
2023-01-01T12:55:49.338631Z INFO rust_s3_scylladb_svc::db::scylladb: ScyllaDbService: save_nodes: Waiting for 52 tasks to complete...
2023-01-01T12:55:49.356408Z INFO rust_s3_scylladb_svc::db::scylladb: ScyllaDbService: save_nodes: 52 save nodes tasks completed. ERRORS: 0. Took: 44.07ms
2023-01-01T12:55:49.356452Z INFO rust_s3_scylladb_svc: Nodes Persisted!
2023-01-01T12:55:49.356461Z INFO rust_s3_scylladb_svc: File s3://rust-s3-scylladb/data_example.json processed. Took 130.57ms
2023-01-01T12:55:49.356565Z INFO rust_s3_scylladb_svc: Ingestion Time: 130.74ms
Let’s verify that it worked properly. Let’s get a node by ID. Run the following request: GET http://localhost:3000/node/1861ccad-30a8-5e29-b4ac-a00b7239676e?get_tags=true&get_relations=true
You should get the response with the node details:
The outbound field tells you the relation direction. If true, it means that it is an outbound direction (in our case, from the parent to the children). You can also see how the URL is generated. This is the second level of the hierarchy.
Now let’s traverse the graph from the root node to get the children. Run GET http://localhost:3000/traversal/761ce7ea-f3c2-5d86-83e3-6c33342b888e?direction=OUT&relation_type=ISCHILD&max_depth=9
Now you can see the depth of the tree and how we use BFS to traverse the graph. This is executed using multiple threads and, in production, it will be executed across many nodes in the cluster.
And finally, we are done!
We have built a production-grade application that is extremely fast and can handle billions of items thanks to the combined power of Rust and ScyllaDB. We have learned how to interact with S3 and ScyllaDB and create really fast REST APIs in Rust — and, we followed cloud native best practices.
However, we still need to improve error handling, add test cases and make it production ready. Feel free to adapt this to your needs and use it as a reference. For example, you may have a similar use case but with another data model or even another database, but you can still reuse the key components.
Conclusion
The goal of this article is to showcase the power of Rust with a real world use case using best practices. The idea is that you can take this project and use it as a blueprint for your next Rust project. This will help you bootstrap your next project to easily get started. You can reuse some of the components and modify others.
The goal is not to teach you Rust; there are many resources available for this. Check the links below for some of these resources.
UPDATE: I’m currently in Tanzania helping a local school, I’ve created a GoFundMe Campaign to help the children, to donate follow this link, every little helps!
Subscribe to my Medium page to get notified when I publish an article and join Medium.com to access millions of articles!
Rust Resources





